NVIDIA AI Researchers Propose ‘MinVIS,’ A Minimal Video Instance Segmentation (VIS) Framework That Achieves SOTA Performance With Neither Video-Based Architectures Nor Training Procedures
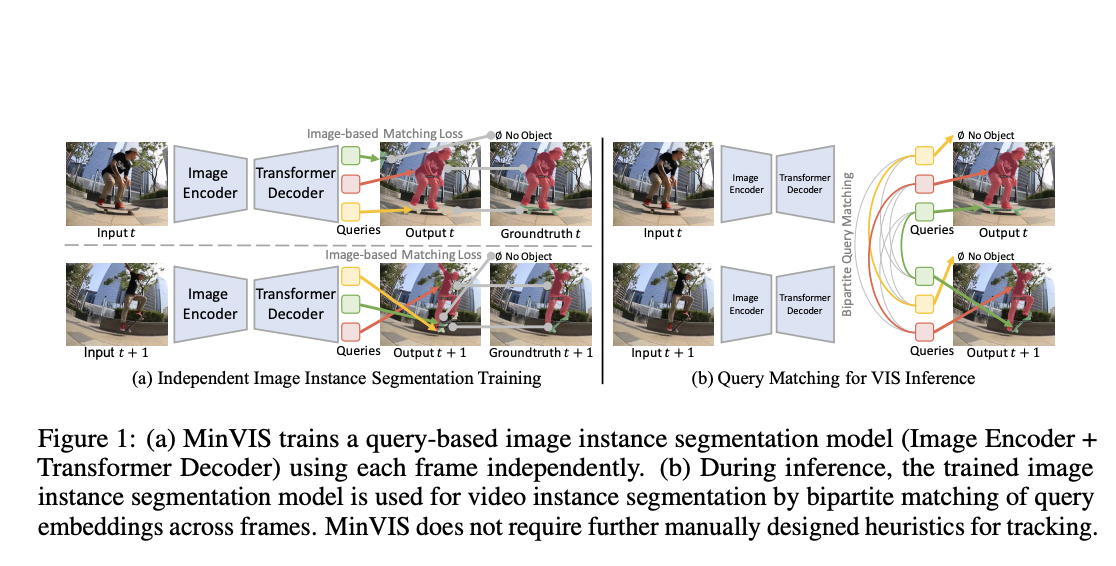
The goal of video instance segmentation (VIS) is to recognize, classify, and track object instances in the video. VIS is substantially more complex than instance segmentation of an image because it must reliably track object instances across a complete video. MinVIS, a minimum video instance segmentation (VIS) framework, is proposed in this approach by just training a query-based image instance segmentation model. The segmented instances are then linked together using bipartite matching of the related queries. The main finding of this method is that instances can be tracked without the usage of manually created heuristics because queries are trained to be temporally consistent and discriminative between intra-frame object occurrences.
Figure 1 showcases a summary of MinVIS’s training and inference.
The proposed method uses independent frames for training, making it simple to implement in situations where there are only sparse annotations for image instance segmentation. MinVIS is built on query-based transformer architectures for detecting and extracting segmentation instances. It has three primary sections. The encoder is utilized to extract features from input images. The transformer decoder updates the query embeddings iteratively using the image encoder’s output. Prediction heads use the final query embeddings to forecast desired outputs.
In MinVis, a post-processing procedure is conducted to connect instances after the segmented instances have been extracted temporally. The proposed method is less susceptible to occlusions since a query expresses each instance without a spatial extent. This method does not require heuristics to handle the creation and destruction of object instances. When an object instance’s embedding matches a null query, it is considered destruction of that particular instance. If the matching query embeddings were null prior to the object instance’s actual birth, the birth of an instance is handled successfully.
Three datasets are used to analyze MinVIS: Occluded VIS (OVIS), YouTube-VIS 2019, and YouTube-VIS 2021. The YouTube-VIS datasets and OVIS contain 40 and 25 object classes, respectively. For training, validation, and testing, YouTube-VIS 2019 includes 2238, 302, and 343 videos, respectively, YouTube-VIS 2021 includes 2238, 302, and 343 videos, respectively, and OVIS includes 607/140/154 videos, respectively. OVIS has a higher rate of occlusion than YouTube-VIS. As an evaluation metric, average precision and average recall are utilized. This method focuses on outcomes and employs backbones such as widely used ResNet50 and Swin-L, which have efficient performance. The hyperparameters utilized in this approach are the same as the Mask2Former-VIS approach. For training, 6k and 10k iterations are used for YouTube-VIS datasets and OVIS, respectively.
For the YouTube-VIS 2019 dataset, the suggested MinVIS technique obtains the highest AP and the majority of other metrics for both ResNet-50 and Swin-L backbones. The outcomes of the complex dataset YouTube-VIS 2021 demonstrate better performance compared to YouTube-VIS 2019. ResNet- 50 and Swin-L outperform significantly for all measures even without a superior backbone like TeViT and more training data like SeqFormer. MinVIS surpasses the previous state-of-the-art TeViT with MsgShifT backbone by 7.6% AP on the OVIS dataset. Also, on the same dataset, with Swin-L as its backbone, MinVIS performs 10.5% AP better than the previous best performance, MaskTrack R-CNN*+SWA.
In the ablation study, this approach is compared with the manually designed heuristics technique, which showcases a drop of 3% AP on both YouTube-VIS 2019 and 2021 datasets. Additionally, due to high occlusions, the AP on the OVIS dataset drops by 7.7%.
Hence, this study proposes the minimal video instance segmentation (MinVIS) approach, which does not need video-based architecture and does not require training procedures. Its image-based approach makes learning easier and improves performance. It outperforms state-of-the-art approaches by 10% AP on the complex OVIS dataset. This method does not require simultaneous processing of the entire video because the inference is made online. As a result, it offers the valuable benefits of minimizing labeling costs and memory needs without compromising performance.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'MinVIS: A Minimal Video Instance Segmentation Framework without Video-based Training'. All Credit For This Research Goes To Researchers on This Project. Check out the Preprint/Under review paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Priyanka Israni is currently pursuing PhD at Gujarat Technological University, Ahmedabad, India. Her interest area lies in medical image processing, machine learning, deep learning, data analysis and computer vision. She has 8 years of teaching experience to engineering graduates and postgraduates.
Credit: Source link
Comments are closed.