Researchers Present A Survey Report on Using 100+ Transformer-based Methods in Computer Vision for Different 3D Vision Tasks
Understanding sceneries and objects in three-dimensional space are critical in computer vision. Autonomous driving, robotics, remote sensing, medical treatment, augmented reality, and the design industry is just a few fields in which 3D vision is crucial. Numerous factors, including the introduction of numerous large-scale 3D geometry datasets that were gathered and labeled in 3D, the development of various 3D capture sensors, such as LiDAR and RGB-D sensors, and advancements in 3D deep learning techniques, have all contributed to an increase in interest in the 3D field. Deep convolution neural networks are a common component of 3D deep learning systems (CNNs). It allows navigating and modifying the actual world and enables a condensed depiction of connections.
Nevertheless, in several areas, including natural language processing (NLP) and 2D image processing, transformer-based designs that employ the attention mechanism have emerged as a serious rival to such approaches. The attention mechanism works globally and may thus encode long-range relationships, in contrast to convolution operators’ constrained receptive fields and translation equivariance qualities. This allows attention-based algorithms to learn richer feature representations. Numerous 3D vision techniques have lately integrated transformers in the model designs due to the success of transformer-based architectures in the image domain. For the majority of popular 3D vision applications, several designs have been suggested as a solution. The capacity of the transformer to gather long-range information and develop task-specific inductive biases has allowed it to replace or enhance prior learning techniques in 3D.
Given that transformers are becoming increasingly interested in 3D vision (Fig. 1, left), it is crucial to conduct a survey that provides a comprehensive overview of the current techniques. We examine approaches for 3D vision tasks, including classification, segmentation, detection, completion, posture estimation, and others, in this survey (Fig. 1, right). We emphasize the 3D vision transformer design decisions that enable it to interpret data with different 3D representations. We go through each application’s main characteristics and contributions of the suggested transformer-based techniques. In order to determine how competitive the transformer integration is in this industry, we compare their performance to that of other approaches on the most popular 3Ddatasets/benchmarks.
We observe that deep learning techniques for 3D vision have been the subject of several studies. Numerous papers that have been published offer an overview of techniques for processing 3D data as part of these surveys. Other research focuses on particular applications of 3D vision, such as segmentation, classification, or detection. Additionally, some research focuses on a particular data input sensor, while others study 3D deep learning approaches from a representation standpoint. The attention to transformer-based designs is still lacking because most surveys were written before the current popularity of the transformer architecture. Numerous works that examine these techniques have appeared due to the abundance of contemporary vision techniques that depend on the attention mechanism and the transformer architecture. Some of these studies examine vision transformers broadly, while others concentrate on a particular feature, like effectiveness, or particular use, such as video or medical imaging.
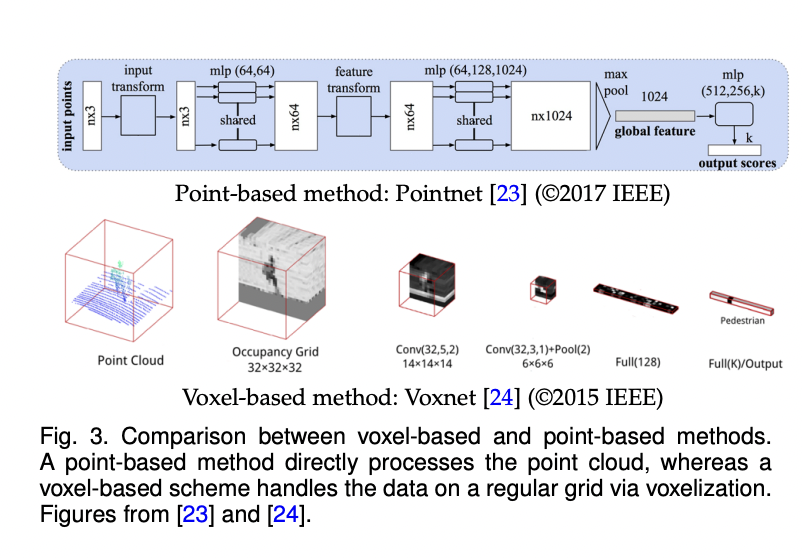
Transformers in 3D vision applications require specific consideration because of the distinctions between 2D and 3D data encoding and processing. The examination contains techniques using 3D inputs or outputs and the transformer architecture. Numerous RGB-D interior sensors, LiDAR outdoor, and specialist medical sensors can be used to collect 3D data. We cover techniques that take dense 3D grids or point clouds as input. Taking photos at various slices, which is typical in medical imaging, can also result in the creation of a dense 3D grid. Additionally, representative techniques that use the transformer structures on different types of input data, including multi-view pictures or images taken from a birds-eye perspective, are also presented.
This github repo contains multiple papers on 3D vision that utilize transformers. https://github.com/lahoud/3d-vision-transformers
This Article is written as a research summary article by Marktechpost Staff based on the research paper '3D Vision with Transformers: A Survey'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Content Writing Consultant Intern at Marktechpost.
Credit: Source link
Comments are closed.