Researchers at the University of Michigan Develop Zeus: A Machine Learning-Based Framework for Optimizing GPU Energy Consumption of Deep Neural Networks DNNs Training
Deep neural networks (DNNs) have become widely used in recent years across a variety of data-driven application domains, including speech recognition, natural language processing, computer vision, and personalized recommendations. DNN models are typically trained in clusters of highly parallel and ever more powerful GPUs in order to handle such growth effectively.
But as computing becomes more popular, energy demand rises as a result. For instance, the 1,287 megawatt-hour (MWh) required to train the GPT-3 model is equal to 120 years’ worth of typical U.S. family electricity use. The demand for electricity for AI is rising, according to Meta, despite a reduction in operating power footprint of 28.5%. However, the majority of the existing DNN training literature ignores energy efficiency.
Common DNN training performance enhancement techniques can use energy inefficiently. For instance, a lot of recent papers recommend greater batch sizes for faster training rates. Maximizing raw throughput, though, might result in less energy efficiency. Similar to how contemporary GPUs permit the Equal contribution setup of a power limit, existing solutions frequently ignore it. Four generations of NVIDIA GPUs have been analyzed, and the results demonstrate that none of them are completely power proportional, and using the greatest amount of power has diminishing returns.
Unfortunately, saving energy doesn’t come completely free. For a given target accuracy, there is a trade-off between energy consumption and training time; one must be sacrificed while the other is optimized. Two noteworthy events are highlighted by the description of the energy-time Pareto frontier. First, compared to using the maximum batch size and GPU power limit naively, all Pareto-optimal setups for a particular training project offer varying degrees of energy reductions. Second, as training time is increased, there is frequently a non-linear relationship between the amount of energy reduction and consumption.
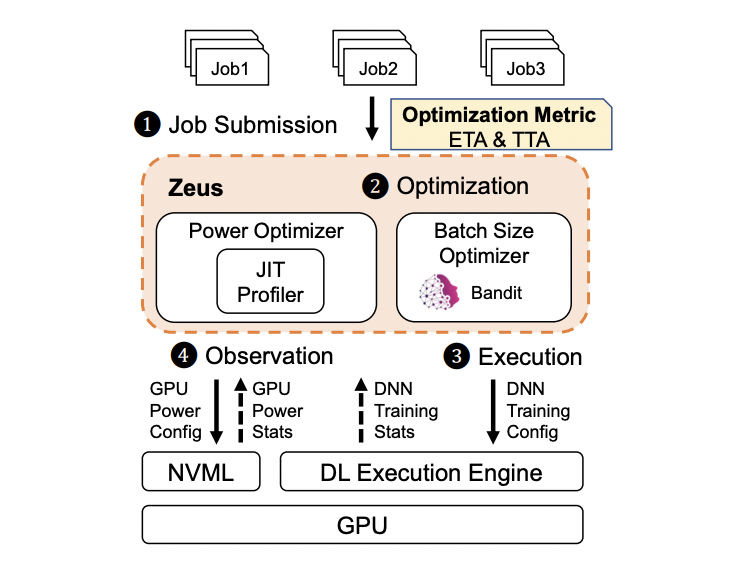
Researchers from the University of Michigan have offered Zeus as a solution to this issue in a publication. The batch size and GPU power limit are automatically configured by Zeus, a plug-in optimization framework, to reduce total energy consumption and training time for DNN training operations. Zeus takes into account both job- and GPU-related configurations, in contrast to several recent studies that solely take into account GPU-specific configurations.
There is no need for per-job offline profiling or training of prediction models, which can be prohibitively expensive in big clusters with heterogeneous hardware and variable workloads. Zeus, on the other hand, adopts an online exploration and exploitation strategy that is suited to the features of DNN training workflows. Models must be periodically retrained when new data enters the pipeline, which manifests itself as repeatable tasks on production clusters. Zeus makes use of this fact to automatically investigate various setups, measure any benefits or losses, and then modify its activities as needed.
Due to sources of uncertainty in DNN training, designing such a solution is difficult. First, even when the same job is done on the same GPU with the same configuration, the energy expenditure of a training job varies. This is because randomness introduced by model initialization and data loading causes variation in end-to-end training duration to achieve a particular model quality. Second, DNN models and GPUs both have varied topologies and distinctive energy properties.
As a result, data gathered from offline energy consumption profiling of certain models and GPUs do not generalize. To do this, researchers created a just-in-time (JIT) energy profiler that, when activated by an online training task, quickly and effectively records its energy properties. Zeus also uses a Multi-Armed Bandit with Thompson Sampling, enabling the group to capture the stochastic nature of DNN training and optimize in the face of uncertainty.
Test results on a variety of workloads, including speech recognition, picture classification, NLP, and recommendation tasks, revealed that Zeus cuts training time by 60.6% and energy usage by 15.3%-75.8% when compared to only choosing the maximum batch size and maximum GPU power limit. Zeus can effectively withstand data drift and quickly converge on ideal settings. The advantages of Zeus also apply in multi-GPU configurations.
Conclusion
In this study, University of Michigan researchers aimed to comprehend and improve the energy usage of DNN training on GPUs. The researchers determined the trade-off between training time and energy use and showed how routine behaviors might result in wasteful energy use. Zeus is an online system that determines the Pareto frontier for recurrent DNN training projects. It enables users to move through it by automatically adjusting the batch size and GPU power limit of their jobs. Zeus continuously adapts to dynamic workload changes like data drift, outperforming the state-of-the-art in terms of energy consumption for a variety of workloads and real cluster traces. Zeus, according to researchers, will encourage the community to prioritize energy as a resource in DNN improvement.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Zeus: Understanding and Optimizing GPU Energy Consumption of DNN Training'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Nitish is a computer science undergraduate with keen interest in the field of deep learning. He has done various projects related to deep learning and closely follows the new advancements taking place in the field.
Credit: Source link
Comments are closed.