Salesforce AI Propose A Novel Framework That Trains An Open Vocabulary Object Detector With Pseudo Bounding-Box Labels Generated From Large-Scale Image-Caption Pairs
One of the main functions of computer vision is object detection, which continues to draw a lot of academic attention. These algorithms give excellent results when trained on a pre-defined set of item categories that have been labeled in a large number of training photos. However, this is true only for a few object categories. This is because most detection techniques depend on supervision in the form of instance-level bounding box annotations, demanding human labeling efforts to create training datasets. Additionally, numerous bounding boxes in images for the new object category must be annotated when trying to detect things from a new category.
Zero-shot object detection and open vocabulary object detection are recent efforts to lessen the necessity for annotating new item categories. Using correlations between the base and novel categories, object detection models are trained on base item categories with bounding box annotations supplied by humans in zero-shot detection methods to enhance their generalization ability on novel object categories. These techniques can partially reduce the need for substantial volumes of data with human labels. On top of these approaches, open vocabulary object detection uses image captions to enhance the effectiveness of novel object detection.
Due to the expensive cost of gathering extensive bounding-box annotations of numerous items, the promise of the current zero-shot and open vocabulary techniques is limited by the small size of the base category set at training.
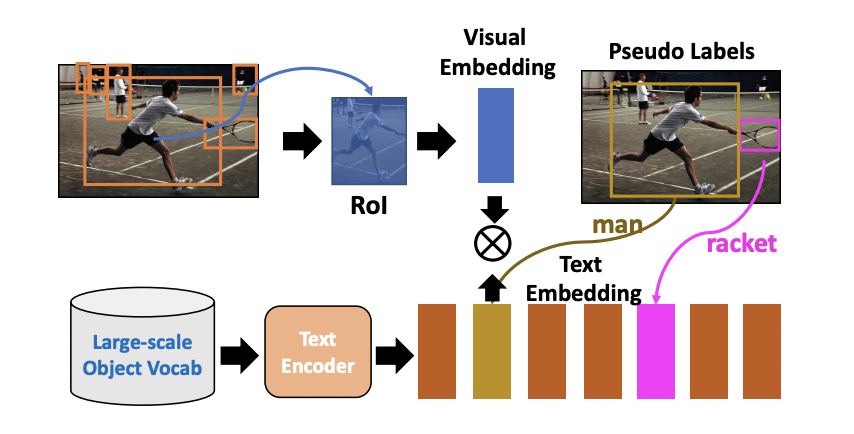
A new Salesforce work improves open vocabulary item detection using pseudo-bounding-box annotations produced from large-scale image caption pairings. To accomplish this, the team uses the localization capabilities of pre-trained vision-language models. To automatically acquire pseudo box annotations of a variety of items using existing image caption datasets, they developed a pseudo-bounding-box label generating approach. An activation map in the picture corresponds to an object of interest specified in the caption given a pre-trained vision-language model and an image-caption pair. It is then transformed into a pseudo-bounding-box label for the appropriate object category. After that, an open vocabulary detector is directly trained based on pseudo labels.
The richness and diversity of the training data, including the number of training object categories, can be greatly enhanced because the procedure for creating pseudo-bounding-box labels is automated without any operator intervention.
On the widely used datasets COCO, PASCAL VOC, Objects365, and LVIS, the researchers compare the performance of their approach with the state-of-the-art (SOTA) zero-shot and open vocabulary object detectors. According to the results, when both approaches are calibrated with COCO base categories, the method outperforms the best open vocabulary identification method on novel items on COCO by 8% mAP. They assess how well the strategy generalizes to different datasets as well. The solution outperforms existing approaches in this environment by 6.3%, 2.3%, and 2.8% on PASCAL VOC, Objects365, and LVIS, respectively.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Open Vocabulary Object Detection with Pseudo Bounding-Box Labels'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, github link and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.