Latest Computer Vision Research At Microsoft Explains How This Proposed Method Adapts The Pretrained Language Image Models To Video Recognition
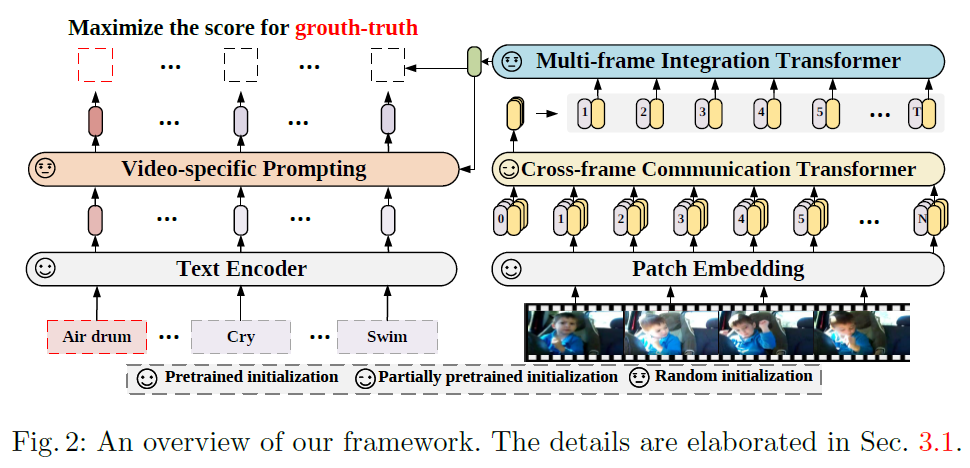
Numerous vision applications heavily rely on video recognition, including autonomous driving, sports video analysis, and microvideo recommendation. A temporal video model is showcased in this research to make use of the temporal information in videos that consists of two essential parts: a multi-frame integration transformer and a cross-frame communication transformer. Additionally, the text encoder is pretrained in language image models and expanded with a video-specific prompting scheme to acquire discriminative text representation for a video.
This research utilizes text as the supervision because it contains more semantic information. Instead of starting from scratch, this approach builds on prior language-image models and expands them with video temporal modeling and video-adaptive textual prompts. An overview of the proposed framework is showcased in the figure below.
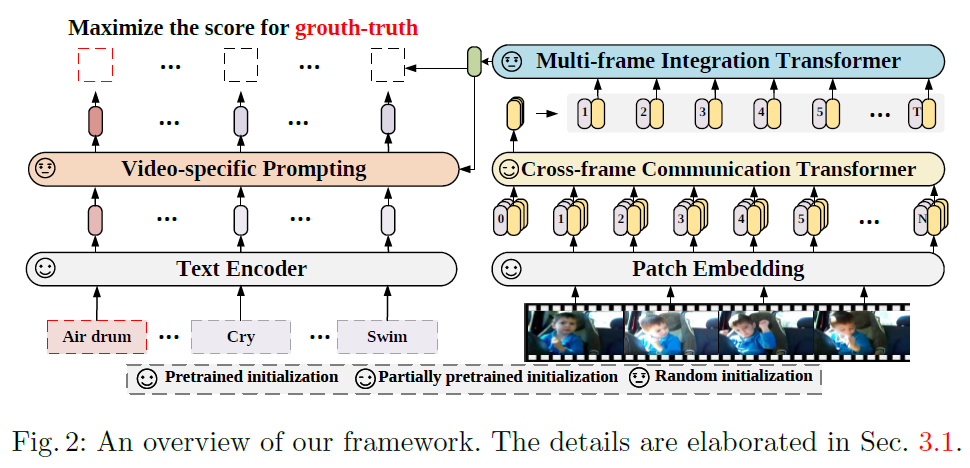
The cross-frame transformer accepts raw frames as input and generates a frame-level representation using a pretrained language-image model while allowing an exchange of information among frames. After that, the multi-frame integration transformer combines the frame-level representations and outputs video features. This research suggests a learnable prompting method to create textual representation automatically. Each block of the video-specific prompting module comprises a multi-head self-attention (MHSA) network accompanied by a feed-forward network to learn the prompts. The experiments of this work are carried out in various settings, including zero-shot, few-shot, and fully-supervised.
In fully supervised experiments, all models were trained on 32 NVIDIA 32G V100 GPUs. The proposed approach outperforms other cutting-edge approaches compared to methods trained on ImageNet-21k, web-scale image pretraining, and ActionCLIP. The efficient results are primarily due to two factors: 1) The cross-frame attention model can effectively model video frame temporal dependencies. 2) The successful transfer of the joint language-image representation to videos demonstrates its strong generalization capability for recognition.
In zero-shot video recognition, the categories in the test set are hidden from the model during training, which makes it very challenging. X-CLIP-B/16 is pretrained on Kinetics-400 with 32 frames for Zero-shot Experiments. In zero-shot learning, this work outperforms other approaches on HMDB-51, Kinetics-600, and UCF-101benchmarks.
In the few-shot approach, this work is compared to some representative methods, namely TimeSformer, TSM, and Swin. It has been observed that the difference in performance between the proposed method and others gets smaller as the number of samples increases. It demonstrates that increasing the amount of data can reduce over-fitting in other techniques.
In ablation studies, for classification purposes, a straightforward baseline called CLIP-Mean is created by averaging the CLIP features across all video frames. It has been discovered that selecting the original transformer in CLIP with the proposed cross-frame communication mechanism, followed by the addition of a 1-layer multi-frame integration transformer (MIT), can improve accuracy even further. The performance in a fully-supervised setting can be improved by fine-tuning the image encoder, while the CUDA memory can be reduced by freezing the text encoder at the expense of a slight drop in performance. For the few-shot setting, it has been observed that fine-tuning the text encoder gets the top-2 results as overfitting is less due to few samples. Fine-tuning the image and text encoders yields the best results for zero-shot settings.
Text information can provide measurable gains in few-shot and fully-supervised experiments. A randomly initialized fully-connected layer is used as the classification head in place of the text encoder to assess the influence of the text. However, the model cannot adapt to zero-shot settings because there is no data to initialize the head. This work compares sparse sampling and dense sampling. Sparse sampling outperforms dense sampling in training and inference, regardless of the number of frames and views used. The results show that the multimodality models used with sparse sampling are robust to the number of views.
Hence, this research employs a straightforward method for adapting pretrained language image models for video recognition. A cross-frame attention mechanism is proposed, allowing the direct exchange of information between frames to capture the temporal information. A video-specific prompting technique is developed to produce instance-level discriminative textual representation. Extensive experiments demonstrate the effectiveness of this work under three different learning scenarios.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Expanding Language-Image Pretrained Models for General Video Recognition'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Priyanka Israni is currently pursuing PhD at Gujarat Technological University, Ahmedabad, India. Her interest area lies in medical image processing, machine learning, deep learning, data analysis and computer vision. She has 8 years of teaching experience to engineering graduates and postgraduates.
Credit: Source link
Comments are closed.