A Latest Machine Learning Research Brings A Novel Explanation For Performance Deterioration of Deeper Graph Neural Networks GNNs
An essential tool for analyzing graph data, such as social networks, transportation networks, molecular networks, biological networks, financial transaction networks, academic citation networks, and knowledge graphs, is the graph neural network (GNN). By utilizing deep learning methodologies on graphs, GNNs have gained popularity with cutting-edge performance. One of them, message-passing neural networks (MPNN), computes node embeddings using message-passing layers. Graph convolutional neural networks (GNN), GraphSAGE, graph attention networks, and gated graph neural networks are a few examples of MPNNs.
The message passing layer in a GNN framework gathers information from each node’s local neighbors and transforms it via an activation function into the embedding, much like a standard multi-layer perceptron (MLP) in deep learning. Incorporating additional reaches of the graph, a node embedding can aggregate data over N hop neighbors in the form of N hidden message-passing layers.
Even while non-graph neural networks frequently benefit from more layers, GNNs typically perform best with just 2 to 4 hop neighbors or 2 to 4 hidden layers. On the other hand, deep stacking, or using more layers, can significantly reduce the performance of GNNs. The over-smoothing is one theory for why this is happening. The representation of the nodes will be undetectable by continually applying graph convolution over numerous hidden layers. As a result, over-smoothing puts the effectiveness of deep GNNs in danger.
The under-reaching is another justification. Information propagation across far-flung nodes in the network becomes challenging because it is prone to bottlenecks when GNNs aggregate messages across lengthy pathways. Because of this, GNNs struggle to anticipate outcomes for tasks requiring remote engagement.
These restrictions have been the subject of numerous campaigns. It was suggested that DropEdge and DropNode randomly remove a specific number of edges or nodes from the input graph at each training epoch to address the over-smoothing. These techniques are comparable to Dropout, which prevents overfitting by randomly removing hidden neurons from neural networks. On the other hand, the original graph can be supplemented with virtual edges, super nodes, or short-cut edges to address the under-reaching. All of the aforementioned techniques do not, however, take into account adding or removing based on the graph’s structural information. Instead, a purely random selection is used to determine which nodes or edges should be added or removed.
However, the information present in the original network is lost using this method. Consider the case of a source node that is linked to numerous nearby destination nodes and whose self-loop has an identical weight to the neighboring non-loop edge. This may understate the significance of this node. However, since both edges in the basic graph have equal weights, ordinary GNNs treat them equally. Because of this, the ability of message-passing layers to collect structural information in GNNs may be diminished.
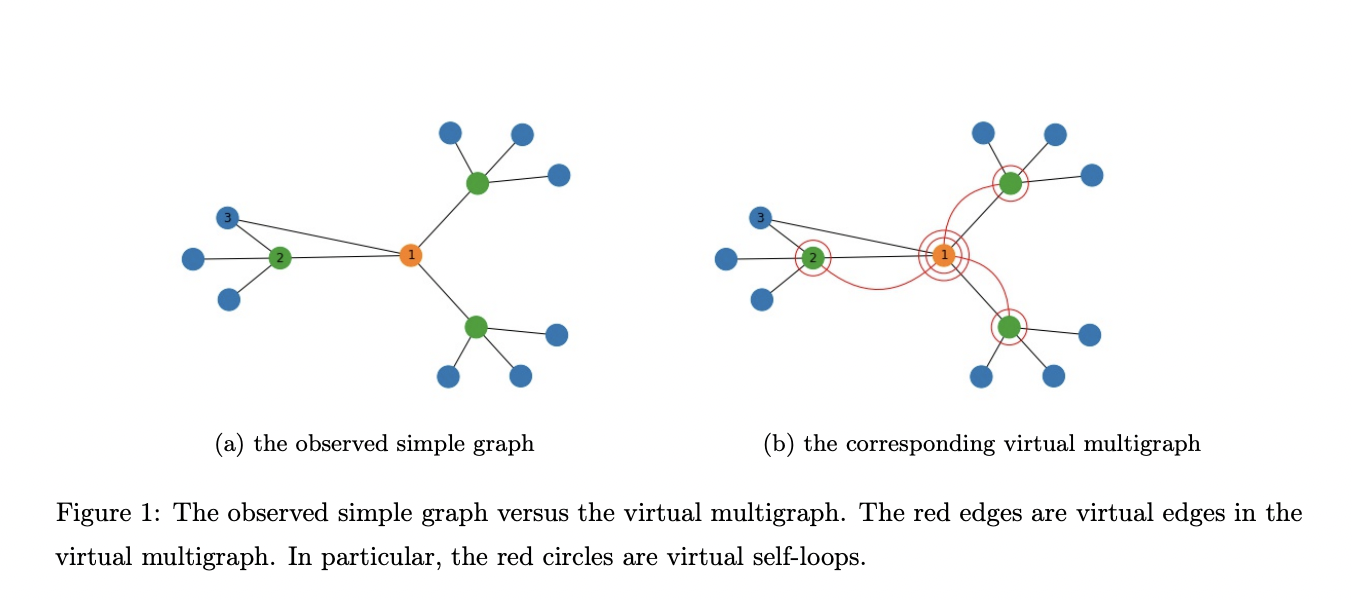
In a recently published publication, scientists from JP Morgan Chase Bank suggested an edge-enhanced graph neural network (EEGNN) that combines edge structure information in the message-passing layer to address this problem. The team first posits that a virtual multigraph with self-loops and numerous edges between nodes exists beneath the observed graph model and that the observed graph model may be thought of as a transformation of the virtual multigraph. The Dirichlet mixture Poisson graph model, a Bayesian nonparametric model, was proposed by academics to construct the virtual multigraph that can capture the edge structural information.
Assigning a sociability parameter to each node allows for the modeling of the interactions between nodes. Following that, a Poisson distribution is used to generate the edge counts, with the Poisson rate being the result of the sociability parameters of the nodes in the two ends. Finally, using the EEGNN architecture, researchers may then substitute the virtual multigraph for the observed graph in a GNN. In this architecture, message-passing layers might then give weights based on the significance of the edges, transferring information between nodes in a more logical way. The trials on several real datasets showed that EEGNN could boost the effectiveness of standard GNN techniques.
Conclusion
The performance decline of deeper GNNs was recently explained by JP Morgan Chase Bank researchers using a unique theory called mis-simplification. A Bayesian nonparametric graph model called DMPGM and accompanying MCMC inference framework were proposed by researchers. The researchers created a virtual graph by replacing the original simple graph with the data from DMPGM, then utilized the virtual graph to aggregate the data from the original graph. The research lays a new foundation for using data obtained from statistical graph modeling to boost GNN performance. EEGNN merely adds virtual edges to the observed graph; it does not remove edges based on structural information, which is one of the proposal’s limitations. The creation of a framework that enables the simultaneous addition and removal of edges with structural information is left to future research.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'EEGNN: Edge Enhanced Graph Neural Networks'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Nitish is a computer science undergraduate with keen interest in the field of deep learning. He has done various projects related to deep learning and closely follows the new advancements taking place in the field.
Credit: Source link
Comments are closed.