NVIDIA and Tel-Aviv University Researchers Propose a Computer Vision Method based on Textual Inversion to Insert New Concepts into Pre-Trained Text-to-Image Models
In the last few years, text-to-image has become one of the most studied topics in the Computer Vision world, resulting in models such as OpenAI’s DALL-E2 and Google’s Imagen, which obtained unbelievable results. These technologies are slowly becoming a medium for producing art and design content. Nevertheless, the controllability of these tools depends not only on the quality of the models but also on the ability of the user to express the concept generated. This could be a huge limit, as it is not always easy to understand the intrinsic behavior of the network, and introducing new ideas is a fundamental task in this context.
To solve this limitation, different solutions have been proposed: from retraining a model with an expanded dataset, which is insanely costly, to training transformation modules to adapt the output when new concepts arise. However, these approaches are still sub-optimal. For this reason, researchers from NVIDIA and Tel-Aviv University proposed a new model based on textual inversion to overcome these limitations and guide the learning of new concepts relying solely on a minimal number of samples.
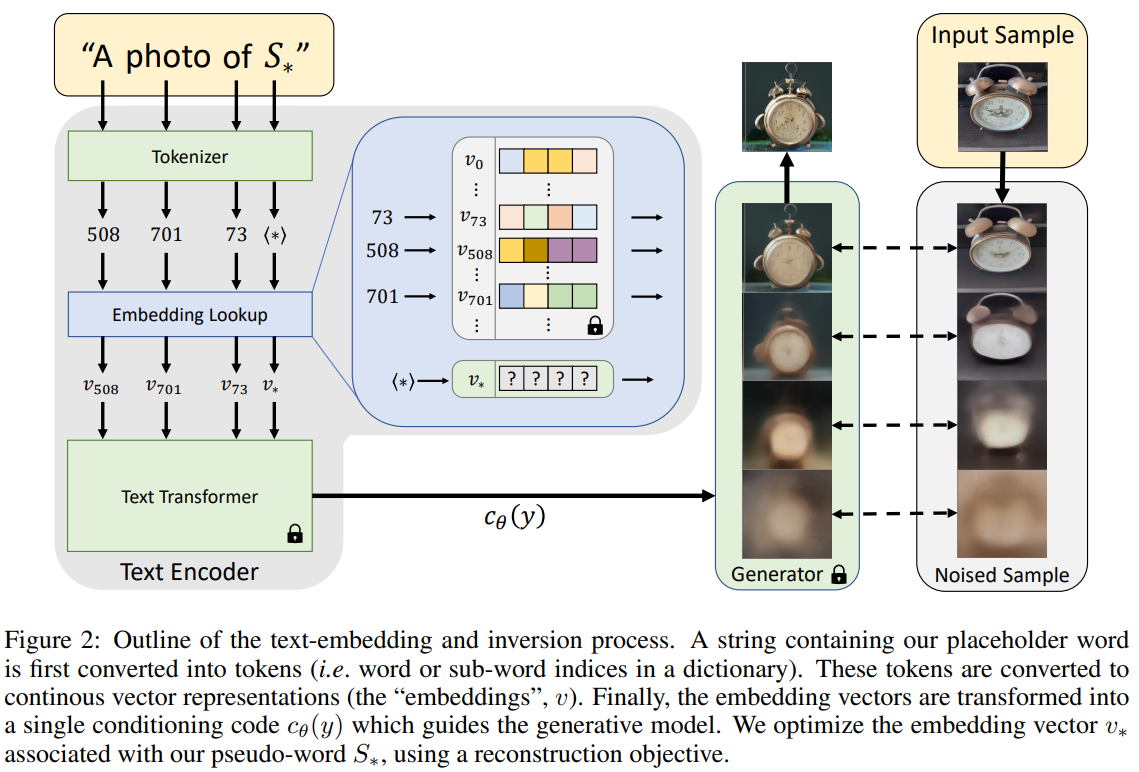
The authors focused on the text embedding phase of pre-trained models. In a standard text-to-image model, the input strings are first converted to a set of tokens, which are indexes on some pre-defined dictionary, and subsequently embedded in a vector. The idea is to find a new embedding vector for each new concept we want to introduce.
These new vectors are represented with pseudo-words (S* in the paper) which are treated as any other words to compose queries, for example, “a photograph of S* on the beach”, where S* is a new concept that we want the model to learn. To find these pseudo-words, the authors implemented textual inversion. Briefly, given a pre-trained model and a small set of images, we guide the model to find a single pseudo-words, such as sentences as “a photo of S*” will bring to the reconstruction of all the images in the small set.
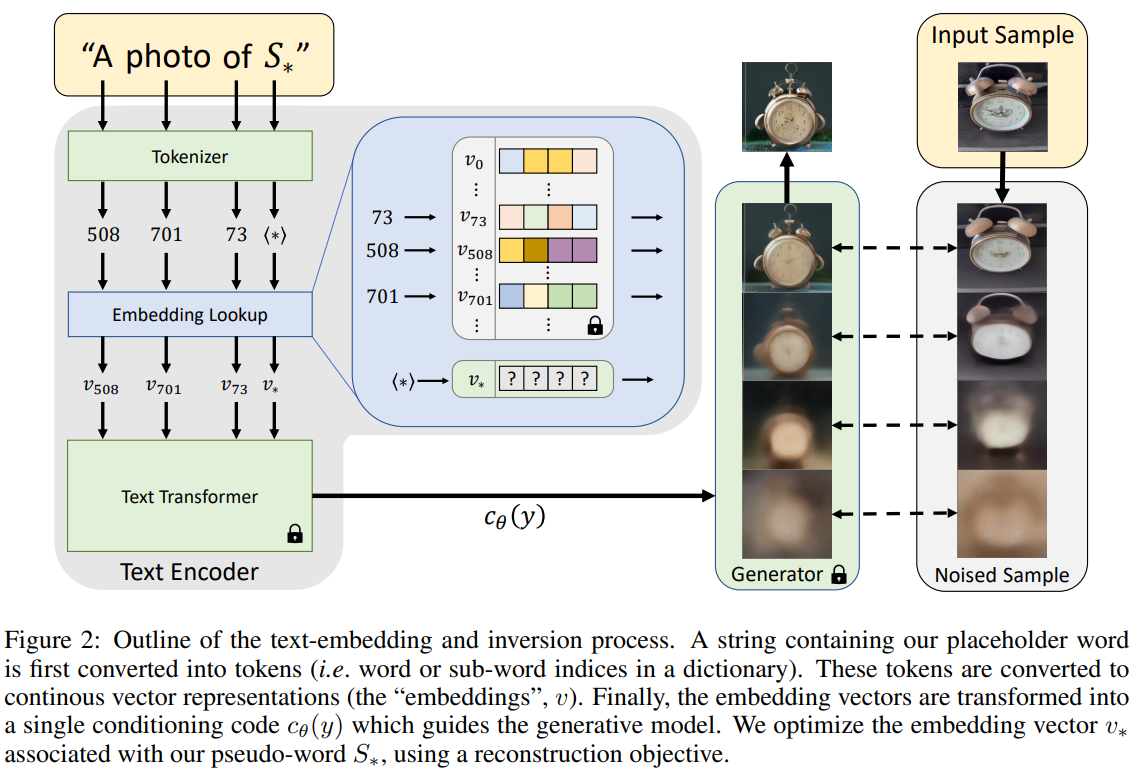
Method
The proposed technique is applied to the family of models named Latent Diffusion Models, which relies on the latent representation of images for the diffusion process and not on the original images. More clearly, in the first step, an autoencoder is trained on a large set of images: the encoder learns how to map images to latent code, and the decoder how to reconstruct images from latent code. In the second step, a diffusion model is trained in the latent space and can be conditioned by, for example, text or segmentation mask.
To add the embedding of new concepts to this family of pre-trained models, the authors used a small set of images (3 to 5), which describe the target concept with multiple settings, such as varied backgrounds or poses. To insert conditioning on text, they utilized a list of prompts such as “a rendering of an S∗” or “a cropped photo of the S∗” (the complete list can be found in the supplementary material of the paper).
Results
The authors qualitatively evaluate the proposed model in different applications. First of all, its ability to synthesize text-guided content. As it is possible to see from the above image, the context is learned with high confidence from the model, even if the set of images is very limited.
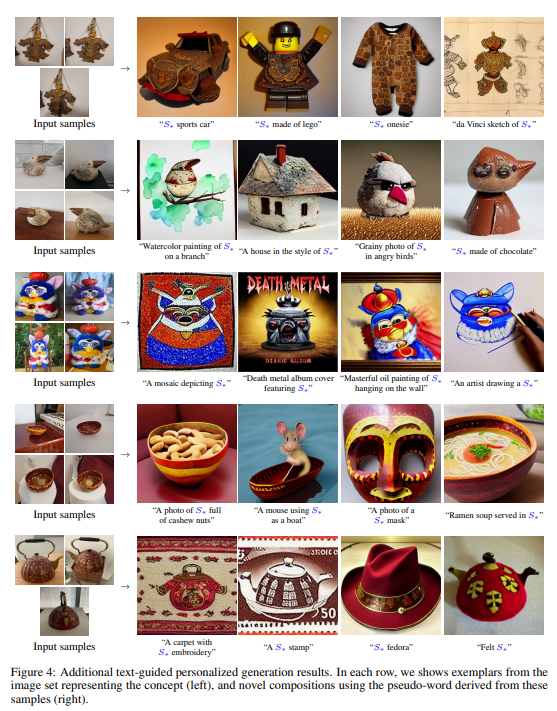
Then, style transfer ability and concept composition (utilize a text prompt with more than one new concept) ability were tested, as is possible to see in the below images.


Finally, a fascinating aspect that is often ignored is bias reduction, i.e., making the model as fair as possible in producing samples. Using small datasets curated for diversity bring a notable bias reduction (image below).

This Article is written as a research summary article by Marktechpost Staff based on the research paper 'An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, github link, and project page. Please Don't Forget To Join Our ML Subreddit
![]()
Leonardo Tanzi is currently a Ph.D. Student at the Polytechnic University of Turin, Italy. His current research focuses on human-machine methodologies for smart support during complex interventions in the medical domain, using Deep Learning and Augmented Reality for 3D assistance.
Credit: Source link
Comments are closed.