AWS Researchers Developed A Knowledge Graph Embedding Library Called Deep Graph Knowledge Embedding Library (DGL-KE) Built On The Deep Graph Library (DGL)
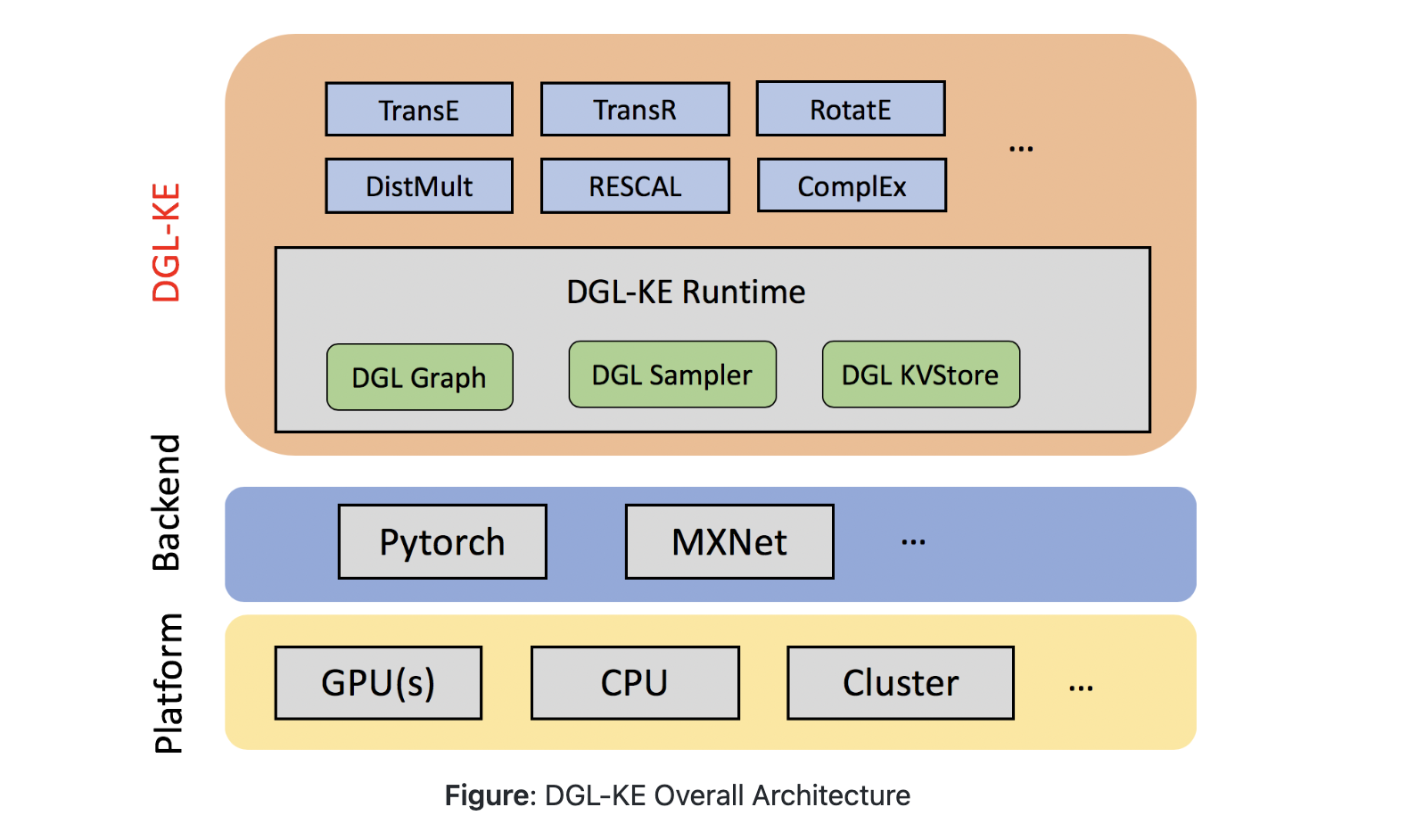
Data structures called knowledge graphs (KGs) are used to hold data about various entities (represented as nodes) and their relationships (as edges). Computing knowledge graph embeddings is an approach that is frequently used while performing various machine learning tasks. AWS has recently developed The Deep Graph Knowledge Embedding Library (DGL-KE), a knowledge graph embedding library based on the Deep Graph Library (DGL). This high-performance, user-friendly, and scalable toolkit for learning extensive knowledge graph embeddings has a variety of standard models that developers can use. The DGL-KE toolkit can be run on CPU, GPU, and cluster machines with popular models like TransE, TransR, etc. Trumid has made substantial use of this library to build cutting-edge machine learning platforms for trading in credit. The company has created an online trading platform where users may purchase, sell, and communicate with other users. Trumid requires an ML system to give a tailored trading experience by modeling the preferences and interests of its platform users due to a rise in the network of users.
To provide users with a quicker and more customized trading experience, this makes sure that the most pertinent insights and information are provided to them. To assist Trumid’s AI and Data strategy team, AWS Machine Learning Solutions Lab has been hired to develop an end-to-end pipeline consisting of data preparation, model training, and inference process based on a neural network model created using DGL-KE. A graph offers a natural way to depict this real-world complexity with the embedded information in the relationship between entities since bond trading may be thought of as a network of buyer-seller interactions covering numerous bond kinds.
Due to the dataset’s characteristics, graph ML algorithms fit bond training better than conventional ML algorithms. A graph ML method learns from a graph dataset that includes information about individual nodes, edges, and other attributes, unlike a typical ML algorithm, which uses tabular structured data. Trade size, period, issuer, rate, coupon values, bid/ask offers, kind of trading protocol, and signals of interest are characteristics of the dataset used by Trumid and AWS. These data are used to create interactive graphs between traders, bonds, and issuers, and a graph machine learning model is created to forecast the interactions in the future. The preparation of the data is the first stage in the recommendation pipeline. Trading data is represented as a graph with nodes and typed edges, where nodes are traders or bonds and edges are relations.
DGL-KE is a good fit for knowledge graphs because they only contain nodes and relations. The data maintained in a knowledge graph is frequently stated in triplets: head, relation, and tail ([h, r, t]), where the heads and tails are entities, and the union is also referred to as a statement. Knowledge Low dimensional representations of the elements and relations in a knowledge graph are called graph embeddings. The key area where popular KGE models diverge is in the score function. This function computes the separation between related things that are associated. While other unconnected items are spread out across the vector space, entities connected by a relation are close to one another.
DGL-KE now supports three activities: training, embedding assessment, and inference. The TransE embedding model was trained for this specific application. For prediction, equality has been utilized that adds the source node embedding and relation embedding to provide the target node embedding as the outcome. The bonds closest to the resulting embedding are the target node, the relation embedding is the trade-recent embedding, and the source node embedding is the trader embedding. The top 100 highest scores for each trader are computed using this method, which is tested to compute scores for all potential trade-recent relations. The solution is made available in production as a single script for SageMaker processing. This is feasible because the three processes of data preparation, model training, and prediction are interdependent. DGL-KE is made for large-scale learning. With millions of nodes and billions of edges, it presents several unique improvements that speed up training on knowledge graphs. Compared to the other methods, this implementation increases mean recall—the percentage of real deals predicted by the recommender, averaged across all traders—by 80% across all trade types.
Github link | Reference Article
Please Don't Forget To Join Our ML Subreddit
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.