Researchers created a Novel Framework called ‘FedD3’ for Federated Learning in Resource-Constrained Edge Environments via Decentralized Dataset Distillation
For collaborative learning in large-scale distributed systems with a sizable number of networked clients, such as smartphones, connected cars, or edge devices, federated learning has emerged as a paradigm. Previous research has attempted to speed up convergence, reduce the number of required operations, and increase communication efficiency due to the limited bandwidth between clients. However, this type of cooperative optimization still results in high communication volumes for current neural networks with over a billion parameters, necessitating significant network capacity (up to the Gbps level) to function consistently and effectively. Due to this limitation, federated learning models cannot be widely used in commercial wireless mobile networks, such as vehicle communication networks or industrial sensor networks.
This communication bottleneck drove prior federated learning methods to lower the number of communication rounds and, consequently, the communication volume to achieve satisfactory learning convergence. To reduce the communication costs associated with training a support vector machine by exchanging information in a single round, Guha et al. propose one-shot federated learning. Although it might be challenging to characterize the distribution of an actual dataset, Kasturi et al. present a fusion of federated learning that uploads both the model and the data distribution to the server.
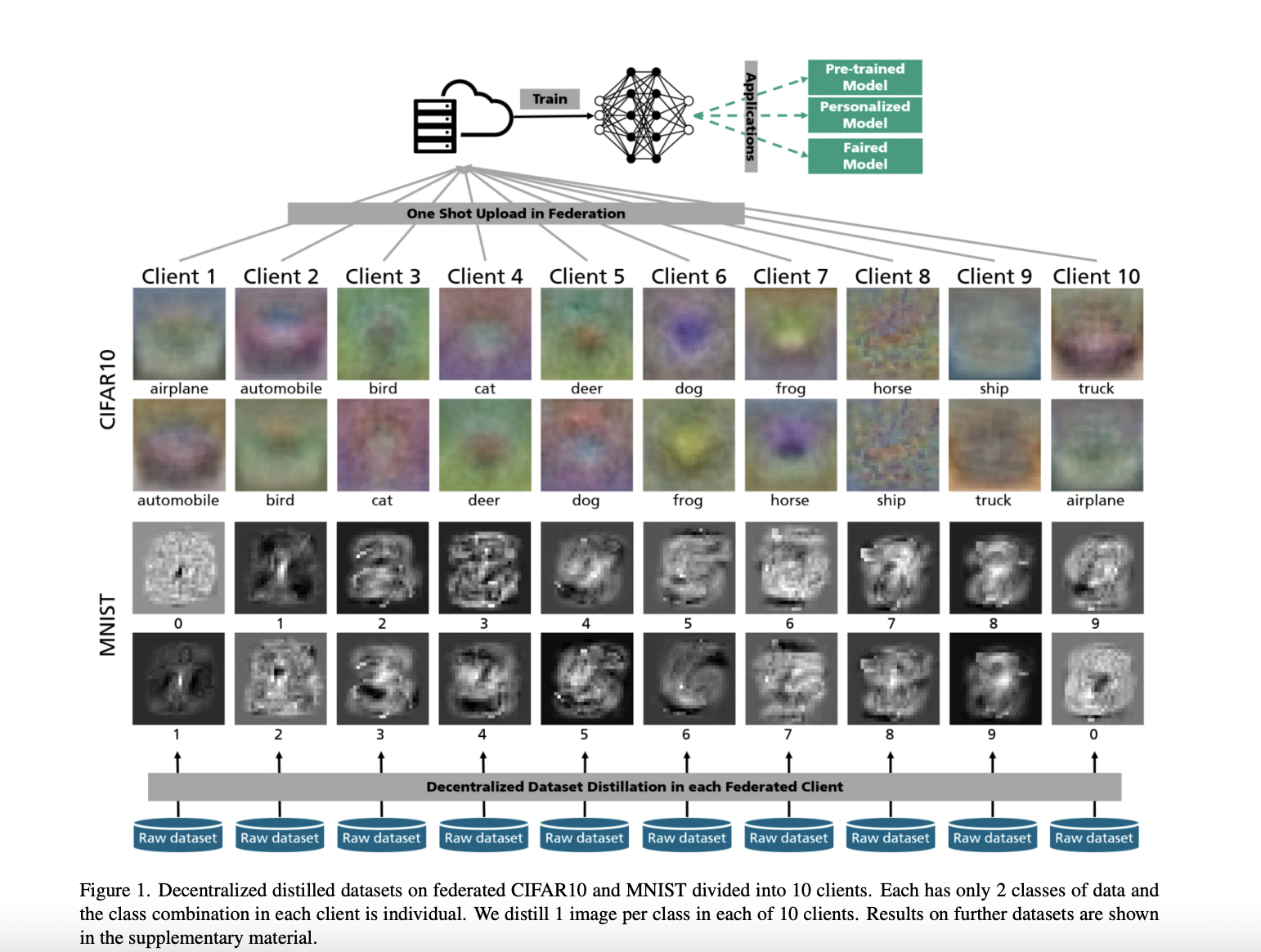
One-shot federated learning method based on knowledge transfer is universal, but sending numerous student models to the server adds to the communication cost. Researchers offer a novel federated learning training scheme with one-shot communication through dataset distillation inspired by the one-shot scheme. It makes intuitive sense to synthesize and send significantly smaller but more valuable datasets with dense characteristics. More educational training data is transferred over the constrained bandwidth without violating anyone’s privacy. In particular, Researchersprovide FedD3, a unique federated learning system that incorporates dataset distillation.
It allows for effective federated learning by sending the locally distilled dataset to the server simultaneously. This may apply a pre-trained model and be utilized for individualized and fair learning. One of federated learning’s most significant benefits, privacy, is preserved by this technique. Similar to the shared model parameters in earlier federated learning approaches but far more effective and efficient, it anonymously maps distilled datasets from the original client data without any exposure.
The communication efficiency in federated learning is assessed appropriately by adjusting the significance of accuracy gain to the communication cost. The tests specifically show the trade-off between accuracy and communication expense. Researchers suggest a new assessment metric, the -accuracy gain, to address this trade-off. Researchers also examine the effects of particular external variables, such as Non-IID datasets, client count, and local contributions. Researchers show excellent potential for this approach in federated learning networks with limited communication costs.
They demonstrate through experimentation that FedD3 has the following benefits. Firstly FedD3 obtains much better performance even with less communication volume, where the accuracy in a distributed system with 500 clients is enhanced by over 2.3 (from 42.08% to 94.74%) on Non-IID MNIST. Secondly, compared to other one-shot federated learning, FedD3 obtains much better performance even with less communication volume. The accuracy in a distributed system with 500 clients is enhanced by over 2.3 (from 42.08% to 94).
Following are the four parts of contributions made in this paper:
- Researchers propose a novel framework, FedD3, for effective federated learning in a one-shot manner
- Researchers demonstrate FedD3 with two different dataset distillation instances in clients.
- Researchers also introduce a decentralized dataset distillation scheme in federated learning systems in which distilled data, rather than models, are uploaded to the server.
- The research paper’s studies, mainly when accuracy and communication cost are traded off, show the design’s enormous potential in federated learning networks with constrained communication resources. Everyone has access to the source code on GitHub.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Federated Learning via Decentralized Dataset Distillation in Resource-Constrained Edge Environments'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Content Writing Consultant Intern at Marktechpost.
Credit: Source link
Comments are closed.