Researchers develop Genomepy which helps you to get the right Genomic Data for your analysis
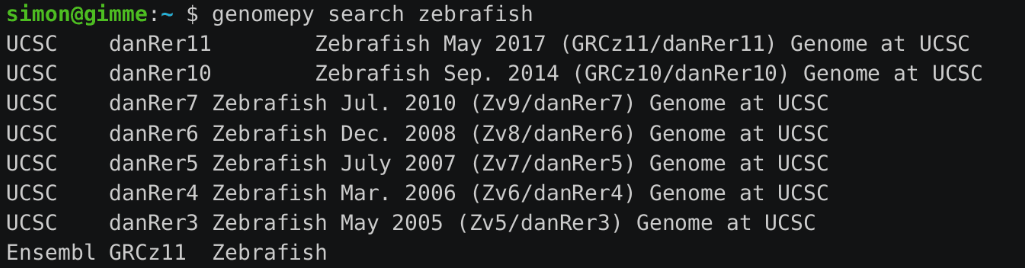
In biological research, data analysis is becoming increasingly important. Any researcher will require external information such as a reference genome or a specific gene annotation for studying gene expression in a collection of samples or transcription factor binding motifs in genomic atlases. There are three primary suppliers for this sort of data: Ensembl1, UCSC2, and NCBI3, as well as several model-system-specific providers like GENCODE4, ZFIN5, FlyBase6, WormBase7, Xenbase8, and others. Different providers use different ways of assembling genome assemblies and gene annotations, which affects formats, format compliance, terminology, data quality, available versions, and the release cycle.
These distinctions considerably influence compatibility with research9, tools, and (data derived from) other genetic data. One may look for genetic data independently, but there are several choices. Ensembl, UCSC, and NCBI provide FTP archives, online portals, and REST APIs for searching their respective datasets. Alternatively, programs such as NCBI-genome-download10 and ucscgenomes-downloader 11 can be used to access some of these datasets programmatically. None of these, however, can search, compare, or download data from all significant genome sources. Furthermore, manually obtaining and analyzing genetic data can be time-consuming, error-prone, and difficult to replicate.
Although the latter might be addressed with a data management tool such as iGenomes12, refGenie13, or Go Get Data14, most data managers still need the user manually enter new data. They created genomepy to
- identify genomic data on key providers,
- compare gene annotations,
- choose the genomic data that is most suited to their investigation, and
- give a set of utilities to browse and edit the data.
Data may be retrieved from any location and processed automatically.
Data sources and processing procedures are recorded to ensure repeatability, which may be increased further by utilizing a data manager. Genomic data may be fed into genomepy, which works with and extends on programs such as pyfaidx15, pandas16, and MyGene.info17 to work quickly with gene and genome sequences and information. Genomepy may be used from the command line and through the (well documented) Python API for one-time analysis or integration into pipelines and workflow managers. Genomepy has also been integrated into other programs, such as pybedtools18 and CellOracle19.
Obtaining relevant genetic data is a critical step in any genomics research. A genome with the requisite sequence masking, biological diversity, and contigs may be obtained with a single command. Genomepy makes it simple to find and download available assemblies. Gene annotations in GTF and BED12 format that match the genome may be retrieved similarly, with additional choices accessible via the Python API. Any installation choices one selects are recorded for repeatability, allowing them to begin their study with confidence.
One can install genomepy via bioconda:
conda install -c bioconda genomepyOr via pip with Python 3.7+:
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'genomepy: genes and genomes at your fingertips'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and code. Please Don't Forget To Join Our ML Subreddit
![]()
Content Writing Consultant Intern at Marktechpost.
Credit: Source link
Comments are closed.