PeRFception: A Pipeline of Generating Large-Scale 3D Datasets with Radiance Fields
Implicit representations of 3D scenes can encode hundreds of high-resolution images in a compact format, allowing several applications like 3D reconstruction and photorealistic synthesis of novel views. For instance, a Neural Radiance Fields (NeRF) model is a neural network that learns how to represent a 3D object from a set of images that represent the object from different perspectives. This approach allows learning high-fidelity photometric features (e.g., reflection and refraction) differently than the more conventional explicit representations like meshes and point clouds.
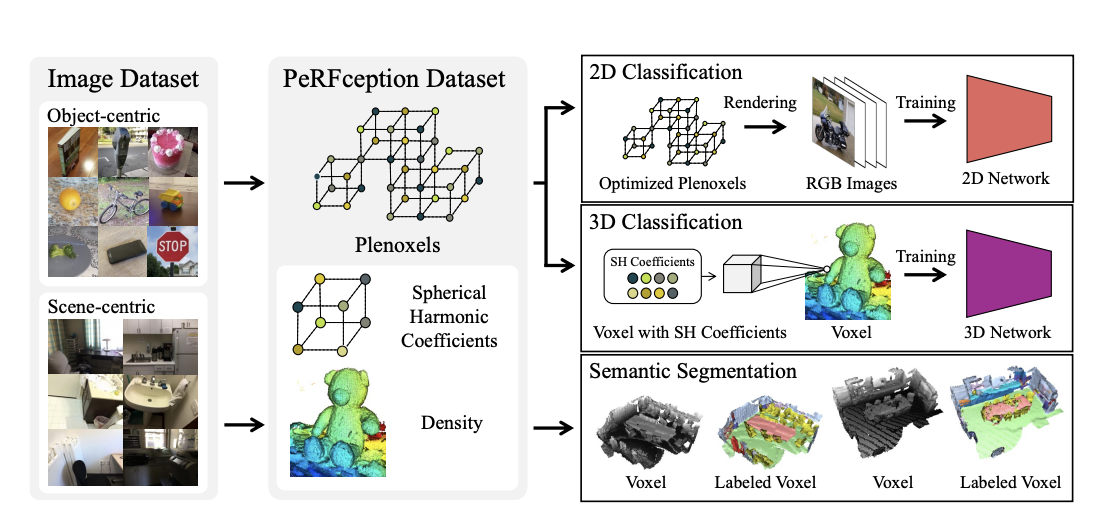
Unfortunately, NeRFs have different drawbacks that prevent using implicit representations as the standard 3D data format for perception tasks. For instance, the training process of an implicit network could be very slow. At the same time, the inference process is too long to be integrated into any real-time application. Finally, the features implicitly learned by a NeRF model are scene-specific and cannot be transferred to other scenes. Recently, variants of NeRF, like Plenoxels, have been proposed to overcome the above-mentioned problems. Indeed, Plenoxels support a fast learning process while maintaining a consistent feature representation among scenes. Specifically, Plenoxels represent scenes through a sparse 3D grid with spherical harmonics, as depicted in the following figure.
Implicit representations like Plenoxels could be used for perception tasks such as classification and segmentation. However, there was still no large-scale implicit representation dataset for perception tasks. For this reason, by using Plenoxels as data format, a group of researchers from POSTECH, NVIDIA, and Caltech created the first two large-scale implicit datasets. More specifically, the authors converted the Common Object 3D (CO3D) and the ScanNet datasets into Plenoxels, obtaining two novel datasets: PeRFception-CO3D and PeRFception-ScanNet. These two datasets cover object-centric and scene-centric scenarios, respectively. Moreover, they allow encoding both 2D and 3D information in a unified form while presenting a significant compression rate compared to the original datasets.
CO3D is an object-centric dataset with 1.5 million camera-annotated frames and 50 different classes. It also includes reconstructed point clouds versions of the objects. The following figure compares some examples of the original dataset with the PeRFception-CO3D. The Plenoxels version of the dataset allows a compression rate of 6.94%.
The ScanNet dataset contains more than 1.5K 3D scans of indoor scenes. However, a certain number of frames include motion blur. For this reason, blurry images are discarded before the conversion into Plenoxels. The resulting PeRFception-ScanNet dataset leads to a significant compression rate of 96.4%, emphasizing the accessibility of the Plenoxels representation.
Finally, the authors also conducted several experiments, including 2D image classification, 3D object classification, and 3D scene semantic segmentation. Such experiments showed that the two novel datasets could effectively encode both 2D and 3D information in a unified and compressed data format.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'PeRFception: Perception using Radiance Fields'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, project page and code. Please Don't Forget To Join Our ML Subreddit
![]()
Luca is Ph.D. student at the Department of Computer Science of the University of Milan. His interests are Machine Learning, Data Analysis, IoT, Mobile Programming, and Indoor Positioning. His research currently focuses on Pervasive Computing, Context-awareness, Explainable AI, and Human Activity Recognition in smart environments.
Credit: Source link
Comments are closed.