Google AI Proposes a Computer Vision Framework Called ‘LOLNeRF’ that Learns to Model 3D Structure and Appearance from Collections of Single-View Images
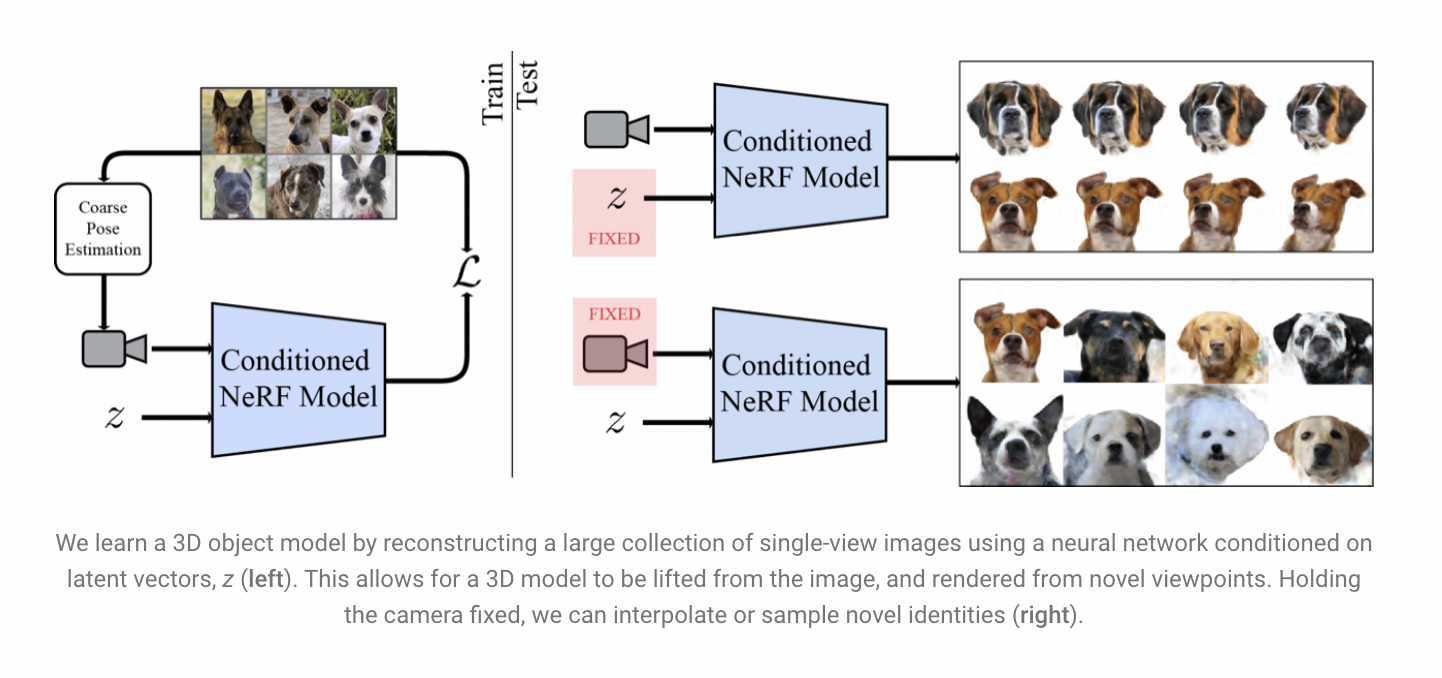
The capacity of human vision to interpret 3D shapes from the 2D images we see is a crucial feature. It has been a major obstacle in the field to use computer vision systems to achieve this level of understanding. Many effective methods rely on multi-view data, which makes it much simpler to infer the 3D shape of objects in the photos because it provides two or more photographs of the same scene available from various perspectives.
Researchers suggest a system that learns to model 3D structure and appearance from sets of single-view photos in “LOLNeRF: Learn from One Look,” presented at CVPR 2022. This makes it possible to extract a 3D model from the image and render it from unusual angles. Only one view of every given thing, never the same object twice, is used to learn characteristic 3D structures of objects such as cars, human faces, or cats

Using GLO and NeRF together
By co-learning a neural network (decoder) and a table of codes (latent), which is also an input to the decoder, GLO is a general technique that learns to reconstruct a dataset (such as a collection of 2D images). Each latent code recreates a single dataset element (such as an image). The network must generalize since the latent codes have less dimensions than the data items. As a result, it learns common data structure (such as the general shape of dog snouts).
An excellent method for recreating a static 3D object from 2D pictures is NeRF. A neural network portrays an item by producing colour and density for each point in three-dimensional space. A ray is created for each pixel in a 2D image, and colour and density values are accumulated along each ray. These are blended using traditional volume rendering for computer graphics to determine the final pixel colour. Significantly, all of these operations can be differentiated, enabling end-to-end oversight.
Each rendered pixel (of the 3D representation) must match the colour of the pixels in the ground truth (2D) image in order for the neural network to create a 3D representation that can be drawn from any angle.
By providing each object with a latent code and concatenating it with typical NeRF inputs, they combine NeRF with GLO to enable it to rebuild multiple objects. To recreate the input images, they co-optimize these latent codes with network weights using GLO. The researcher monitors their procedure with only single views of any object, in contrast to traditional NeRF, which necessitates numerous views of the same object (but multiple examples of that type of object). NeRF is fundamentally 3D, so they can render the item from any angle. When NeRF and GLO are used together, it can learn the shared 3D structure across instances with just one view while still being able to reproduce particular examples of the dataset.
Estimation by camera
NeRF requires precise camera location information about the object for each image to function. It is typically unknown unless this was measured when the photograph was shot. Instead, they extract five iconic areas from the photos using the MediaPipe Face Mesh. Each of these 2D predictions corresponds to a spot on the object that makes sense semantically. Then, by generating a set of canonical 3D locations for the semantic points and estimating the camera postures for each image, the projection of the canonical points into the images can be made as compatible as possible with the 2D landmarks.
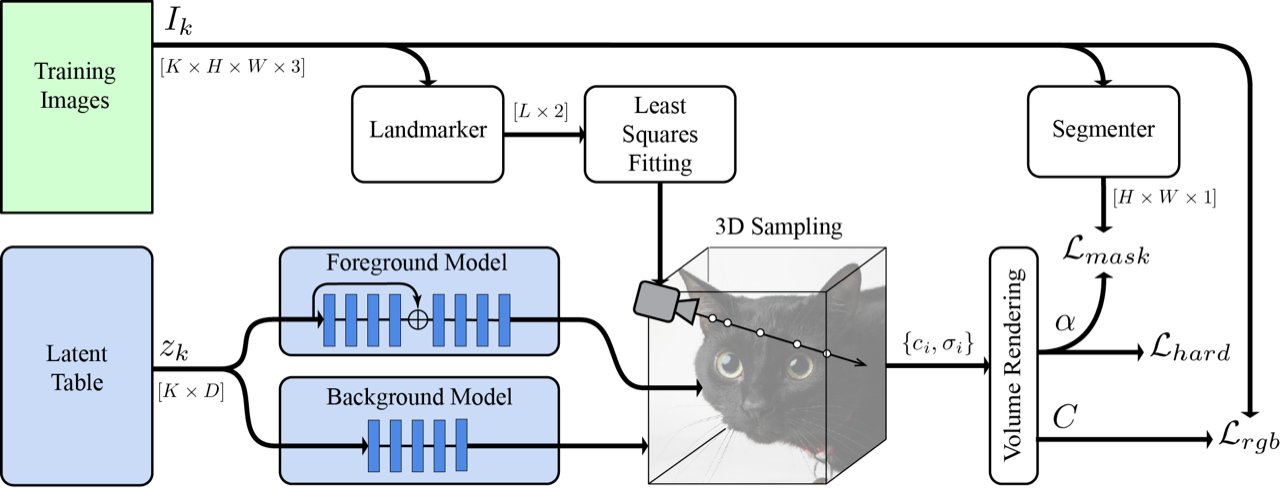
Along with a NeRF model, they train a database of latent codes for each image. Losses in per-ray RGB, mask, and hardness may affect the output. Cameras are created by fitting anticipated landmarks to established 3D key points.
Mask and Hard Surface Losses
The photos are faithfully reproduced by standard NeRF; however, in their single-view case, it frequently results in images that appear hazy when seen off-axis. To solve this problem, they present a novel hard surface loss that encourages the density to adopt crisp transitions from exterior to interior regions, decreasing blurring. Essentially, this instructs the network to produce “solid” surfaces rather than semi-transparent ones, like clouds.
They also improved outcomes by dividing the network into the separate foreground and background networks. They oversaw this separation with a mask from the MediaPipe Selfie Segmenter and a loss to promote network specialty. This improves the foreground network’s quality by enabling it to focus exclusively on the object of interest and avoid being “distracted” by the background.
Results
Unexpectedly, they found that fitting just five key points gave camera predictions that were accurate enough to train a model for dogs, cats, or human faces. This means that, with only one perspective, they may create a brand-new image of your beloved pets, Schnitzel, Widget, and friends from any angle.
Example cat photos from AFHQ at the top. Bottom: A compilation of original 3D views
produced by LOLNeRF.

Conclusion
They have devised a method for extracting 3D structures from a single 2D image. They are looking at possible use cases for LOLNeRF because they believe it has enormous potential for various applications.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'LOLNeRF: Learn from One Look'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
Ashish kumar is a consulting intern at MarktechPost. He is currently pursuing his Btech from the Indian Institute of technology(IIT),kanpur. He is passionate about exploring the new advancements in technologies and their real life application.
Credit: Source link
Comments are closed.