SimpleRecon: A Computer Vision Framework that Produces 3D Reconstructions Without the Use of 3D Convolutions
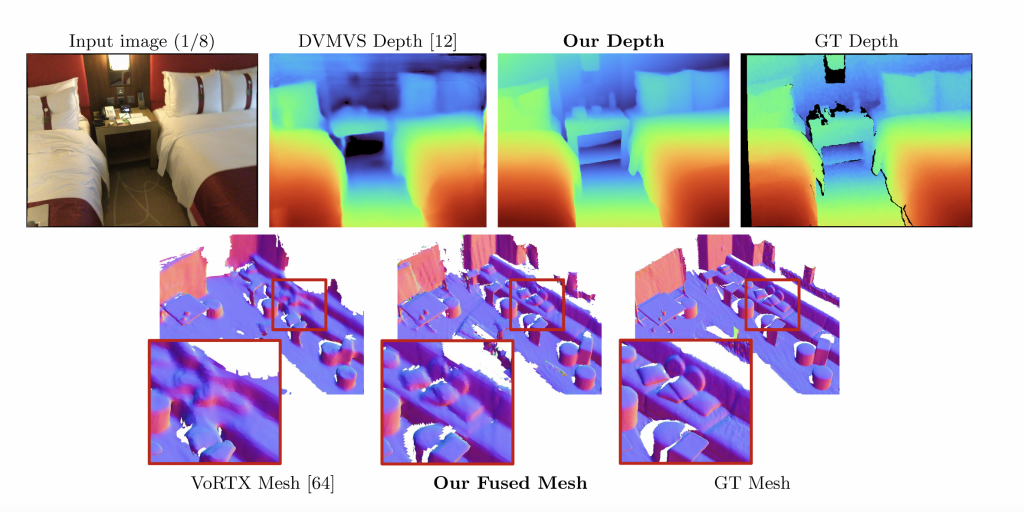
3D reconstruction is a fundamental problem in computer vision. The goal is to infer the true geometry of an object or a scene given an image observation from an unknown camera viewpoint and/or under unknown lighting conditions. This is an important task for many applications like autonomous driving, augmented reality content placement, and robotic navigation.
Traditionally, to construct 3D space, the first thing is to capture 2D depth maps using multi-view stereo (MVS). These 2D maps are then fused together to form a 3D representation of the captured surface.
Recently, a family of deep learning-based methods that reconstruct directly in the final 3D volumetric feature space has been developed. The key component of these methods is the 3D convolution. Although these methods have demonstrated outstanding reconstruction results, their practicality in real-world scenarios is limited since they use costly 3D convolutional layers.
This is where SimpleRecon comes into play. Instead of relying on memory-hungry and computationally expensive 3D convolutions, they go back to basics. They show that it is possible to achieve accurate depth estimation using a 2D CNN augmented with a cost volume.
SimpleRecon sits in between monocular depth estimation and MVS via plane sweep. A depth prediction encoder-decoder architecture is augmented with a cost volume. The image encoder extracts matching features from the source and reference images, then pass them to the cost volume. Finally, using a 2D convolutional encoder-decoder network, the output of the cost volume that is augmented with image-level features is processed.
SimpleRecon has two main contributions, which make it a state-of-the-art multi-view depth estimator.
The first contribution is a carefully-designed 2D CNN that utilizes strong image priors alongside a plane-sweep 3D feature volume and geometric losses. The network is based on a 2D convolutional autoencoder design. The authors avoid using computationally expensive structures such as LSTMs to keep the network lightweight.
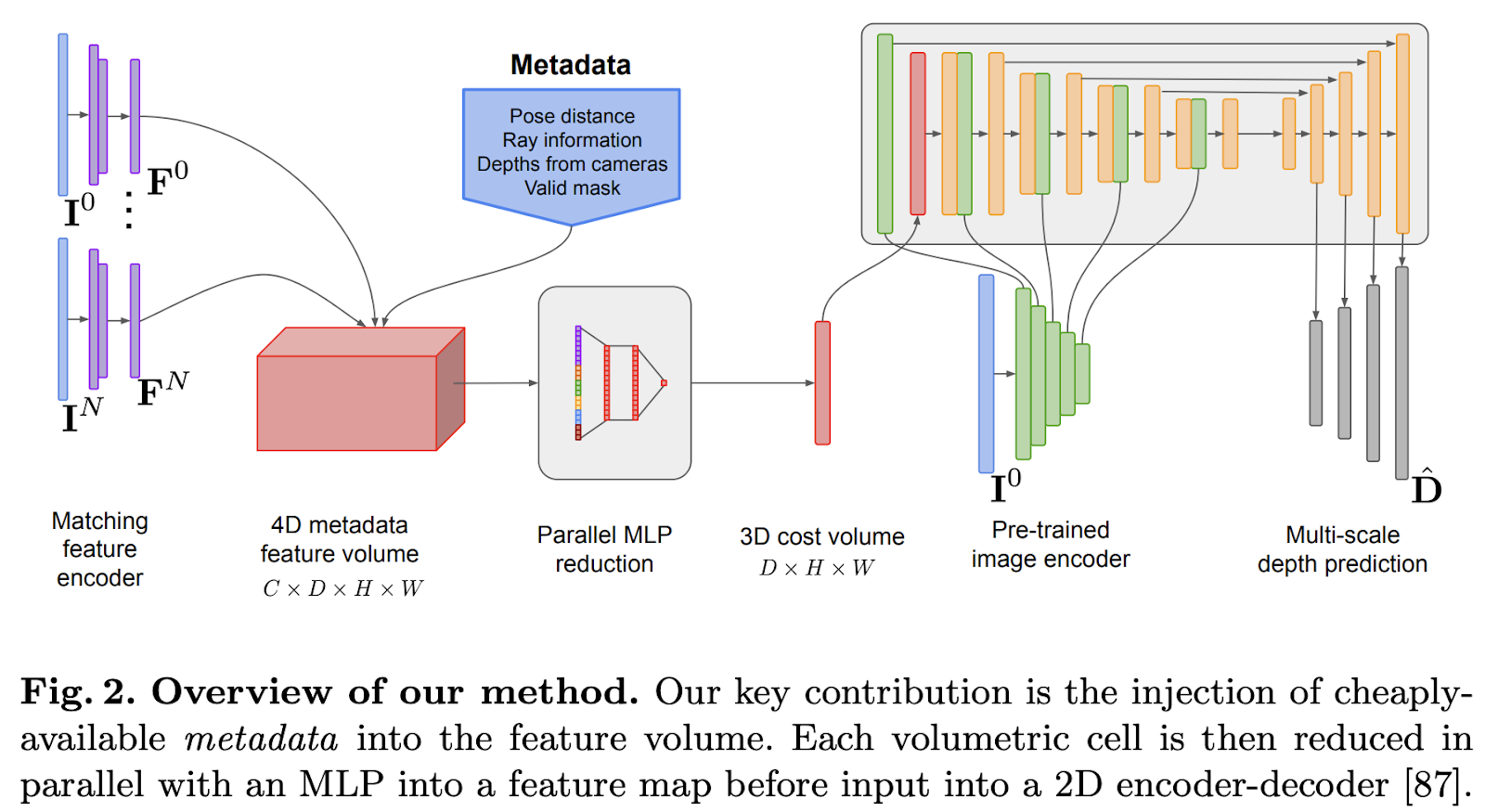
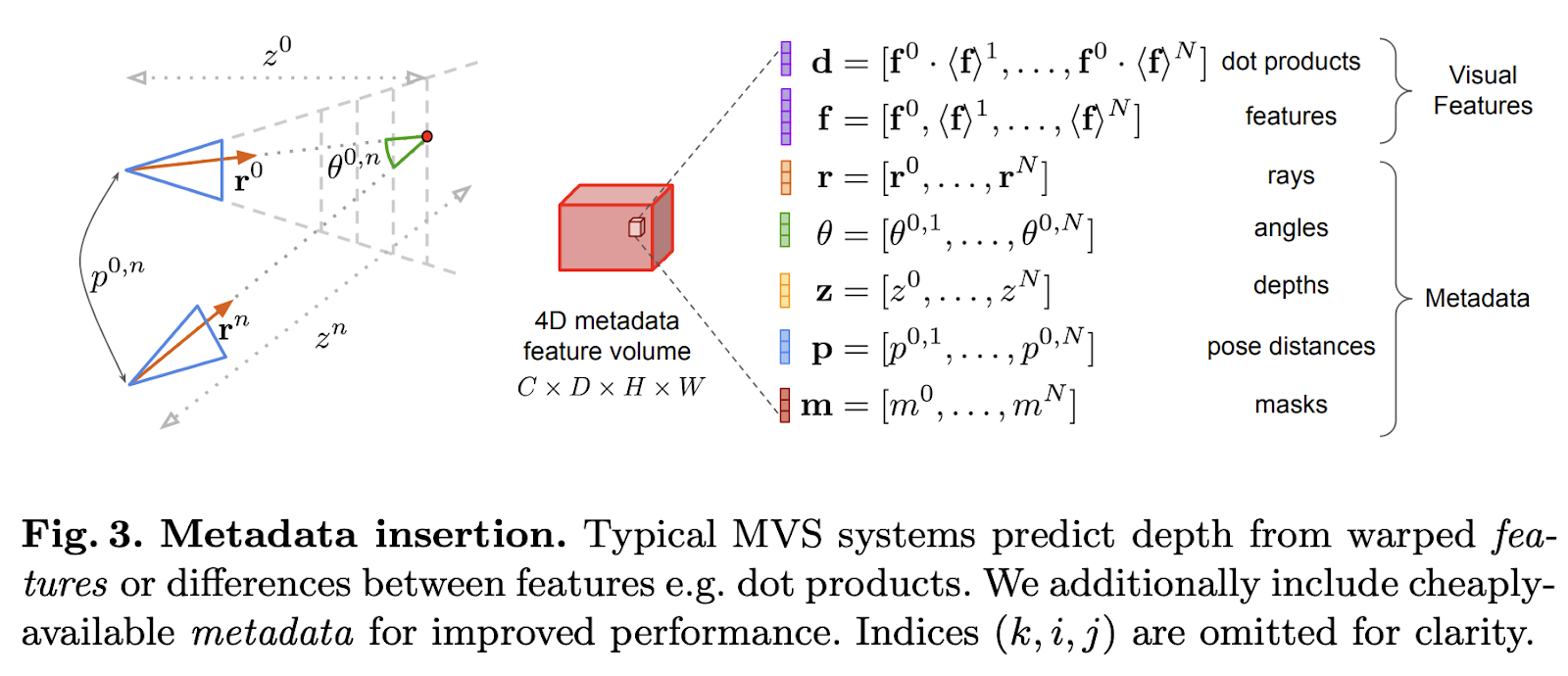
The second contribution is the integration of keyframe and geometric metadata into the cost volume, which is a cheap operation but results in a significant performance boost. Traditional stereo methods provide crucial information that is usually disregarded. In this study, the easily accessible metadata is included in the cost volume, enabling the network to aggregate data intelligently across views. This may be accomplished in two ways: overtly by adding more feature channels or implicitly by mandating a certain feature ordering.
The metadata is injected into the network by augmenting the image-level features using additional metadata channels. This is extremely helpful for the network to reason about the importance of each source image for estimating the depth of a given pixel, as these channels encode information about the 3D relationship between the images.
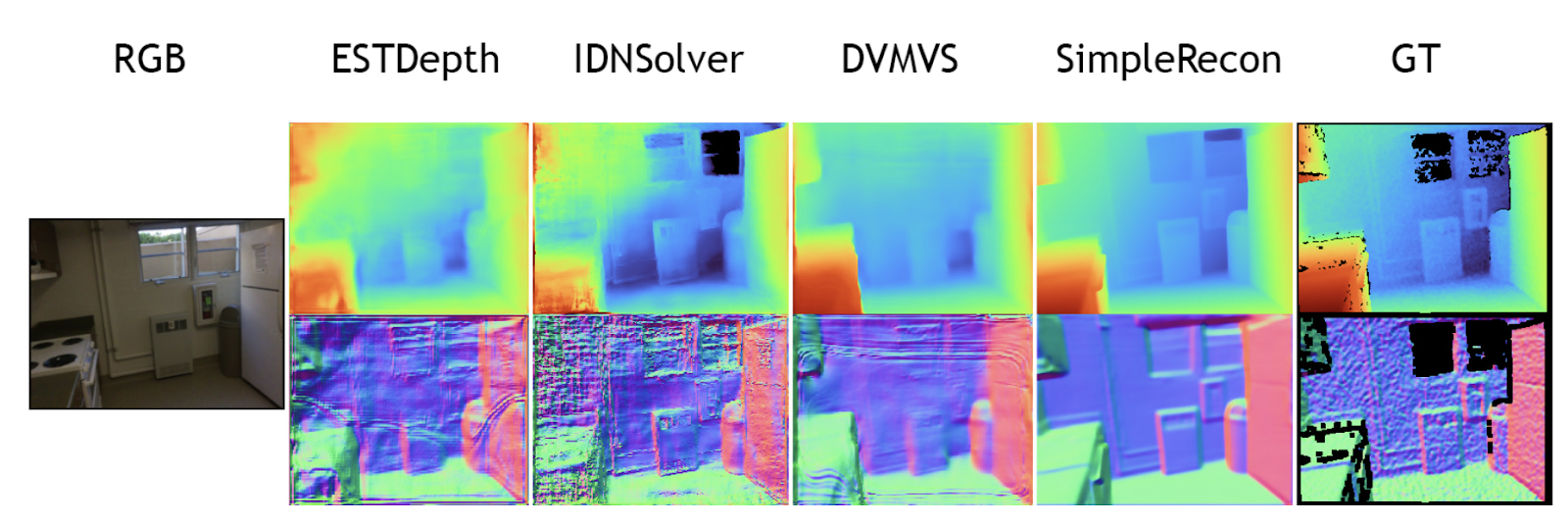
SimpleRecon can produce accurate depth estimation in different scenarios while being a lightweight network that can be used in practical use cases. The authors name their study as “back-to-basics” and show that high-quality depths are what is needed for high-quality reconstructions.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'SimpleRecon: 3D Reconstruction Without 3D Convolutions'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.