Google AI 0pen Sources ‘FedJAX’, A JAX-based Python Library for Federated Learning Simulations
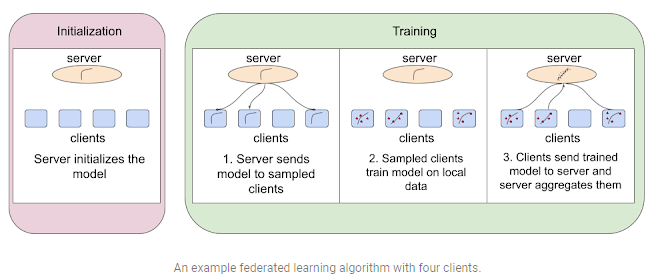

Federated learning is a machine learning environment in which multiple clients (such as mobile devices or entire enterprises, depending on the task at hand) collaborate to train a model under the supervision of a central server. The training data, however, remains decentralized.
Because of the increased attention on privacy and security, federated learning has become a particularly important research topic. In such a fast-paced sector, it’s critical to swiftly translate ideas into code, iterate quickly, and compare and duplicate existing baselines.
A new google study introduces FedJAX, a JAX-based open-source library for federated learning simulations that emphasizes ease-of-use in research. FedJAX intends to construct and assess federated algorithms faster and easier for academics by providing basic building blocks for implementing federated algorithms, preloaded datasets, models, and algorithms, and fast simulation speed.
Library Structure
Few new concepts introduced by FedJAX are as follows:
- FedJAX code resembles the pseudo-code used in academic publications to describe novel algorithms, making it simple to get started.
- Although FedJAX provides federated learning building pieces, users can replace them with the most basic implementations utilizing only NumPy and JAX. This doesn’t affect the overall training time.
Included Dataset and Models
In contemporary federated learning research, image recognition, language modeling, and other commonly used datasets and models. These datasets and models can be used directly in FedJAX, eliminating the need to write preprocessed datasets and models from scratch. This not only allows for valid comparisons of different federated methods but also speeds up the creation of new ones.
Currently, FedJAX includes datasets and sample models for EMNIST-62, a character recognition task, Shakespeare, a next character prediction task, and Stack Overflow, a next word prediction task.
FedJAX provides tools to construct new datasets and models that can be used with the rest of the library in addition to these standard settings. Finally, to make comparing and assessing existing algorithms easier, FedJAX includes standard implementations of federated averaging and other federated algorithms for training a shared model on decentralized examples, such as adaptive federated optimizers, agnostic federated averaging, and Mime.
Evaluation
The researchers used the image recognition task for the federated EMNIST-62 dataset and the next word prediction challenge for the Stack Overflow dataset to test a standard FedJAX implementation of adaptive federated averaging. Federated EMNIST-62 is a smaller dataset consisting of 3400 users and their writing samples, one of 62 characters (alphanumeric). The Stack Overflow dataset is much larger and consists of millions of questions and answers from the Stack Overflow forum for thousands of users.
The team evaluated the implementation on various machine learning-specific devices, including GPU and TPU and Multi-core TPU. They trained the model on GPU (NVIDIA V100) and TPU (1 TensorCore on a Google TPU v2) for 1500 rounds with 10 clients per round for federated EMNIST-62. For Stack Overflow, the model was trained for 1500 rounds with 50 clients per round on GPU (NVIDIA V100), TPU (1 TensorCore on a Google TPU v2), and multi-core TPU (8 TensorCores on a Google TPU v2).


They note that the entire experiments for federated EMNIST-62 can be completed in a few minutes with conventional hyperparameters and TPUs, while Stack Overflow takes about an hour.
As the number of customers per round grows, the researchers examined the average training round duration on Stack Overflow. When comparing the average training round duration between TPU (8 cores) and TPU (1 core) (in the figure), it is clear that employing several TPU cores improves runtime significantly when the number of clients participating every round is large.

The team hopes that FedJAX will encourage further research and interest in federated learning. They intend to expand our present collection of algorithms, aggregation techniques, datasets, and models in the future.
GitHub: https://github.com/google/fedjax
Research: https://arxiv.org/pdf/2108.02117.pdf
Source: https://ai.googleblog.com/2021/10/fedjax-federated-learning-simulation.html
Suggested
Credit: Source link
Comments are closed.