Latest Computer Vision Research From China Proposes a LiDAR-Inertial-Visual Fusion Framework Termed R3LIVE++ to Achieve Robust and Accurate State Estimation While Simultaneously Reconstructing the Radiance Map on the Fly
Simultaneous localization and mapping (SLAM) is a system that estimates sensor postures while concurrently reconstructing a 3D map of the surrounding environment using a sequence of sensor data (e.g., camera, LiDAR, IMU). SLAM has been widely used in localization and feedback control for autonomous robotics (e.g., uncrewed aerial vehicles, automated ground vehicles, and self-driving automobiles) because it can estimate postures in real time. Meanwhile, because of its ability to recreate maps in real-time, SLAM is essential for navigation in robots, virtual and augmented reality (VR/AR), surveying, and mapping applications. Different applications often need varying levels of mapping detail, such as a sparse feature map, a 3D dense point cloud map, and a 3D radiance map (i.e., a 3D point cloud map with radiance information).
Existing SLAM systems may be divided into two categories based on the sensor used: visual SLAM and LiDAR SLAM. For example, the sparse visual feature map is suited for and widely utilized for camera-based localization. The sparse characteristics detected in pictures may be used to calculate the camera’s posture. Even for small items, the 3D dense point cloud can capture the geometrical structure of the environment. Finally, radiance maps, including geometry and radiance information, are utilized in mobile mapping, augmented reality/virtual reality (AR/VR), video gaming, 3D modeling, and surveying. These apps require geometric structures and textures to generate virtual worlds that are similar to the actual world.
Visual SLAM is based on low-cost and SWaP-efficient camera sensors and has produced good results in localization accuracy. The rebuilt map is also acceptable for human interpretation because of the abundant, vivid information measured by cameras. However, because of the lack of direct, precise depth measurements, visual SLAM mapping accuracy and resolution are often lower than LiDAR SLAM. Visual SLAM maps surroundings by triangulating disparities from multi-view pictures (e.g., structure from motion for mono-camera, stereo-vision for stereo-camera), an exceptionally computationally intensive operation that frequently necessitates hardware acceleration or server clusters.
Furthermore, the estimated depth accuracy reduces quadratically with measurement distance due to measurement disturbances and the baseline of multi-view pictures, making visual SLAM challenging to rebuild large-scale outside landscapes. Furthermore, visual SLAM can only be used in well-lit circumstances and will degrade in high-occlusion or texture-less surroundings. LiDAR SLAM, on the other hand, is based on LiDAR sensors. LiDAR SLAM may achieve substantially greater accuracy and efficiency on both localization and map reconstruction than visual SLAM due to the high measurement accuracy (a few millimeters) and extensive measurement range (hundreds of meters) of LiDAR sensors. LiDAR SLAM, on the other hand, frequently fails in settings with inadequate geometry characteristics, such as lengthy tunnel-like hallways, confronting a single large wall, and so on.

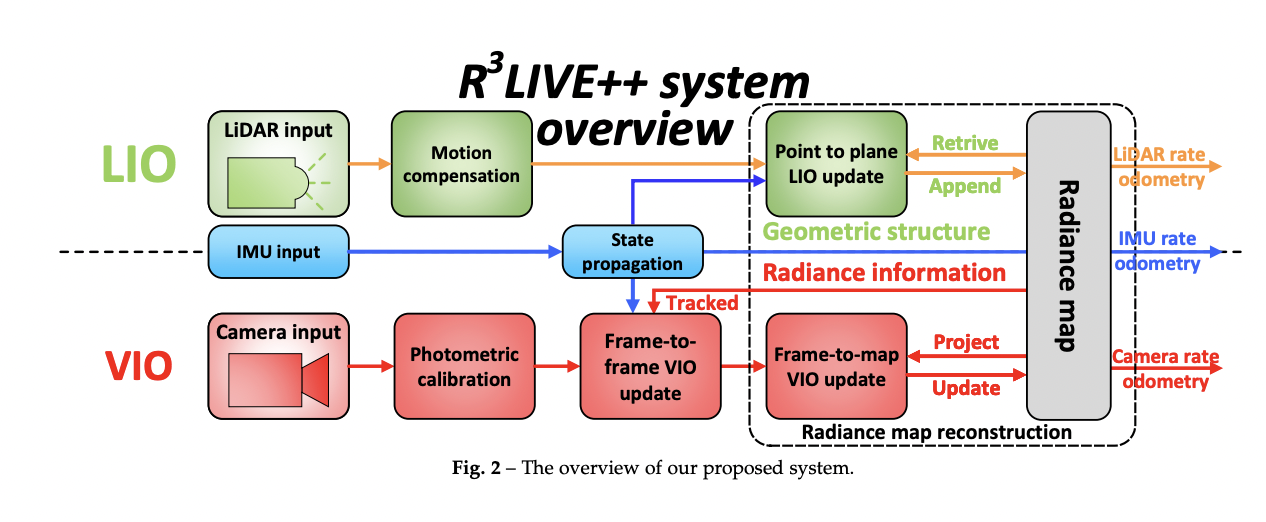
Fusing LiDAR and camera measurements in SLAM might overcome sensor degeneration concerns in localization and meets the demands of diverse mapping applications. Furthermore, LiDAR SLAM can only recreate the geometric structure of the environment and does not contain color information. As a result, they offer R3LIVE++, which has a LiDAR-Inertial-Visual fusion architecture that strongly connects two subsystems: LiDAR-inertial odometry (LIO) and visual-inertial odometry (VIO). In real-time, the two subsystems collaborate and progressively generate a 3D radiance map of the surroundings.
The LIO subsystem, in particular, reconstructs the geometric structure by registering new points in each LiDAR scan to the map. In contrast, the VIO subsystem recovers the radiance information by mapping pixel colors in each picture to points on the map. It employs a revolutionary VIO architecture that monitors the camera posture (as well as estimates another system status) by minimizing the radiance difference between locations on the radiance map and a sparse collection of pixels in the current picture. The direct photometric inaccuracy on a sparse collection of individual pixels effectively constrains the computation burden, and the frame-to-map alignment efficiently minimizes the odometry drift.
Furthermore, depending on photometric inaccuracies, the VIO can estimate the camera exposure duration online, allowing for the recovery of genuine radiance information from the surroundings. Benchmark findings on 25 sequences from an open dataset (the NCLT-dataset) reveal that R3LIVE++ outperforms all existing SLAM systems (e.g., LVI-SAM, LIO-SAM, FASTLIO2) in terms of overall accuracy. R3LIVE++ is resilient to exceedingly demanding conditions in which LiDAR and camera measurements degenerate, according to studies on their dataset (e.g., when the device faces a single texture-less wall).
Finally, compared to other competitors, R3LIVE++ calculates the camera exposure time more precisely and reconstructs the genuine radiance information of the environment with substantially lower errors than measured pixels in photos. To their knowledge, it is the first radiance map reconstruction framework capable of real-time performance on a PC with an average CPU and no hardware or GPU accelerations. The technology is open source to facilitate replication of current work and assist future research. Based on a collection of offline tools for model reconstruction and textures that have been improved, the system has tremendous potential in several real-world applications, such as 3D HDR photography, physics simulation, and video gaming.
The code implementations and sample videos can be found on GitHub.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'R3LIVE++: A Robust, Real-time, Radiance reconstruction package with a tightly-coupled LiDAR-Inertial-Visual state Estimator'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Content Writing Consultant Intern at Marktechpost.
Credit: Source link
Comments are closed.