In a New Machine Learning Paper, Researchers From Deepmind Propose an approach ‘Called Augmented Policy Cloning (APC),’ to Support the Process of Data-Efficiently Learning from Parametric Experts
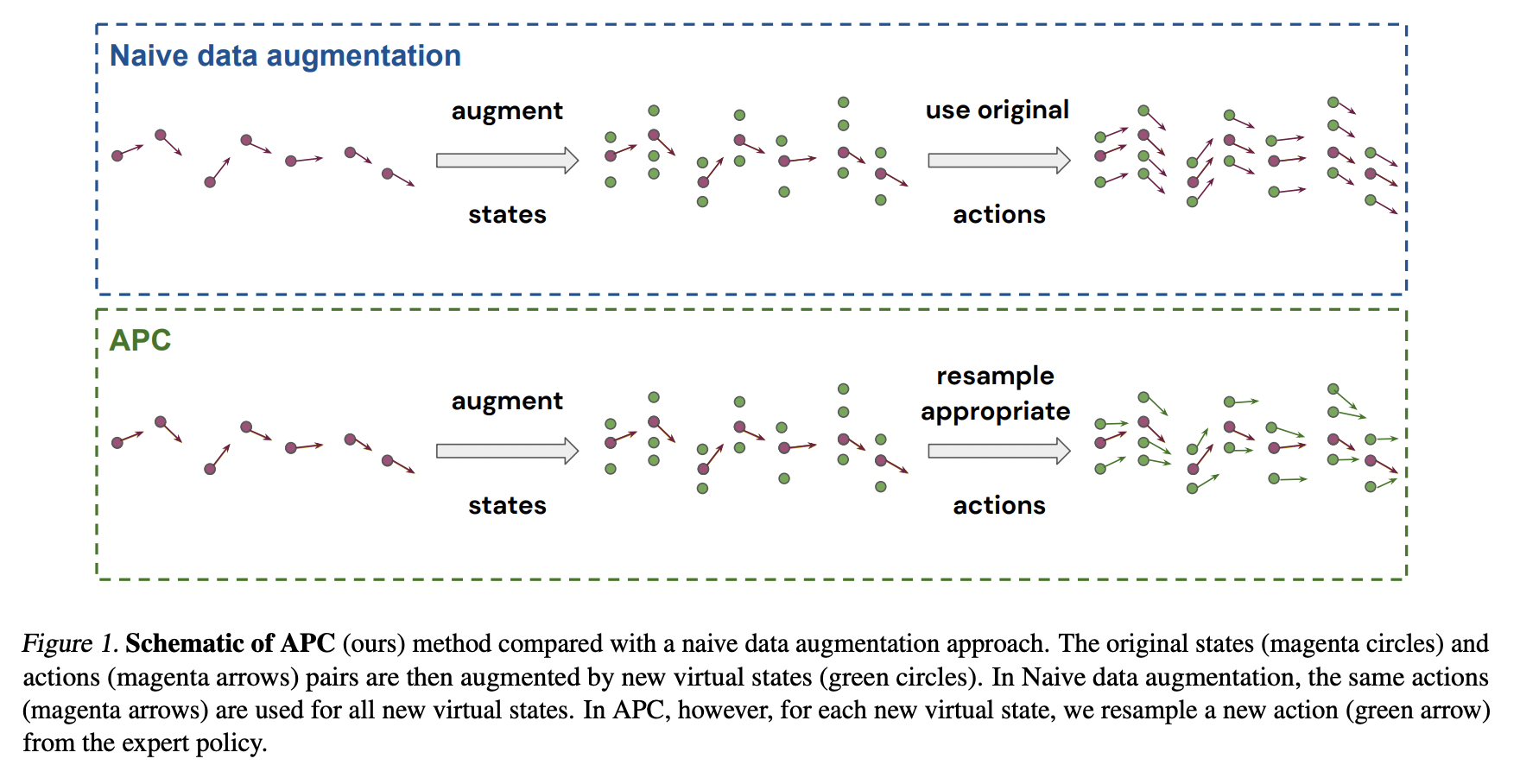
Behavior cloning is a versatile class of techniques that transfer behaviors from expert demonstrations in control or reinforcement learning (RL) situations. These include a human teleoperating the pertinent system following a trained student policy. However, behavioral cloning becomes less effective when an expert policy is also available and may be queried. A DeepMind research team suggests an easy-to-use, robust data augmentation method called Augmented Policy Cloning (APC) in their new paper, “Data Augmentation for Efficient Learning from Parametric Experts.” With the help of parametric specialists, this technique offers data-efficient learning for high-degrees-of-freedom control issues. Data efficiency is considerably increased by the suggested method in various control and reinforcement learning contexts.
Their research focuses on “policy cloning” settings, which use online or offline inquiries of an expert or expert policy to guide a student policy’s conduct. The suggested method approaches data augmentation as a typical RL problem. It uses extra data from an expert rollout in the vicinity of the sampled trajectories to identify policies that optimize the system’s anticipated discounted future reward. The setup for policy cloning naturally occurs in many issues, such as variations of behavior cloning, or it can be included in other algorithms like DAGGER, policy distillation, or KL-regularized RL.
For high-degrees-of-freedom control situations, a highly data-efficient behavior transfer from an expert to a student policy is attained. The Augmented Policy Cloning method drastically reduces the number of environment interactions necessary for successful expert cloning by inducing feedback sensitivity in a region around sampling trajectories using synthetic states. The researchers also show how, when policy cloning is included as a constituent part; their method prevails over several other, extensively used algorithms. The advantages of their strategy can also be emphasized in two primary contexts. Expert compression is the first setting or transferring to a student with fewer parameters. The second one involves the transmission from privileged specialists, in which the expert observes something distinct from the pupil.
The team conducted several experimental evaluations where they contrasted their suggested APC strategy to benchmarks like the naive approach. The experiments showed that APC considerably increased data efficiency in situations like DAgger, kickstarting, expert compression, cloning privileged experts, and behavioral cloning. Overall, DeepMind’s work presents a promising method for rapidly transferring expert behaviors by expanding the data on expert trajectories. The team believes that using a state model to generate and sample virtual states will allow for some fascinating research in the future.

This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Data augmentation for efficient learning from parametric experts'. All Credit For This Research Goes To Researchers on This Project. Check out the paper. Please Don't Forget To Join Our ML Subreddit
![]()
Asif Razzaq is an AI Journalist and Cofounder of Marktechpost, LLC. He is a visionary, entrepreneur and engineer who aspires to use the power of Artificial Intelligence for good.
Asif’s latest venture is the development of an Artificial Intelligence Media Platform (Marktechpost) that will revolutionize how people can find relevant news related to Artificial Intelligence, Data Science and Machine Learning.
Asif was featured by Onalytica in it’s ‘Who’s Who in AI? (Influential Voices & Brands)’ as one of the ‘Influential Journalists in AI’ (https://onalytica.com/wp-content/uploads/2021/09/Whos-Who-In-AI.pdf). His interview was also featured by Onalytica (https://onalytica.com/blog/posts/interview-with-asif-razzaq/).
Credit: Source link
Comments are closed.