Researchers Propose a Feature-Space Video Coding Network (FVC) by Performing all Major Operations in the Feature Space
The constant improvement in display technologies and emerging new media representation types such as 360-degree videos enabled videos to have better visual characteristics such as higher resolutions, color depths, etc. However, this improvement in video content also made their size higher and brought the need for better video compression.
Traditional video codecs are carefully designed by standardization committees. Each generation of video codec can improve the coding efficiency significantly compared to the previous version by introducing new coding tools and/or improving the existing ones.
Machine learning-based improvements for video compression have been an active research topic in recent years, thanks to the rapid advancement in the deep learning field. Deep learning-based approaches have been used as an improved alternative to certain video coding components, and their performance is note-worthy. However, the leading open question remains to be answered. Is it possible to achieve state-of-the-art compression performance by relying purely on an end-to-end machine-learning-based method? This is the question that FVC is trying to answer.
So far, most of the works on the machine-learning-based video compression field focused on pixel-level operations such as motion compensation for exploiting redundant information in the video. However, these pixel-level operations have certain drawbacks.

First of all, getting precise pixel-level optical flow data is challenging, particularly for videos with intricate non-rigid motion patterns. Second, even when the motion data is extracted with adequate accuracy, the pixel-level motion correction procedure may still result in unnecessary artifacts. Third, compressing leftover information at the pixel level is likewise a challenging issue.
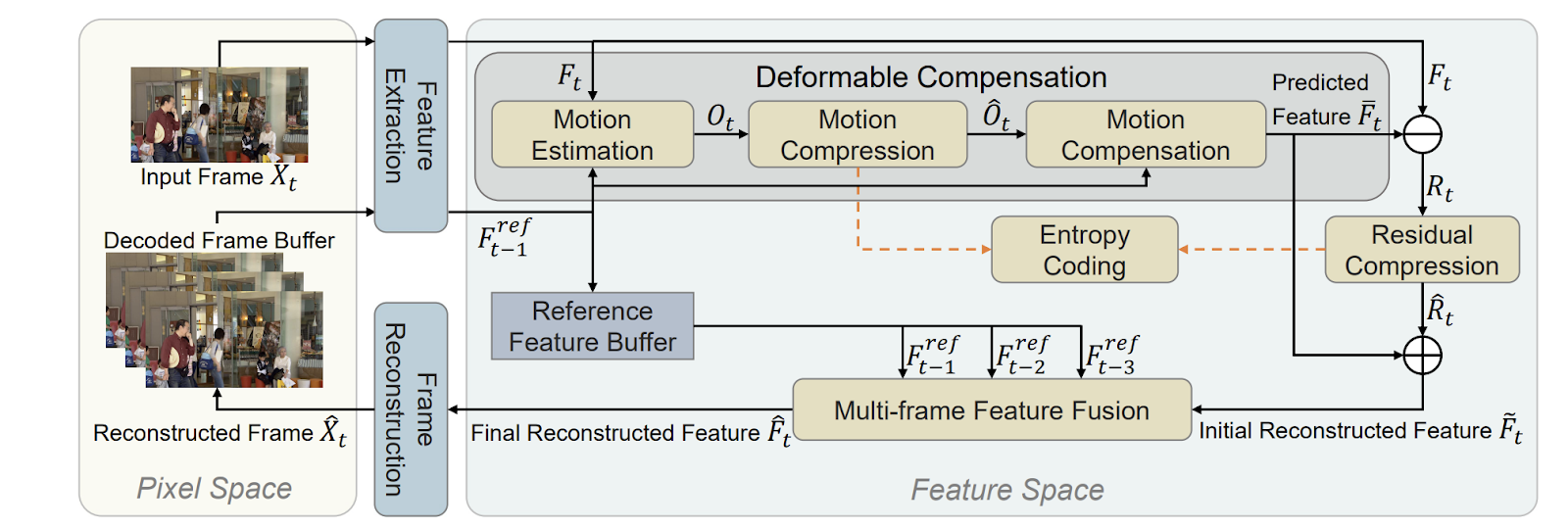
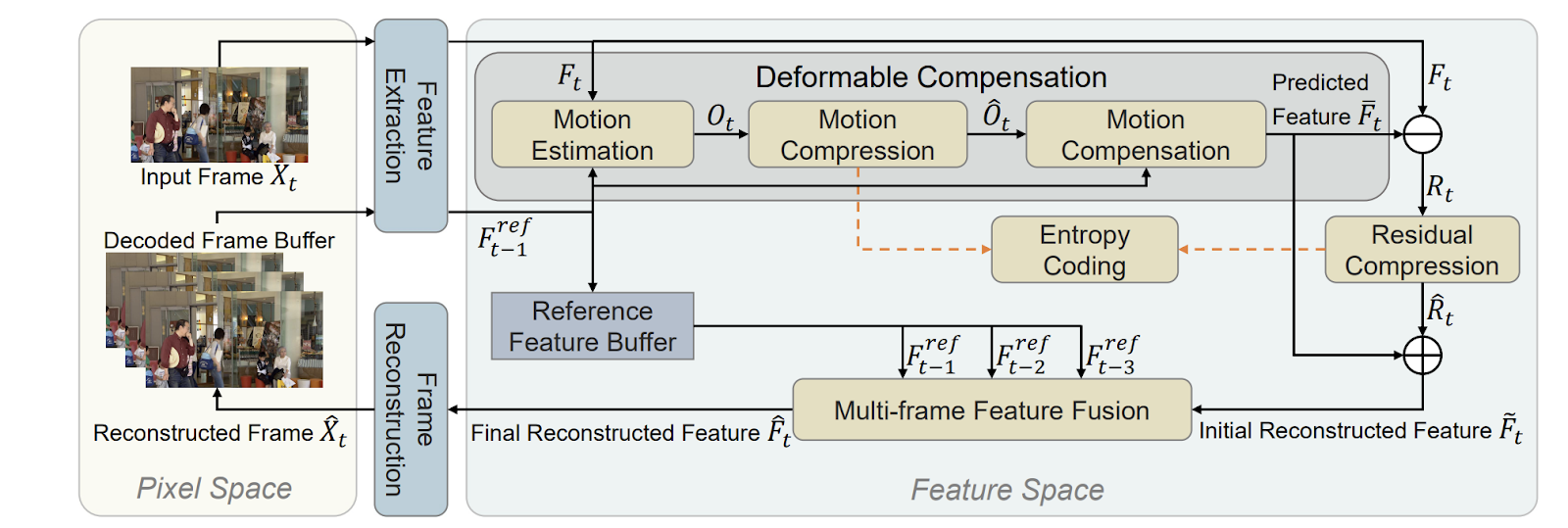
Therefore, FVC proposes to use a feature-space-based video coding method instead of relying on pixel-level operations. First, the motion estimation is done using the derived representations from two successive frames. These are the offset maps obtained from convolution kernels with deformable convolution.
The offset maps are then compressed using an auto-encoder-style network. The decoded offset maps are then employed in a deformable convolution process to provide a predicted feature for more precise motion compensation.
The residual feature between the original input and projected features is then compressed using another auto-encoder type network. To improve frame reconstruction, a multi-frame feature fusion module is used. It combines a collection of reference features from several prior frames.
By running all the operations on feature-space instead of pixel-level, FVC can improve video compression performance and reduce mistakes caused by inaccuracies in pixel-level processes like motion estimation. FVC achieves state-of-the-art performance on four benchmark datasets, including the widely used HEVC, UVG, VTL, and MCL-JCV, proving the efficacy of the suggested methodology. Moreover, the coding time of FVC is comparable to the reference HEVC implementation; therefore, it is possible to use it in practical scenarios.
This was a summary of the paper “FVC: A New Framework towards Deep Video Compression in Feature Space.” It is an interesting study for those working in the video domain. You can find relative links below if you want to learn more about FVC.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'FVC: A New Framework Towards Deep Video Compression in Feature Space'. All Credit For This Research Goes To Researchers on This Project. Check out the paper. Please Don't Forget To Join Our ML Subreddit
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.