Latest Computer Vision Research at Nanyang Technological University Introduces VToonify Framework for Style Controllable High-Resolution Video Toonification

Artistic portraits are everywhere in their everyday lives and in the creative sectors that inform the arts, social media avatars, movies, entertainment advertising, etc. With the development of deep learning technology, it is now possible to automatically transfer the portrait style from actual face photographs to produce high-quality artistic portraits. There are several effective methods for image-based style transfer, with various video content that has rapidly risen to the top of their social media feeds over the past several years. There is a rising requirement for innovative video editing techniques like portrait video style transfer to produce successful and entertaining films. Existing image-oriented approaches have several limitations when used with videos, which restricts their use in automatic portrait video stylization.

StyleGAN is a well-liked foundation for creating a portrait picture style transfer model since it can produce high-quality 1024 by 1024 faces with variable style management. This StyleGAN-based approach, also known as picture toonification, primarily involves encoding a natural face into the StyleGAN latent space. This is followed by applying the resulting style code to another StyleGAN that has been tweaked using the artistic portrait dataset to produce the face’s stylized version. The fact that StyleGAN creates pictures with aligned faces under a fixed size, which does not favor dynamic faces in films is a significant flaw in this framework. Incomplete faces and strange gestures are frequently the consequence of cropping and aligning faces in the video.
Portrait style transfer is hampered by faulty face encoding, leading to identity alteration and missing elements in stylized and reconstructed frames. This issue is known as StyleGAN’s “fixed-crop restriction.” Despite being suggested for unaligned faces, StyleGAN3 only supports a set picture size. Furthermore, a recent study found that encoding unaligned faces was more challenging than encoding aligned faces. Image-to-picture translation directly learns to transfer the input image from the actual face domain to the artistic portrait domain, in contrast to the StyleGAN-based architecture.
A fully convolutional encoder-generator architecture is frequently used to solve this issue, ignoring severe limitations on the picture size and face locations during the test phase. The framework often expands on the cycle consistency paradigm to learn bi-directional mappings since it lacks paired training data. However, the detailed mappings limit the models to a modest 256*256 picture size. There are also frameworks that utilize StyleGAN to change face attributes and provide paired data for training by using StyleGAN.

Researchers suggest a brand-new hybrid framework for video toonification called VToonify. To get beyond the fixed crop issue, they must first examine the translation equivariance in StyleGAN. They use the StyleGAN architecture for high-resolution style transfer, as shown below. However, they modify StyleGAN by removing its fixed-sized input feature and low-resolution layers to create a fully convolutional encoder-generator architecture. This supports various video sizes. The advantages of the StyleGAN-based framework and the image translation framework are combined by VToonify, as seen in the figure below, to produce a controlled high-resolution portrait video style transfer.
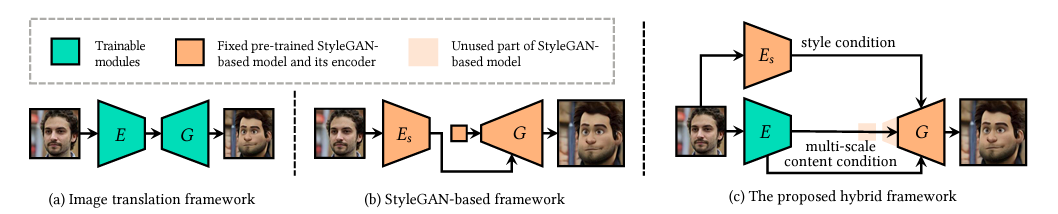
In contrast to the conventional image translation framework, VToonify integrates the StyleGAN model into the generator to combine the model and data. As a result, StyleGAN’s relaxed style modification features are inherited by VToonify. They can significantly reduce training time and difficulty by utilizing StyleGAN as the generator and simply training the encoder.
VToonify inherits DualStyleGAN’s flexible style control and modification of style degrees and further extends these characteristics to videos by modifying DualStyleGAN’s style control modules. This allows them to change the features of their encoder and intricately develop the data production and training objectives. In the experiment, they demonstrate that VToonify creates styled frames with a higher level of quality than the underlying frames while simultaneously better maintaining the input frame’s more delicate features. To conclude, the following are their significant contributions:
• Based on the translation equivariance in StyleGAN, they investigate the fixed-crop restriction and propose a comparable solution.
• They developed a fully convolutional VToonify framework. It supports unaligned faces, different video sizes, and customizable, high-resolution portrait style transfer.
• To provide collection-based and exemplar-based portrait video style transfer, they built VToonify atop the foundations of Toonify and DualStyleGAN.
• To train a video style transfer model efficiently and effectively, they construct a principled data-friendly training method and suggest an optical-flow-free flicker suppression loss for temporal consistency.
The PyTorch code implementation is available on GitHub along with sample input data and its output.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'VToonify: Controllable High-Resolution Portrait Video Style Transfer'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Asif Razzaq is an AI Journalist and Cofounder of Marktechpost, LLC. He is a visionary, entrepreneur and engineer who aspires to use the power of Artificial Intelligence for good.
Asif’s latest venture is the development of an Artificial Intelligence Media Platform (Marktechpost) that will revolutionize how people can find relevant news related to Artificial Intelligence, Data Science and Machine Learning.
Asif was featured by Onalytica in it’s ‘Who’s Who in AI? (Influential Voices & Brands)’ as one of the ‘Influential Journalists in AI’ (https://onalytica.com/wp-content/uploads/2021/09/Whos-Who-In-AI.pdf). His interview was also featured by Onalytica (https://onalytica.com/blog/posts/interview-with-asif-razzaq/).
Credit: Source link
Comments are closed.