Meta AI Introduces ‘Make-A-Video’: An Artificial Intelligence System That Generates Videos From Text
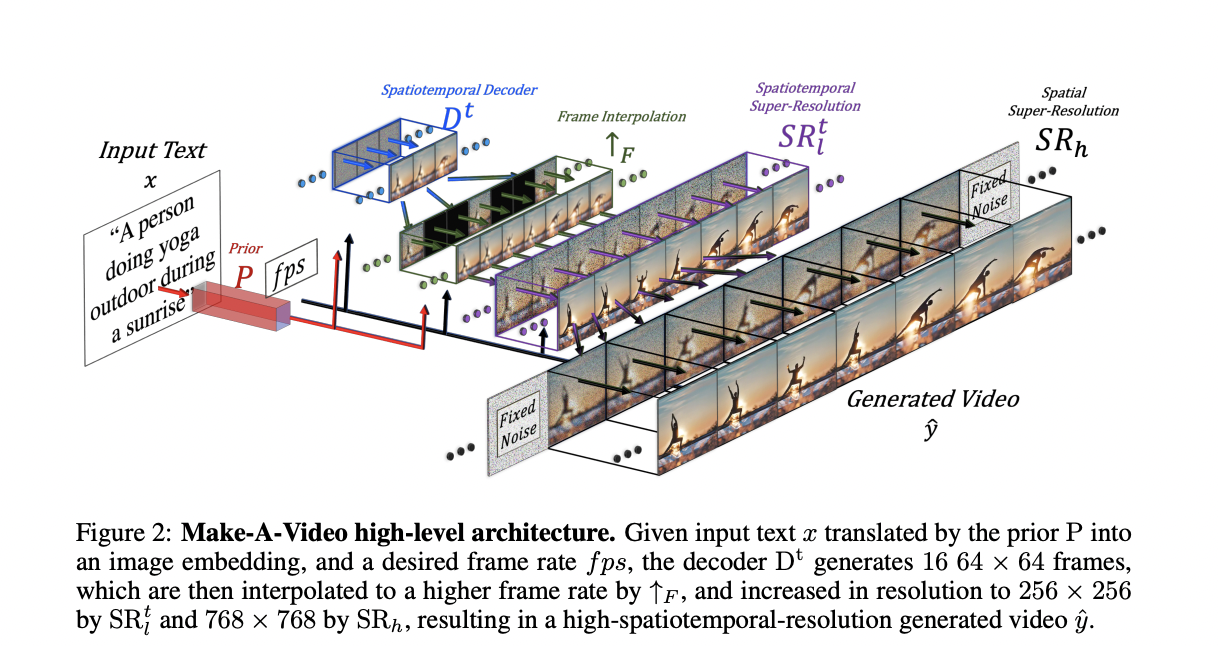
Make-A-Video is a new AI technology that enables individuals to convert text suggestions into brief, high-quality video snippets. Make-A-Video advances recent developments in Meta AI’s research on generative technologies. A multimodal generative AI technique allows users more control over the AI-generated material they create. Make-A-Video is the follow-up to that announcement. With Make-A-Scene, they showed users how to use words, lines of text, and freeform sketches to produce lifelike graphics and artwork fit for picture books.
These motives served as inspiration for their idea, Make-A-Video. Make-A-Video uses Models T2I to understand how text and the visual environment correspond and employ unsupervised learning. To learn realistic motion, use unlabeled (unpaired) video data. Make-A-Video produces videos collectively without utilizing coupled text-video data from text.
The Internet has enabled the recent advances in Text-to-Picture (T2I) modeling by facilitating the collection of billions of (alt-text, image) pairings from HTML pages. However, as a comparable-sized (text, video) dataset cannot be readily gathered, replicating this achievement for videos is constrained. Since there are already Text-to-Video (T2V) models, it would be pointless to train them from scratch.
Some models can produce images. Additionally, networks can learn through unsupervised learning.

Natural language processing (NLP) has made progress in recent years
Pre-trained models in this manner produce far better performance than those only trained in a controlled way.
It has the potential to give creators and artists access to new opportunities. The algorithm learns how the world moves from video footage without any accompanying text and how the world looks from text-image pairs. They’re providing the specifics in a research paper and want to share a demo experience as part of our ongoing dedication to open science.
The researcher should take care when creating new generative AI systems like this. Make-A-Video employs publicly accessible datasets, increasing the research’s transparency level. They openly disclose their generative AI research and findings to the public for their input. They will keep using their ethical AI framework to improve and develop our strategy for dealing with this new technology.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'MAKE-A-VIDEO: TEXT-TO-VIDEO GENERATION WITHOUT TEXT-VIDEO DATA'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, project and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
Ashish kumar is a consulting intern at MarktechPost. He is currently pursuing his Btech from the Indian Institute of technology(IIT),kanpur. He is passionate about exploring the new advancements in technologies and their real life application.
Credit: Source link
Comments are closed.