Researchers at Tel Aviv University Develop State of the Art Human Motion Diffusion Model Trained on Lightweight Resources
The production of human motion is a critical job in computer animation, with applications ranging from gaming to robots. It is a tricky topic to work on for various reasons, including the extensive range of conceivable movements and the difficulty and cost of gathering high-quality data. Another fundamental issue is data labeling in the newly developing text-to-motion environment, in which motion is created from natural language. For example, the term “kick” can apply to both a soccer kick and a Karate kick. Simultaneously, given a particular kick, there are several ways to describe it, from how it is executed to the feelings it evokes, resulting in many difficulties. Current techniques have shown success in the field, displaying convincing text-to-motion mapping.
All of these techniques, however, continue to constrain the learned distribution because they primarily use auto-encoders or VAEs (implying a one-to-one mapping or a normal latent distribution, respectively). In this regard, diffusion models are a superior choice for human motion production since they are devoid of target distribution assumptions and are known to express well the many-to-many distribution matching challenge they have discussed. Diffusion models are a generative method that is gaining popularity in the computer vision and graphics communities. Recent diffusion models have demonstrated picture quality and semantics advancements when trained for a conditioned generation. These models’ competency has also been shown in other areas, such as movies and 3D point clouds.
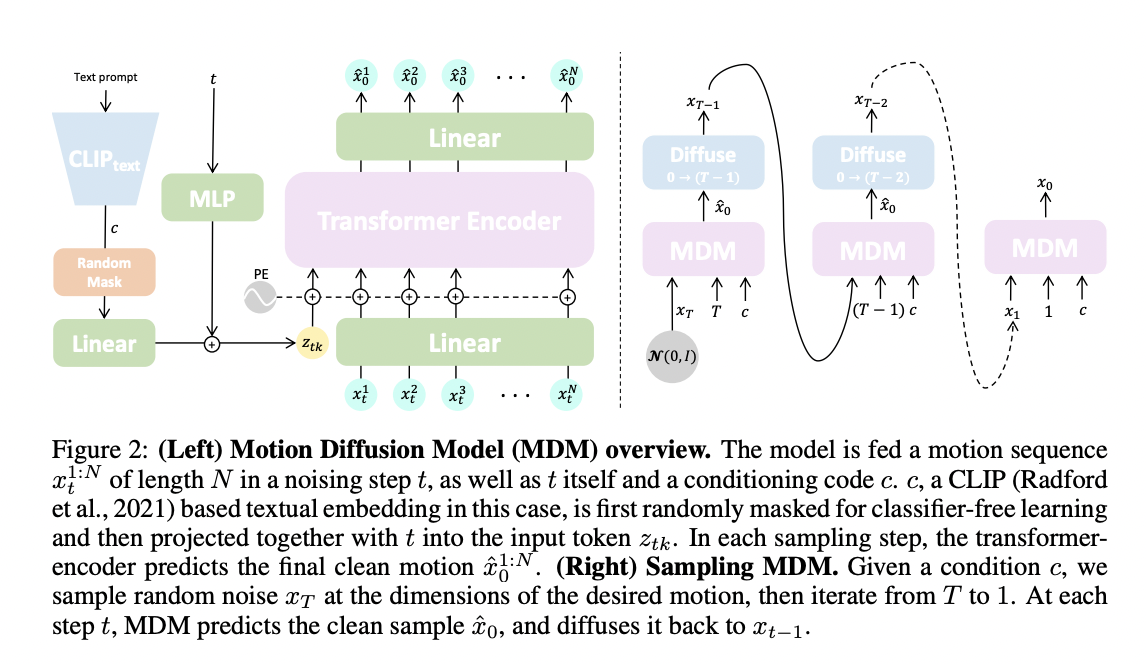
The difficulty with such models is that they are notoriously resource-intensive and difficult to govern. In this study, they present the Motion Diffusion Model (MDM), a thoroughly modified diffusion-based generative model for the human motion domain. Because it is diffusion-based, MDM benefits from the domain’s intrinsic many-to-many expression, as seen by the ensuing motion quality and variety (Figure 1). Furthermore, MDM leverages previously known insights in the motion-generating area, allowing it to be substantially lighter and more controlled. For starters, rather than the common U-net backbone, MDM is transformer-based.
Their architecture is lightweight and better suits the temporal and non-spatial character of motion data (represented as a collection of joints). Learning with geometric losses receives a lot of attention in motion generation research. Some, for example, limit the velocity of the motion to prevent jitter or consider foot sliding, mainly using designated words. In line with these findings, they demonstrate that using geometric losses in diffusion enhances generation. The MDMframework has a general architecture that allows for many types of conditioning.

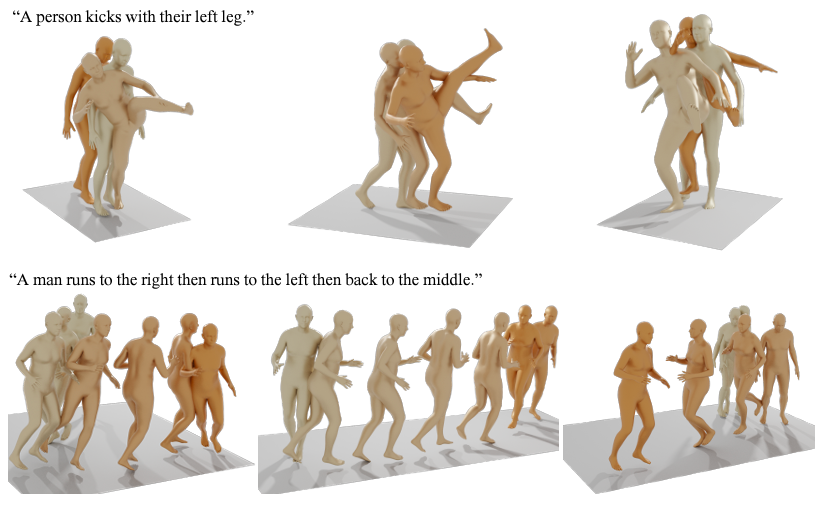
On the popular HumanAct12 and UESTC benchmarks, MDM exceeds the state-of-the-art in action-to-motion, despite being mainly built for this job. They demonstrate three different tasks: text-to-motion, action-to-motion, and unconditioned creation. They train the model without a classifier, allowing them to trade off diversity for fidelity and sample from the same model conditionally and unconditionally. Their model creates coherent movements (Figure 1) that outperform the HumanML3D and benchmarks in the text-to-motion test. Furthermore, according to their user survey, human assessors prefer their created activities to natural motions 42% of the time.
Finally, they show completion as well as editing. They set a motion prefix and suffix using diffusion image-inpainting and utilize their model to fill in the gaps. When done under a textual condition, MDM is guided to fill the gap with a specified motion that preserves the semantics of the original input. They also exhibit a semantic modification of select body parts without altering the others by executing inpainting in the joint space rather than temporally.
Overall, they present the Motion Diffusion Model. This motion framework delivers state-of-the-art quality in various motion production applications while needing only three days of training on a single mid-range GPU. It enables geometric losses that are not minor in the diffusion context but critical in the motion domain. It combines cutting-edge creative capability with well-thought-out domain expertise. A detailed demonstration of the paper can be found on their GitHub site along with which the PyTorch implementation of the paper is also available.
This Article is written as a research summary article by Marktechpost Staff based on the research preprint-paper 'HUMAN MOTION DIFFUSION MODEL'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, github link and project. Please Don't Forget To Join Our ML Subreddit
![]()
Asif Razzaq is an AI Journalist and Cofounder of Marktechpost, LLC. He is a visionary, entrepreneur and engineer who aspires to use the power of Artificial Intelligence for good.
Asif’s latest venture is the development of an Artificial Intelligence Media Platform (Marktechpost) that will revolutionize how people can find relevant news related to Artificial Intelligence, Data Science and Machine Learning.
Asif was featured by Onalytica in it’s ‘Who’s Who in AI? (Influential Voices & Brands)’ as one of the ‘Influential Journalists in AI’ (https://onalytica.com/wp-content/uploads/2021/09/Whos-Who-In-AI.pdf). His interview was also featured by Onalytica (https://onalytica.com/blog/posts/interview-with-asif-razzaq/).
Credit: Source link
Comments are closed.