Baidu Proposes ERNIE-VIL 2.0, a Multi-View Contrastive Learning Framework That Aims To Acquire A More Robust Cross-Modal Representation By Concurrently Building Intra-Modal And Inter-Modal Correlations Between Distinct Views
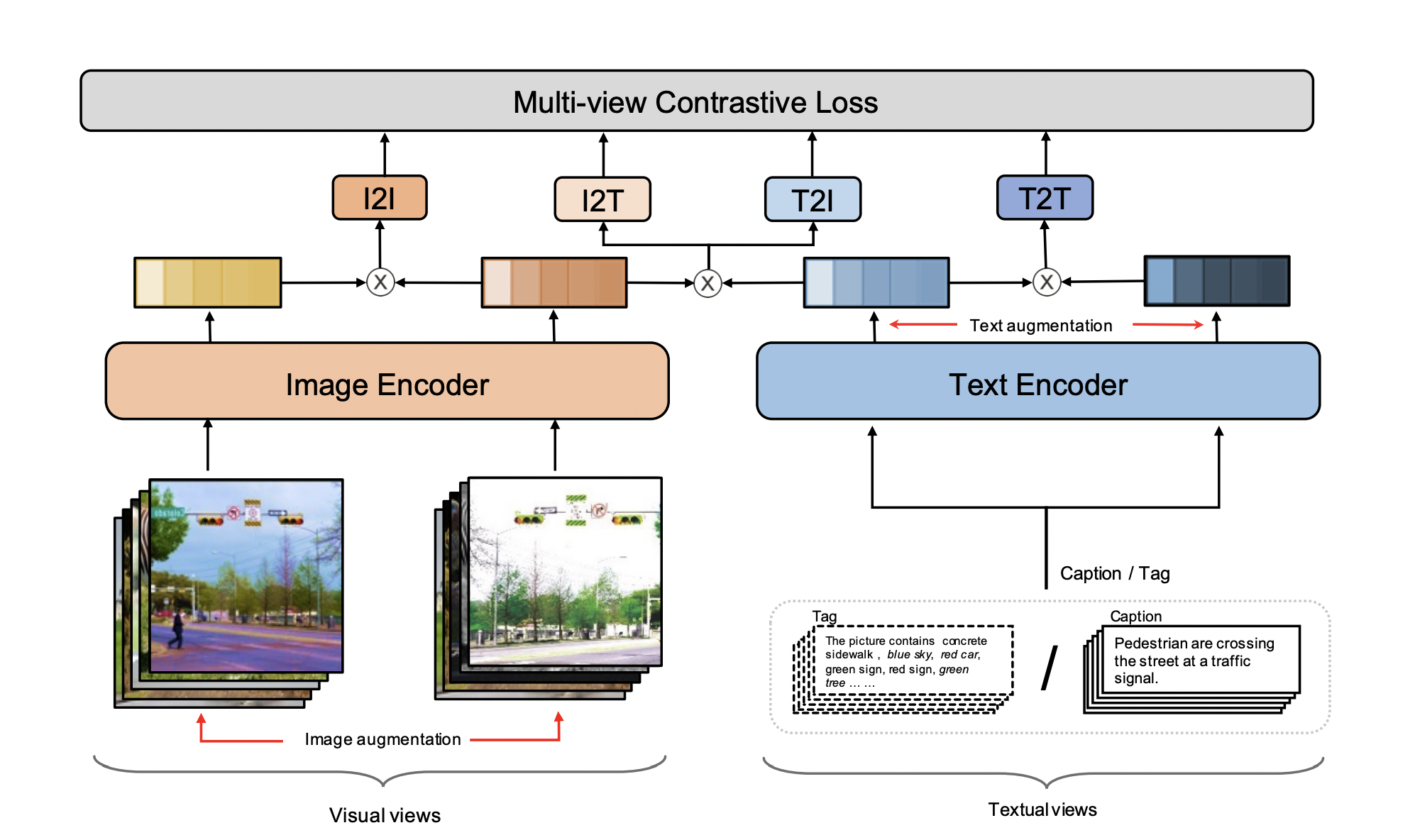
Vision-Language Pre-training (VLP) models have made significant progress on several cross-modal tasks, such as Visual Question Answering (VQA) and cross-modal retrieval, during the previous two years. The majority of prior efforts based on cross-modal transformer encoders concentrate on building several proxy pre-training tasks (e.g., Masked Language Modeling (MLM) and Masked Region Modeling (MRM)) to learn joint cross-modal representation. On the other hand, cross-modal attention layers in the encoder attempt to fuse different token-level visual/textual characteristics to understand the joint representation with massive interactions, resulting in high computing costs for real-world systems such as the online cross-modal retrieval system.
Current dual-encoder architecture-based research employs a compute-efficient framework with light cross-modal interaction, yielding equivalent performance on vision-language tasks by training on large-scale image-text pairings to solve this constraint. However, because the established inter-modal correlation only depends on a single view for each modality, they attempt to develop the cross-modal alignment via single-view contrastive learning. Indeed, the intra-modal correlation that they overlook has the potential to improve the single-modal representation and contribute to the development of a superior cross-modal alignment. Furthermore, there are frequently weak correlations in noisy web-crawled image-text pairings with intrinsic visual/textual viewpoints, expanding the cross-modal semantic gap.
They offer ERNIE-ViL 2.0, a multi-view contrastive learning framework for cross-modal retrieval, intending to learn robust cross-modal representation by modeling inter-modal and intra-modal correlations between distinct views. Unlike traditional single-view contrastive learning approaches, multi-view contrastive learning learns on both intra-modal and inter-modal correlations. Similarly, CMC employs multi-view contrastive knowledge for visual representation learning, resulting in a more robust representation. Their approach creates numerous visual/textual viewpoints to improve representations inside and across modalities.
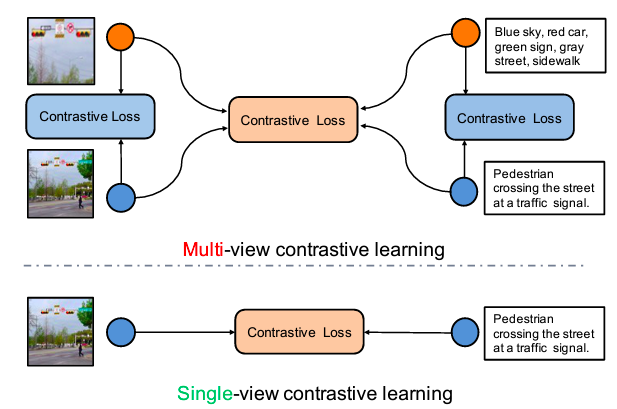
Contrastive learning with several perspectives vs. single-view contrastive learning Single-view contrastive learning relies solely on a single inter-modal association between a visual and textual perspective. Through the construction of numerous possible perspectives, multi-view contrastive learning might learn about many types of intra-modal and inter-modal correlations.
They specifically generate image-image pairings and text-text pairs for intra-modal contrastive view pairs to improve representation with each modality. In addition to the intrinsic visual/textual views, they generate object tag sequences as a unique textual view to lessen the impacts of noisy multi-modal data and facilitate vision-language alignment learning. They train an English model on 29M publically accessible datasets using the dual-encoder architecture and get competitive performance on cross-modal retrieval tasks. They increased the size of the training datasets to 1.5 billion Chinese image-text pairings, yielding considerable gains over earlier SOTA results on Chinese cross-modal retrieval.

Overall, they divide their contributions into three categories:
1. We offer the first multi-view learning framework for cross-modal retrieval that uses several perspectives to produce view-invariant and resilient cross-modal representations.
2. They offer object tags as exceptional textual views, thereby closing the semantics gap between image and text and making cross-modal alignment on large-scale noisy data easier to learn.
3. Using only noisy publically available datasets, create a credible and comparable benchmark for English cross-modal retrieval. Furthermore, their model obtains SOTA performance on Chinese cross-modal recovery after being trained on 1.5 billion Chinese image-text pairings.
Official implementations for numerous ERNIE-family pre-training models covering subjects such as Language Understanding & Generation and Multimodal Understanding & Generation are available on GitHub.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'ERNIE-VIL 2.0: MULTI-VIEW CONTRASTIVE LEARNING FOR IMAGE-TEXT PRE-TRAINING'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Content Writing Consultant Intern at Marktechpost.
Credit: Source link
Comments are closed.