This Google AI’s New Audio Generation Framework, ‘AudioLM,’ Learns To Generate Realistic Speech And Piano Music By Listening To Audio Only
Audio signals, whether human speech, musical composition, or ambient noise, entail different levels of abstraction. Prosody, syntax, grammar, and semantics are a few ways speech can be dissected and examined.
The problem of generating well-organized and consistent audio sequences at all three levels has been addressed by combining audio with transcriptions that can direct the generative process, such as text transcripts for speech synthesis or MIDI representations for the piano. However, this method falls short when attempting to represent non-transcribed features of audio, such as speaker qualities necessary to assist people with speech difficulties.
Language models have shown they can model high-level, long-term structures for various content types. “Textless NLP” has recently been advanced concerning unconditioned speech production. In particular, without textual annotations, a Transformer trained on discretized speech units may generate meaningful speech. The model is only trained on clean speech, and the synthesis is only possible with a single speaker. Thus acoustic diversity and quality are still constrained.
A new Google research introduces a new framework called AudioLM for audio production that can learn to make realistic speech and piano music just by listening to audio. AudioLM outperforms earlier systems and pushes the boundaries of audio production with applications in speech synthesis and computer-assisted music because of its long-term consistency (e.g., syntax in speech) and high fidelity. Using the same AI principles that guided the development of our other models, we have created a system to detect AudioLM-generated synthetic sounds.

AudioLM uses two distinct types of audio tokens to solve these problems. In the first step, w2v-BERT, a self-supervised audio model, is used to extract semantic tokens. These tokens heavily downsample the audio signal to model lengthy audio sequences while capturing local dependencies and long-term global structure.
It is possible to achieve high audio quality and long-term consistency by training a system to generate semantic and acoustic tokens. A low level of fidelity is present in the reconstructed audio when using these tokens. To get over this restriction, the team employs a SoundStream neural codec to generate acoustic tokens that capture the nuances of the audio waveform and permit accurate synthesis.
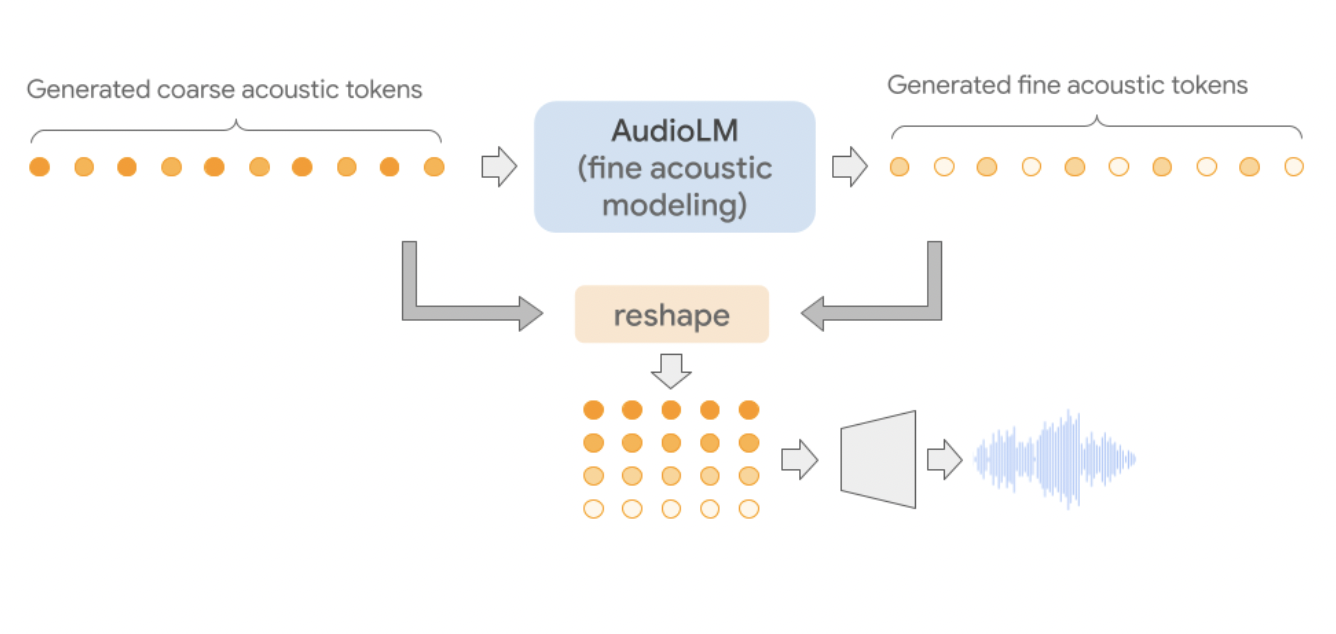
AudioLM is a music-only model that undergoes training using only audio. To represent an audio sequence hierarchically, from semantic tokens to fine acoustic tokens, AudioLM links together various Transformer models. In the same way, a text language model is taught, each stage learns to predict the next token based on the tokens that came before them.
- In the first phase, semantic tokens are used to model the overall structure of the audio file.
- Second, the complete semantic token sequence is fed and the previous coarse acoustic tokens into the coarse acoustic model as conditioning, allowing the model to predict the next set of tokens. In this stage, acoustic qualities are modeled, such as those of the speaker in a speech or the sound of a musical instrument.
- The final audio is refined by applying the fine acoustic model to the coarse acoustic tokens. Afterward, they recreated an audio waveform by feeding a series of acoustic tokens into a SoundStream decoder. Once trained, AudioLM may be conditioned on short audio clips, allowing it to produce seamless loops.
To verify the findings, human raters listened to audio samples. They judged whether they were hearing a natural continuation of a recorded human voice or a synthetic one generated by AudioLM. Their findings show a success percentage of 51.2%. This means that the ordinary listener will have difficulty telling the difference between AudioLM-generated speech and real human speech.
The researchers investigated the possibility that people might mistake the brief speech samples generated by AudioLM for actual human speech and took measures to reduce this risk. To do this, they developed a classifier that can accurately identify AudioLM-generated synthetic speech (98.6% of the time). This demonstrates how simple audio classifiers can readily identify continuations produced by AudioLM, despite their (near) indistinguishability to some listeners. This is an essential first step in securing AudioLM from abuse, and future work may investigate technologies like audio “watermarking” to further strengthen security.
The study’s authors believe that their work will pave the way for future applications of AudioLM to a wider variety of audio and the incorporation of AudioLM into an encoder-decoder framework for conditioned tasks like text-to-speech and speech-to-speech translation.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'AudioLM: a Language Modeling Approach to Audio Generation'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, project and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.