Amazon Open-Sources ‘MINTAKA,’ a Complex, Natural, and Multilingual Question-Answering (QA) Dataset Composed of 20,000 Question-Answer Pairs
Question answering is to learn predicting answers to a given question using machine learning. While many cutting-edge question-answering models perform well when asked simple questions, complicated questions continue to be challenging. The lack of datasets is one of the causes. Most currently available QA datasets are enormous but simple, complex but tiny, or vast and complicated but artificially manufactured, making them less natural. Most QA datasets are also only available in English.
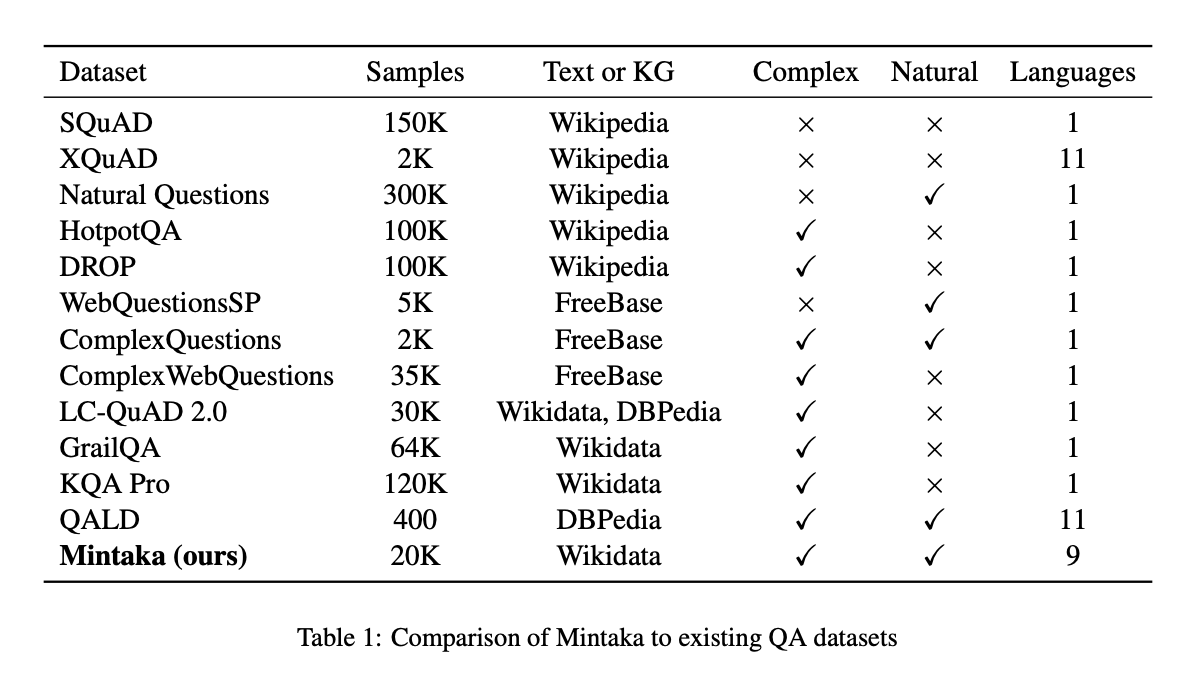
Researchers at amazon have released datasets for complex and multilingual question answering. With 20,000 questions collected in English and professionally translated into eight languages—Arabic, French, German, Hindi, Italian, Japanese, Portuguese, and Spanish—Mintaka is a sizable, complex, naturally occurring, and multilingual question-answer dataset. By connecting elements in the question and response text to Wikidata IDs.
The researchers conducted an examination on MTurk using four comparative datasets: KQA Pro, ComplexWebQuestions (CWQ), DROP, and ComplexQuests to examine how Mintaka compares to earlier QA datasets in terms of naturalness (CQ). Five questions, one from each dataset, were presented to the workforce, and they were asked to rank them from 1 (least natural) to 5. (most natural). Mintaka performed better on average than the other datasets in terms of naturalness. This demonstrates that Mintaka questions are seen as being more natural compared to automatically generated or passage-constrained questions.
Eight baseline QA models that were trained with Mintaka were also tested. The language model T5 for Closed Book QA performed the best, scoring 38% hits@1. The baselines demonstrate that Mintaka is a challenging dataset, and there is plenty of space to enhance the model design and training methods. Due to its size, complexity, organically produced questions, and multilingual, Mintaka fills a significant need in QA databases. With the introduction of Mintaka, researchers hope to inspire academics to keep working on expanding the languages and complexity of questions that question-answering models can handle.

This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Mintaka: A Complex, Natural, and Multilingual Dataset for End-to-End Question Answering'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, github link and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
Prathvik is ML/AI Research content intern at MarktechPost, he is a 3rd year undergraduate at IIT Kharagpur. He has a keen interest in Machine learning and data science.He is enthusiastic in learning about the applications of Machine learning in different fields of study.
Credit: Source link
Comments are closed.