Google AI Introduces Unified Language Learner (UL2 20B): A Breakthrough Language Pre-Training Paradigm
One of the overarching goals of machine learning (ML) research is the development of methods for creating models that can accurately interpret and produce natural language for use in practical settings.
There are two main approaches for creating and training language models; autoregressive decoder-only architectures and corruption-based encoder-decoder architectures. While T5-like models excel at supervised fine-tuning tasks, they are not as successful in learning in the context of a few examples. Alternatively, autoregressive language models may not perform ideally on fine-tuning tasks, but they excel in open-ended generation and prompt-based learning. Therefore, the possibility exists to develop a uniform, efficient framework for pre-training models.
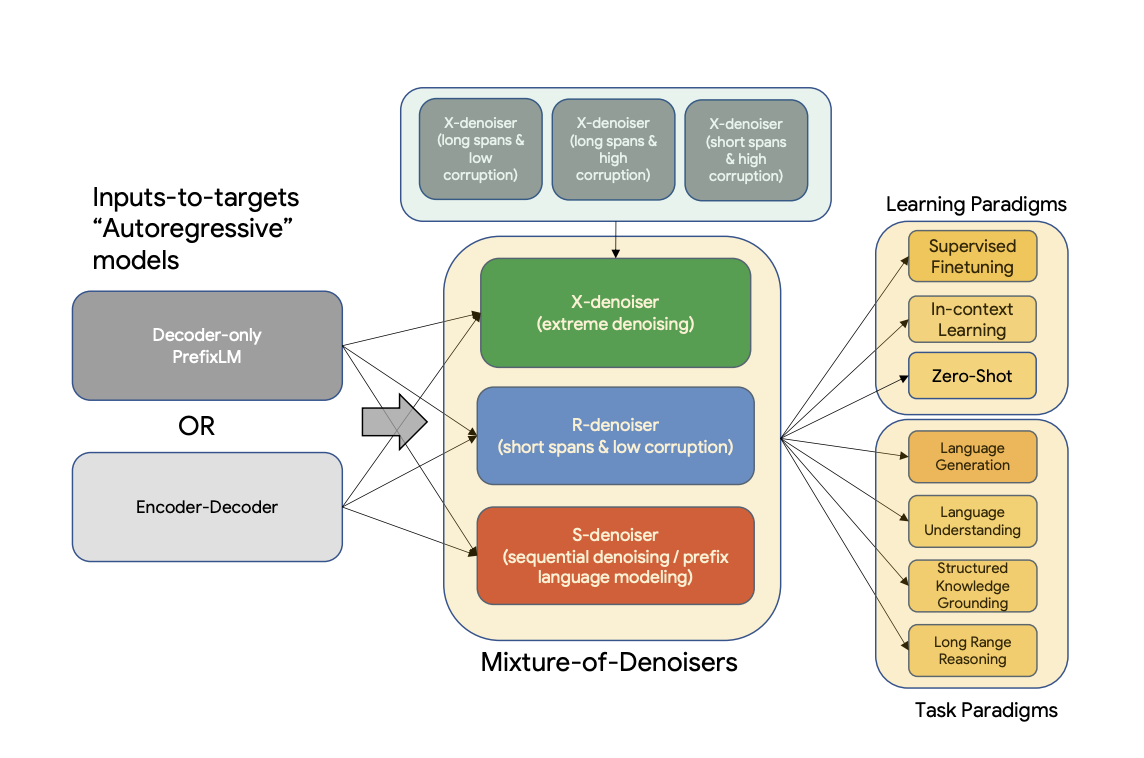
Unified Language Learner (UL2), the product of recent Google research, is a breakthrough language pre-training paradigm that boosts the effectiveness of language models in every given setting and data set. To train language models, UL2 casts a variety of goal functions as denoising tasks, where the model must reconstruct lost portions of the input.
Standard Causal Language modeling objective (CausalLM) only detects tokens in the target output because it is trained to predict whole sequence lengths. To alter this procedure, the prefix language modeling goal (PrefixLM) randomly selects an input “prefix” of k tokens from the given tokenized text. To train the model to anticipate the masked spans, the span corruption objective first hides them from the inputs. We use the model’s capacity for extracting supervision signals from a single input to quantify the example efficiency of each objective.
UL2 takes advantage of the benefits of each target function by providing a framework that generalizes over them all, facilitating the capacity to reason and unify shared pre-training goals. In this setting, training a language model entails primarily mastering the skill of transforming one set of input tokens into another set of target tokens. Then, the aforementioned objective functions are reduced to various input and output token generators.
Models can be trained in the UL2 framework using a wide variety of pre-training tasks, allowing the model to acquire skills and inductive bias benefits from each. Compared to a span corruption-only T5 model, the mixture-of-denoisers objective can significantly enhance the model’s prompt-based learning potential. By being trained on the combination, the model can better utilize its strengths while compensating for its limitations across various tasks.
During its training, UL2 employs a trifecta of denoising tasks:
- R-denoising: Regular span corruption, which mimics the common T5 span corruption aim
- X-denoising: Extreme span corruption
- S-denoising: Smooth span corruption
During pre-training, the researchers take a small subset of the possible denoising jobs (i.e., various combinations of the R, X, and S-denoisers) and set up the input and target accordingly based on the user-specified ratios. Then, a paradigm token ([R], [X], or [S]) is attached to the input to denote the type of denoising to be performed.
The researchers used SuperGLUE performance metrics to fine-tune the model.
UL2 is an impressive contextual learner who does well with few-shot and CoT prompting. On the XSUM summarising dataset, the team evaluated UL2 against various state-of-the-art models (such as T5 XXL and PaLM) for few-shot prompting. Their findings show that UL2 20B performs better than PaLM and T5.
They also demonstrate that UL2 20B, both publicly available and several times smaller than previous models that employ chain-of-thought prompting, can be used to accomplish reasoning via CoT prompting. This paves the way for academics to study CoT prompting and reasoning in an open and manageable setting.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'UL2: Unifying Language Learning Paradigms'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, github and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
Asif Razzaq is an AI Journalist and Cofounder of Marktechpost, LLC. He is a visionary, entrepreneur and engineer who aspires to use the power of Artificial Intelligence for good.
Asif’s latest venture is the development of an Artificial Intelligence Media Platform (Marktechpost) that will revolutionize how people can find relevant news related to Artificial Intelligence, Data Science and Machine Learning.
Asif was featured by Onalytica in it’s ‘Who’s Who in AI? (Influential Voices & Brands)’ as one of the ‘Influential Journalists in AI’ (https://onalytica.com/wp-content/uploads/2021/09/Whos-Who-In-AI.pdf). His interview was also featured by Onalytica (https://onalytica.com/blog/posts/interview-with-asif-razzaq/).
Credit: Source link
Comments are closed.