Researchers At Stanford Have Developed An Artificial Intelligence (AI) Approach Called ‘MEND’ For Fast Model Editing At Scale
Large models have improved performance on a wide range of modern computer vision and, in particular, natural language processing problems. However, issuing patches to adjust model behavior after deployment is a significant challenge in deploying and maintaining such models. Because of the distributed nature of the model’s representations, when a neural network produces an undesirable output, making a localized update to correct its behavior for a single or small number of inputs is difficult. A large language model trained in 2019 might assign a higher probability to Theresa May than Boris Johnson when prompted. Who is the Prime Minister of the United Kingdom?
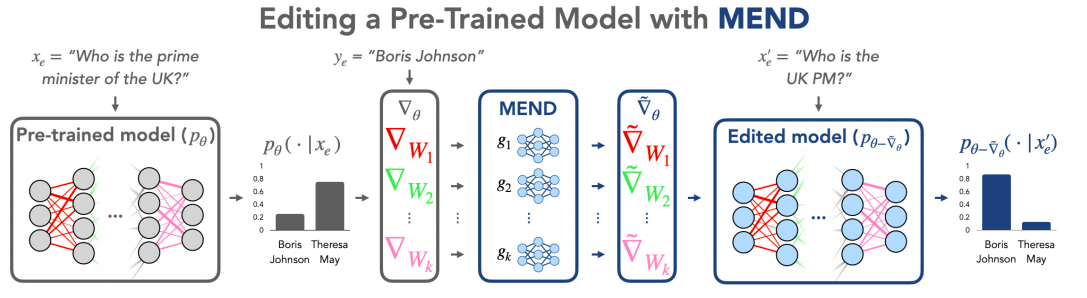
An ideal model editing procedure would be able to quickly update the model parameters to increase the relative likelihood of Boris Johnson while not affecting the model output for unrelated inputs. This procedure would yield edits with reliability, successfully changing the model’s work on the problematic input (e.g., Who is the Prime Minister of the United Kingdom? ); locality, affecting the model’s output for unrelated inputs (e.g., What sports team does Messi play for? ); and generality, generating the correct output for inputs related to the edit input (e.g., Who is the Prime Minister of the United Kingdom?). Making such edits is as simple as fine-tuning with a new label on the single example to be corrected. However, fine-tuning on a single sample tends to overfit, even when the distance between the pre-and post-fine-tuning parameters is limited.
Overfitting causes both locality and generality failures. While fine-tuning the edit example and ongoing training on the training set improves locality, their experiments show that it still needs more generality. Furthermore, it necessitates continuous access to the entire training set during testing and is more computationally demanding. Recent research has looked into methods for learning to make model edits as an alternative. Researchers present a bi-level meta-learning objective for determining a model initialization for which standard fine-tuning on a single edit example yields valuable modifications.
While practical, the computational requirements of learning such an editable representation make scaling to large models difficult, where fast, effective edits are most required. Researchers describe a computationally efficient learning-based alternative, but their experiments fail to edit huge models. As a result, they devise a method for producing reliable, local, and general edits while efficiently scaling to models with over 10 billion parameters. When given the standard fine-tuning gradient of a given correction as input, their approach trains lightweight model editor networks to produce edits to a pre-trained model’s weights, leveraging the gradient as an information-rich starting point for editing.
Because gradients are three-dimensional objects, directly parameterizing a function that maps a gradient to a new parameter update is prohibitively expensive. A naive implementation of a single d d weight matrix requires a mapping R(d2) -> R(d2), which is impractical for large models with d ~ 104. Their approach, however, can learn a function g: R(d) -> R(d) by decomposing this gradient into its rank-1 outer product form. Model Editor Networks with Gradient Decomposition, or MEND, is the name given to their approach. MEND parameterizes these gradient mapping functions as MLPs with a single hidden layer, with fewer parameters than the models they edit. Regardless of pre-training, MEND can be applied to any pre-trained model.
This work’s main contribution is a scalable algorithm for fast model editing that can edit huge pre-trained language models by leveraging the low-rank structure of fine-tuning gradients. They conduct empirical evaluations on various language-related tasks and transformer models, demonstrating that MEND is the only algorithm capable of consistently editing the most significant GPT-style and T5 language models. Finally, their ablation experiments illustrate the impact of MEND’s key components, demonstrating that MEND variants are likely to scale to models with hundreds of billions of parameters. The code implementation is freely available on GitHub.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'MEND: Fast Model Editing at Scale'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, code and project.
Please Don't Forget To Join Our ML Subreddit
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.