Google AI Researchers Propose An Artificial Intelligence-Based Method For Learning Perpetual View Generation of Natural Scenes Solely From Single-View Photos
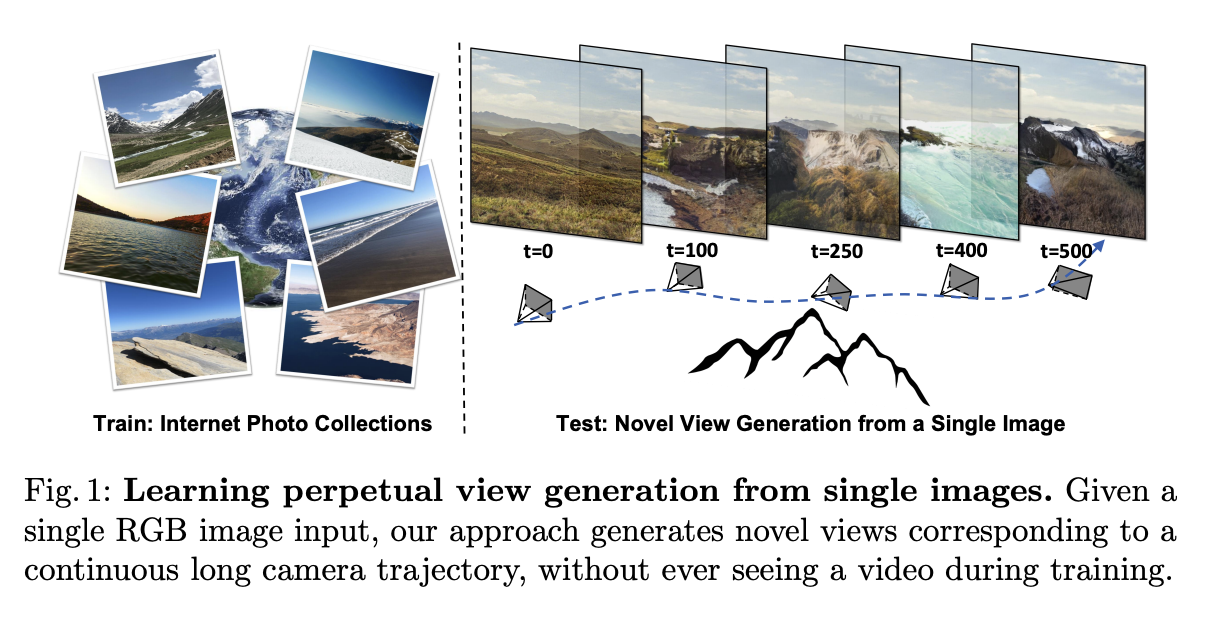
Our earth is gorgeous, with majestic mountains, breathtaking seascapes, and tranquil forests. Flying past intricately detailed, three-dimensional landscapes, picture yourself taking in this splendor as a bird might. Is it possible for computers to learn to recreate this kind of visual experience? However, current techniques that combine new perspectives from photos typically only allow for a small amount of camera motion. Most earlier research can only extrapolate scene content within a constrained range of views corresponding to a subtle head movement.
In a recent research by Google Research, Cornell Tech, and UC Berkeley, they presented a technique for learning to create unrestricted flythrough videos of natural situations beginning with a single view, where this capacity is learned through a collection of single images, without the need for camera poses or even several views of each scene. This method can take a single image and construct long camera trajectories of hundreds of new views with realistic and varied contents during testing, despite never having seen a video during training. This method contrasts with the most recent cutting-edge supervised view generation techniques, which demand posed multi-view films and exhibit better performance and synthesis quality.
The fundamental concept is that they gradually learn to generate flythroughs. Using single-image depth prediction techniques, they first compute a depth map from a beginning view, such as the first image in the figure below. After rendering the image to a new camera viewpoint, as illustrated in the middle, they use that depth map to create a new image and depth map from that viewpoint.
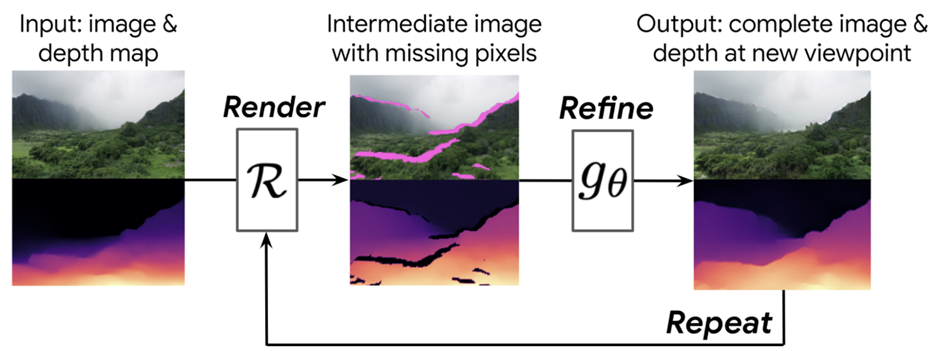
This intermediate image, however, has holes where they can see beyond things into areas that were not visible in the original image, which is problematic. Additionally, it is hazy because the pixels from the previous frame are being stretched to show the larger objects even though they are now closer to them.
They developed a neural image refinement network to address these issues, which takes incomplete, an intermediate image of low quality and produces a complete, high-quality image and associated depth map. This synthesized image can then be used as the new starting point for repeating these stages. As the camera advances more profoundly into the area, the system automatically learns to build additional scenery, such as mountains, islands, and oceans. This process may be iterated as often as desired because they refine the image and the depth map.
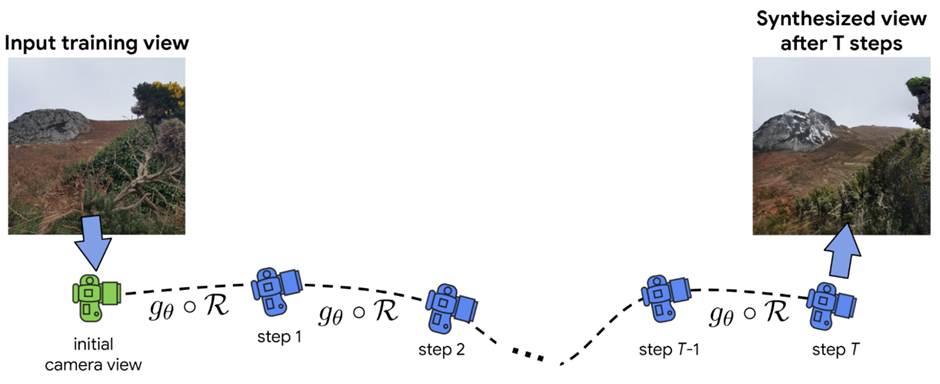
Using the ACID dataset, they trained this render-refine-repeat synthesis technique. They then apply this technique to generate several fresh perspectives that enter the scene along the same camera trajectory as the ground truth video and compare the rendered frames to the corresponding ground truth video frames to extract a training signal.
With such a capability, new types of material for video games and virtual reality experiences could be created, such as the opportunity to unwind while flying through an endless natural setting.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'InfiniteNature-Zero: Learning Perpetual View Generation of Natural Scenes from Single Images'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, code and project.
Please Don't Forget To Join Our ML Subreddit
![]()
Rishabh Jain, is a consulting intern at MarktechPost. He is currently pursuing B.tech in computer sciences from IIIT, Hyderabad. He is a Machine Learning enthusiast and has keen interest in Statistical Methods in artificial intelligence and Data analytics. He is passionate about developing better algorithms for AI.
Credit: Source link
Comments are closed.