Latest Artificial Intelligence Research Proposes ROME (Rank-One Model Editing): A Large Language Model Solution for Efficiently Locating and Editing Factual Associations in GPT Models
Where are the facts kept in a Large language model or LLM?
For two reasons, we are curious about how and where a model keeps its factual relationships.
- To comprehend enormous, opaque neural networks: Large language models’ internal calculations are poorly understood. Knowing huge transformer networks requires first understanding how information is processed.
- Making corrections: Since models are frequently inaccurate, biased, or private, we want to create techniques that will make it possible to identify and repair specific factual inaccuracies.
In a paper published recently, it has been shown that factual associations within GPT correspond to a localized calculation that is directly editable.
Large language transformers, such as autoregressive GPT (Radford et al., 2019; Brown et al., 2020) and masked BERT (Devlin et al., 2019) models, have been shown to produce predictions that are consistent with factual knowledge (Petroni et al., 2019; Jiang et al., 2020; Roberts et al., 2020; Brown et al., 2020). While certain factual predictions alter when rephrased, others are resistant to paraphrasing, according to Elazar et al. (2021a). For instance, GPT will accurately foretell the fact: “Seattle” when given a prefix like “The Space Needle is situated in the city of.”
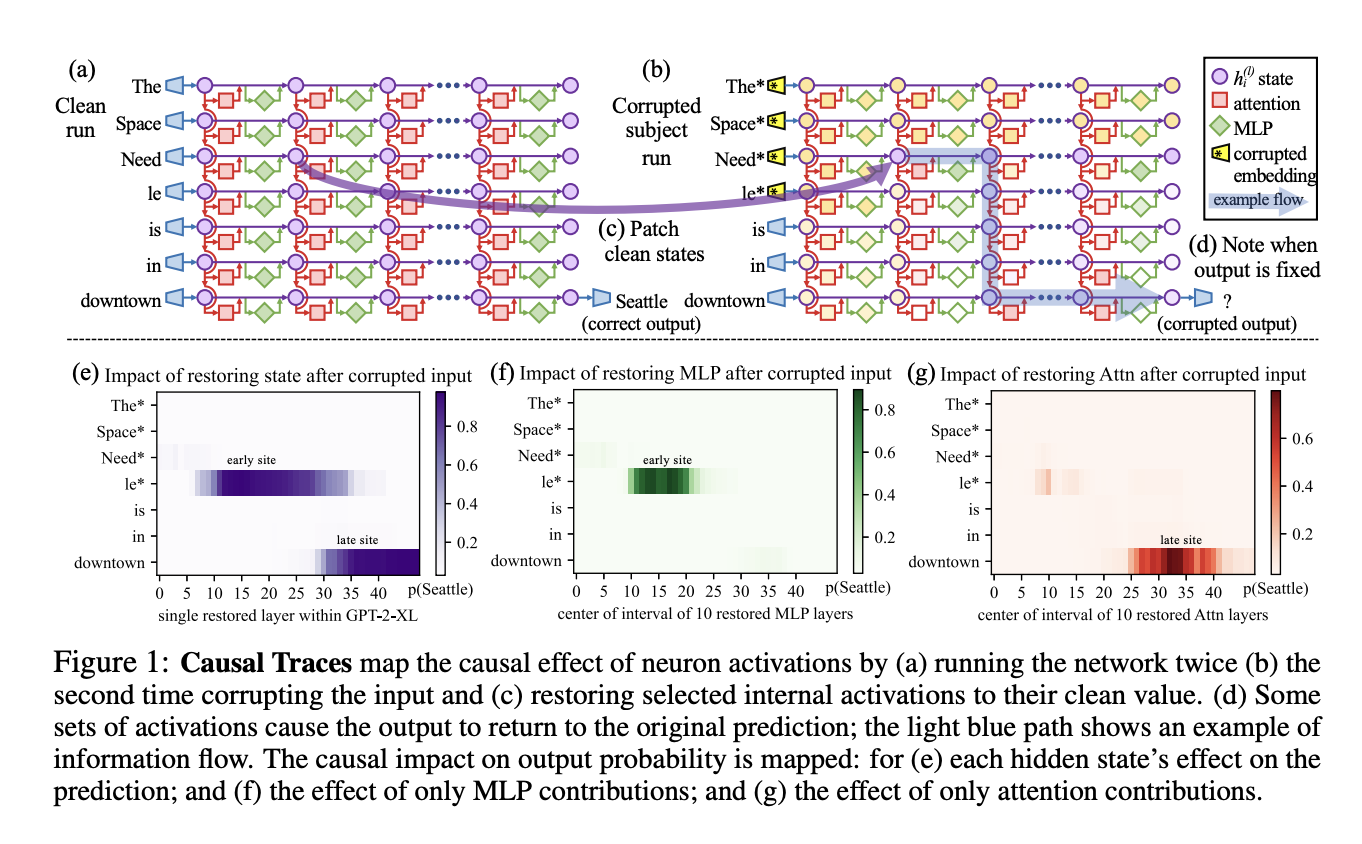
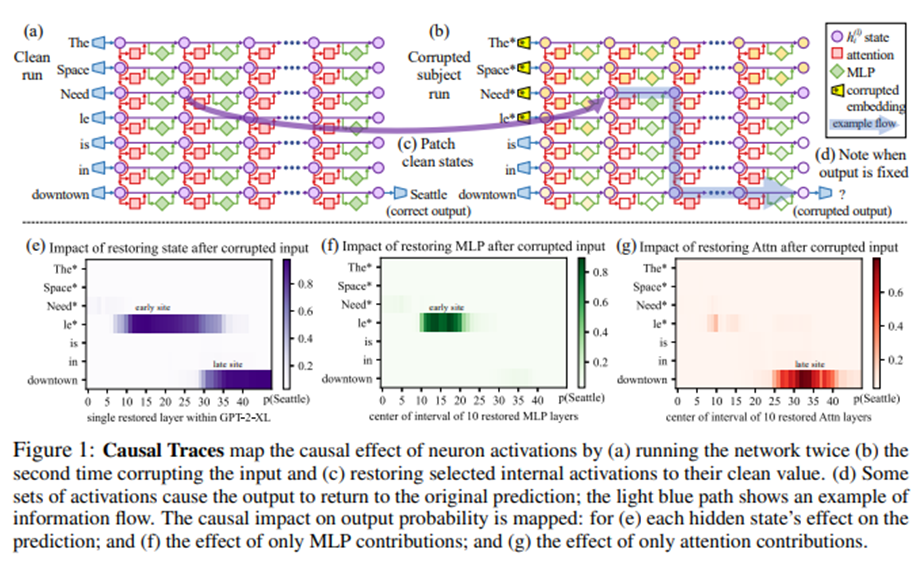
In order to pinpoint the specific modules inside a transformer that mediate memory of a fact about a subject, the researchers in this paper first examined the causal effects of hidden states. They found that when processing the last token of the subject name, feedforward MLP placed at various middle levels is key.
The researchers found two things for GPT-style transformer models:
1. When processing the final token of the topic, factual associations can be localized along three dimensions to MLP module parameters at various middle layers and in particular.
A few states in the causal trace above have information that can cause the model to switch from one factual prediction to another. These causal traces were used in their experiments, and they discovered evidence that knowledge retrieval takes place in MLP modules at the early site; attention processes at the late site then convey the information to the point in the computation where the particular word can be anticipated.
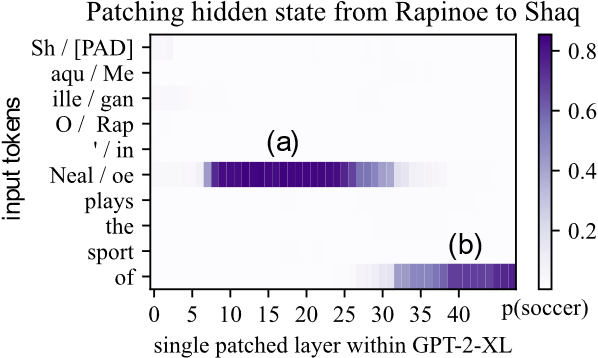
2. Small rank-one adjustments inside a single MLP module can alter certain factual correlations. By evaluating generalization to alternative wordings of the same information, they can discern between changes in knowledge and merely superficial linguistic changes.
The team developed a brand-new Causal Tracing technique to pinpoint the key calculations influencing factual recollection. While processing a factual message, the approach separates the causal consequences of specific states in the neural network. By following this information flow, it is possible to pinpoint the modules that mainly contribute to factual association retrieval.
The proposed ROME is made to change specific facts inside a GPT model. ROME views a single module as a key-value store in which the key encrypts a subject, and the value encrypts the knowledge associated with that subject. The model may thus retrieve factual linkages by getting the value corresponding to the key, enabling the associations of particular facts to be altered and updated in specific and generalized ways.
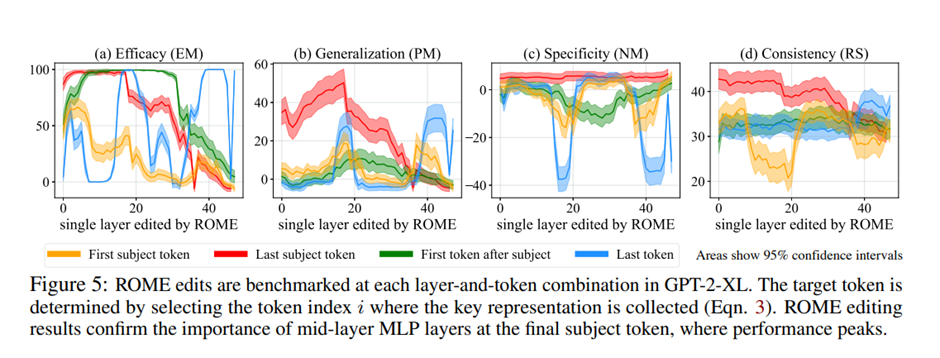
The researchers tested ROME using their CounterFact dataset, which contains thousands of counterfactuals and text that enables quantitative assessment of specificity and generalization while learning a counterfactual, as well as the Zero-Shot Relation Extraction (zsRE) task. On the CounterFact dataset, ROME maintained both specificity and generalization while exhibiting competitive results on zsRE during the assessments.
They potentially increase the transparency of these systems and decrease the energy required to correct errors by describing the internal structure of large autoregressive transformer language models and creating a quick method for changing stored knowledge.
Check out the paper, project, and GitHub link. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Rishabh Jain, is a consulting intern at MarktechPost. He is currently pursuing B.tech in computer sciences from IIIT, Hyderabad. He is a Machine Learning enthusiast and has keen interest in Statistical Methods in artificial intelligence and Data analytics. He is passionate about developing better algorithms for AI.
Credit: Source link
Comments are closed.