Meet ‘Chinese CLIP,’ An Implementation of CLIP Pretrained on Large-Scale Chinese Datasets with Contrastive Learning
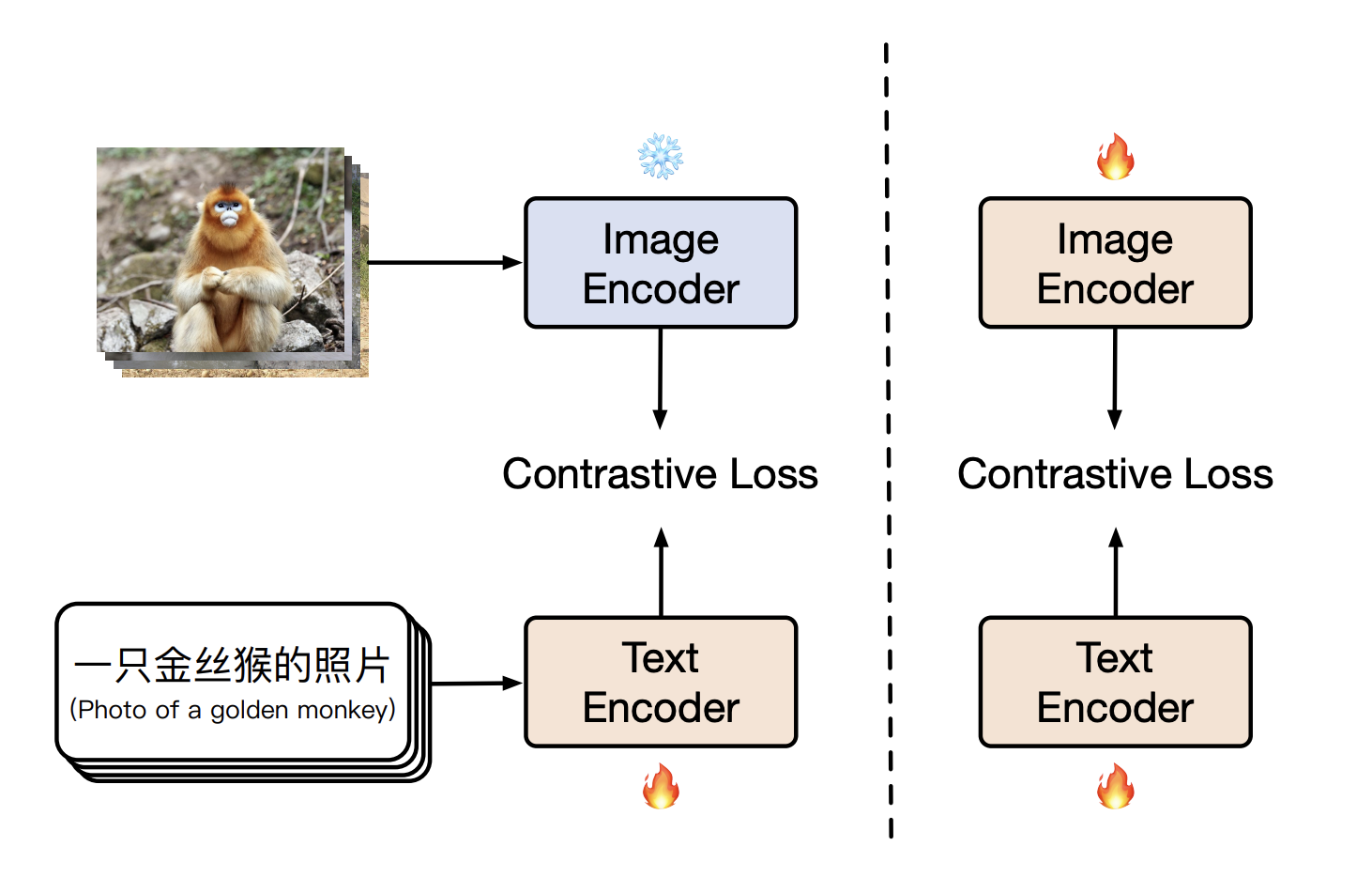
Contrastive Language-Image Pretraining, or CLIP, is a training method that differs from standard technics used by the vision community. A large dataset of over 400 million image-text pair data from the web is used to pretrain the contrastive learning-based CLIP model. Despite the method’s simplicity, CLIP displayed competitive performance in zero-shot image classification across a variety of datasets and not only excelled in vision-language retrieval. It also served as a vision foundation model. In the community of Chinese multimodal representation learning, however, no such model precisely adheres to CLIP’s architecture.
In the past, Chinese multimodal pre-trained models were mostly generative multimodal pretrained models or contrastive learning-based models with additional complex model and training problem designs. A research team from Alibaba Group proposed a large-scale dataset of image-text pairings in Chinese to overcome these problems, most of which are taken from publicly accessible datasets.
The authors introduced Chinese CLIP (CN-CLIP), a CLIP model pre-trained on a large-scale dataset of Chinese image-text pairs. Concretely, they propose a new dataset of nearly 200 million image-text pairs obtained from publicly available data. They also create five distinct Chinese CLIP models, with 77 to 958 million parameters each. A two-stage pre-training strategy is used for the pre-training. The image encoder is fixed in Stage 1, whereas both encoders should be optimized in Stage 2.
First, they initialize the image encoders using the OpenAI CLIP and/or LAION CLIP weights, while text encoder parameters are initialized using the released Chinese Roberta weights. Then, in the first stage, the authors proposed using data-augmentation operations such as random resize cropping and AutoAugment. The image encoder is unfrozen in the second stage, and all the model parameters are updated. Finally, a fine-tuning operation of CN-CLIP is performed on three cross-modal retrieval datasets: MUGE, Flickr30K-CN, and COCO-CN.
An evaluation study was conducted on three Chinese cross-modal retrieval datasets, including MUGE2, Flickr30K-CN, and COCO-CN. According to experimental findings, both the large-size and huge-size Chinese CLIP achieve cutting-edge performance on the three datasets in settings that include both zero-shot learning and fine-tuning. On the ELEVATER benchmark’s “Image Classification in the Wild” track, they also assess the competence of zero-shot image classification. For assessing Chinese models, the authors manually transform the datasets. Chinese CLIP performs competitively against English and Chinese models on the classification datasets. Finally, an ablation investigation demonstrates that it can outperform the other pre-training approaches in model performance.
In this paper, we saw an implementation of CLIP pretrained on large-scale Chinese datasets with contrastive learning. The authors create a pre-training dataset of over 200 million samples by gathering image-text pairings from open sources. By initializing encoders with the weights of the pretrained models that already exist, they implement pre-training. They then use a novel two-stage pre-training technique to construct five Chinese CLIP models with various model sizes ranging from 77 to 958 million parameters. The evaluation study shows that Chinese CLIP can achieve competitive performance on multiple cross-modal retrieval datasets, including MUGE, Flickr30K-CN, and COCO-CN, in both setups of zero-shot learning and fine-tuning.
Check out the paper, code, and demo. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Mahmoud is a PhD researcher in machine learning. He also holds a
bachelor’s degree in physical science and a master’s degree in
telecommunications and networking systems. His current areas of
research concern computer vision, stock market prediction and deep
learning. He produced several scientific articles about person re-
identification and the study of the robustness and stability of deep
networks.
Credit: Source link
Comments are closed.