Princeton and Google AI Researchers Propose ReAct: An Effective Artificial Intelligence Method for Synergizing Reasoning and Acting in Large Language Models
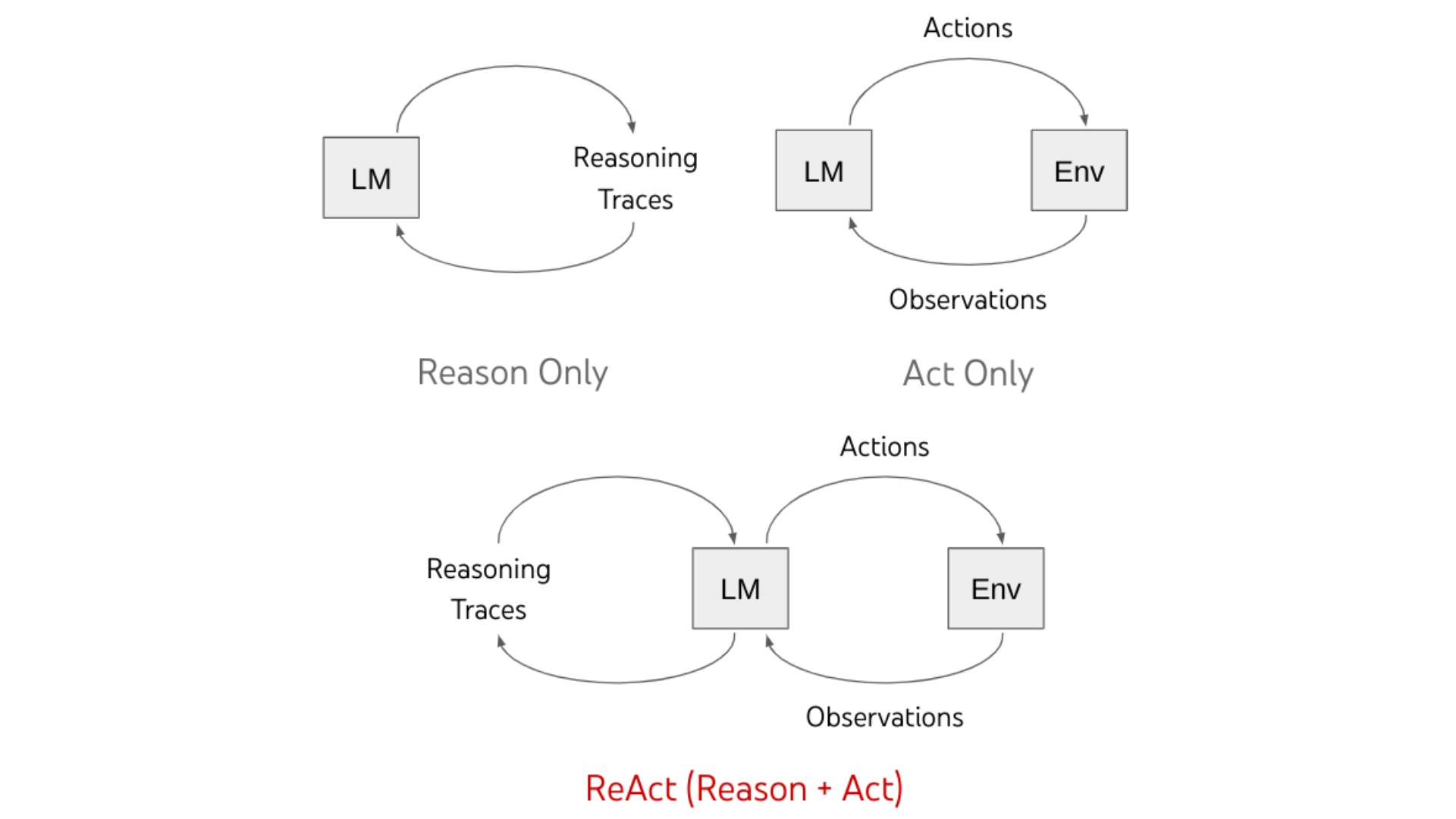
Although large language models (LLMs) have shown astounding performance on tasks involving interactive decision-making and language understanding, their capacities for reasoning (such as chain-of-thought prompting) and acting (such as action plan generation) have primarily been studied as separate topics. Recent work focuses on translating text contexts to text actions using the language model’s internal knowledge when using pre-trained language models to act in various interactive environments (such as text games, online navigation, etc.). In contrast, with chain-of-thought prompting, a model generates reasoning using its internal representations and is not anchored in the outside world. This restricts its capacity to investigate, reason, or update its knowledge in response to events.
In their most recent project, a research team from Google Research investigated the use of LLMs to produce interspersed reasoning traces and task-specific actions. The researchers put up a generic paradigm in their research article titled “ReAct: Synergizing Reasoning and Acting in Language Models” to enable language models to handle a variety of language reasoning and decision-making tasks. They show that the Reason+Act (ReAct) paradigm consistently performs better than reasoning-only and acting-only paradigms when it comes to inducing larger language models, optimizing smaller language models, and improving human interpretability and reliability. ReAct makes it possible for language models to produce verbal reasoning traces and text actions concurrently.
The PaLM-540B frozen language model used in the ReAct prompting setup is prompted with a limited number of in-context examples to produce task-solving domain-specific actions (such as “search” in question-answering and “go to” in room navigation). When performing tasks where reasoning is crucial, the creation of reasoning traces and actions is alternated, resulting in a task-solution trajectory that includes several reasoning-action-observation phases. In contrast, reasoning traces only need to be sparsely present in the most crucial locations of a trajectory in decision-making tasks that may involve a large number of actions. In this instance, prompts are written using sparse reasoning, and the language model determines when reasoning traces and actions will occur asynchronously. The group also investigated using ReAct-format trajectories to optimize smaller language models. The ReAct prompted PaLM-540B model was used to generate trajectories. The task success trajectories were then used to fine-tune smaller language models (PaLM-8/62B) to reduce the need for extensive human annotation.
For evaluation objectives, four benchmarks—question answering (HotPotQA), fact-checking (Fever), text-based gaming (ALFWorld), and web page navigation (WebShop)—were used to compare ReAct and state-of-the-art baselines. When it comes to question answering (HotpotQA) and fact checking (Fever), the model overcomes common problems of hallucination and error propagation in chain-of-thought reasoning by interacting with a simple Wikipedia API and producing human-like task-solving trajectories that are more interpretable than baselines without reasoning traces. Furthermore, ReAct surpasses imitation and reinforcement learning techniques on two interactive decision-making benchmarks, ALFWorld and WebShop, while being given only one or two in-context examples, with absolute success rates of 34% and 10%, respectively.
The research team also investigated human-in-the-loop interactions with the system by giving a human inspector control over ReAct’s reasoning traces. ReAct was shown to be able to alter its behavior to comply with inspector revisions and effectively perform a task by just replacing a hallucinatory line with inspector tips. ReAct makes it much simpler to solve problems because it only necessitates the manual editing of a small number of ideas, opening up new possibilities for human-machine collaboration.
ReAct is a simple yet successful technique for integrating acting and thinking in language models, to put it briefly. It shows that it is possible to describe a thought, behavior, and environmental feedback within a language model, resulting in a flexible agent that can handle problems that call for interacting with the environment. ReAct achieves improved performance with comprehensible decision traces through several experiments concentrating on multi-hop question-answering, fact-checking, and interactive decision-making challenges. Google intends to continue working on ReAct by using the language model’s tremendous potential for addressing more complex embodied tasks. They wish to achieve this by using techniques like large multitask training and pairing ReAct with powerful reward models.
Check out the Paper and Reference article. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.