Meet Paella, a Novel AI Text-to-Image Model That Uses a Speed-Optimized Architecture Allowing to Sample a Single Image in Less Than 500 ms While Having 573M Parameters

Recent advances in the diversity, quality, and variety of created pictures result from research on text-to-image generation. However, these models’ remarkable output quality has come at the expense of poor inference speeds that are unsuitable for end-user applications due to their numerous sampling stages. Most recent state-of-the-art works are either transformer-based or rely on diffusion models. Transformers often compress their spatial representation before learning because the self-attention process scales quadratically with latent space dimensions. Additionally, a transformer flattens the encoded picture tokens to regard images as one-dimensional sequences, which is an unnatural projection of images and necessitates a substantially more sophisticated model to develop a knowledge of the 2D structure of ideas.
Transformers must sample each token individually because of their auto-regressive nature, which results in lengthy sampling times and expensive computations. On the other hand, diffusion models may successfully learn at the pixel level but, by default, demand a very high number of sampling steps. Using a fully convolutional neural network architecture, they offer a unique method for text-conditional picture creation that is neither transformer-based nor diffusion-based. A visual representation of their site’s general architecture is the recommended approach. Paella training uses a compact latent space. Noise affects latent images, and the model is designed to forecast the denoised form of the image accurately.
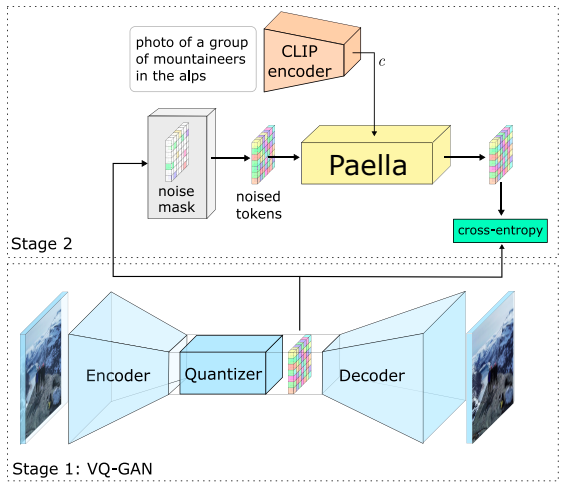
A visual representation of their site’s general architecture is recommended approach. Paella training uses a compact latent space. Noise affects latent images, and the model is designed to accurately forecast the unnoised form of the image
Their methodology is appealing for use cases constrained by latency, memory, or computational complexity limitations. It may sample pictures in as few as eight steps and produce high-fidelity results. Their model uses a vector-quantized generative adversarial network (VQGAN) to encode and decode with a medium compression rate. It operates on a quantized latent space (see Figure above).
Due to the convolutional structure of their model, which is unaffected by common transformer restrictions like quadratic memory expansion, they may employ a considerably lower compression rate. Delicate features typically lost when working with higher compression can be preserved using a low compression rate. During training, they randomize the picture tokens and quantize the images using the VQGAN above. Given a noised picture version and a conditional label, the model’s objective is to reconstruct the image tokens. Chang et al. include a unique mask token to initially mask the full image. Sampling new images are iterative and inspired by Masked Generative Image Transformer (MaskGIT), but with significant changes. The model then repeatedly predicts all the tokens in the picture, keeping just a small number of the tickets.
They contend that this process is highly restricted since it prevents the model from automatically correcting its predictions at the beginning of the sampling process. Instead of masking the tokens, they randomly generated noise to give the model greater flexibility. This allows the model to improve its predictions for specific permits during sampling. Additionally, they increase sample quality by employing classifier-free guidance (CFG), accomplished by executing unconditional training randomly. They also use locally typical samples (LTS) to enhance the sampling procedure. They use Wang et al.’s, Ramesh et al.’s, and Contrastive Language-Image Pretraining (CLIP) embeddings to enable text conditioning. Still, they only train on text embeddings rather than exclusively learning a prior network for mapping text embeddings to image embeddings. This decouples their model from the need for an explicit prior and reduces computational complexity.
Their model can theoretically create pictures of any size because it is convolutional. While only requiring one sample, this characteristic may be exploited to outpaint pictures. By shifting the context window repeatedly, transformers need to develop larger latent resolutions for this ability, which comes with quadratically expanding sample durations. In addition to outpainting, they can also do text-guided inpainting. Furthermore, by tweaking their model for picture embeddings, it is possible to produce several versions of images. Moreover, we can do latent space interpolations thanks to CLIP embeddings.
Finally, multi-conditioning and structural manipulation are possible from a given base picture.
They mainly offer the following contributions:
1. Based on discontinuous (de)-noising in a quantized vector space and a parameter-efficient fully convolutional network, they suggest a unique training aim for text-to-image creation.
2. They present a sampling strategy that is more straightforward and effective than earlier work and can sample high-quality photos in a few steps.
3. They look at how well their suggested system works with picture variants, inpainting and outpainting, latent space interpolation, multi-conditioning, and structural editing.
Check out the Paper and GitHub link. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.