Researchers From Stanford And Microsoft Have Proposed An Artificial Intelligence (AI) Approach That Uses Declarative Statements As Corrective Feedback For Neural Models With Bugs

The methods currently used to correct systematic issues in NLP models are either fragile or time-consuming and prone to shortcuts. Humans, on the other hand, frequently reprimand one another using natural language. This inspired recent research on natural language patches, which are declarative statements that enable developers to deliver corrective feedback at the appropriate level of abstraction by either modifying the model or adding information the model may be missing.
Instead of relying solely on labeled examples, there is a growing body of research on using language to provide instructions, supervision, and even inductive biases to models, such as building neural representations from language descriptions (Andreas et al., 2018; Murty et al., 2020; Mu et al., 2020), or language-based zero-shot learning (Brown et al., 2020; Hanjie et al., 2022; Chen et al., 2021). For corrective purposes, when the user interacts with an existing model to enhance it, language has yet to be properly utilized.
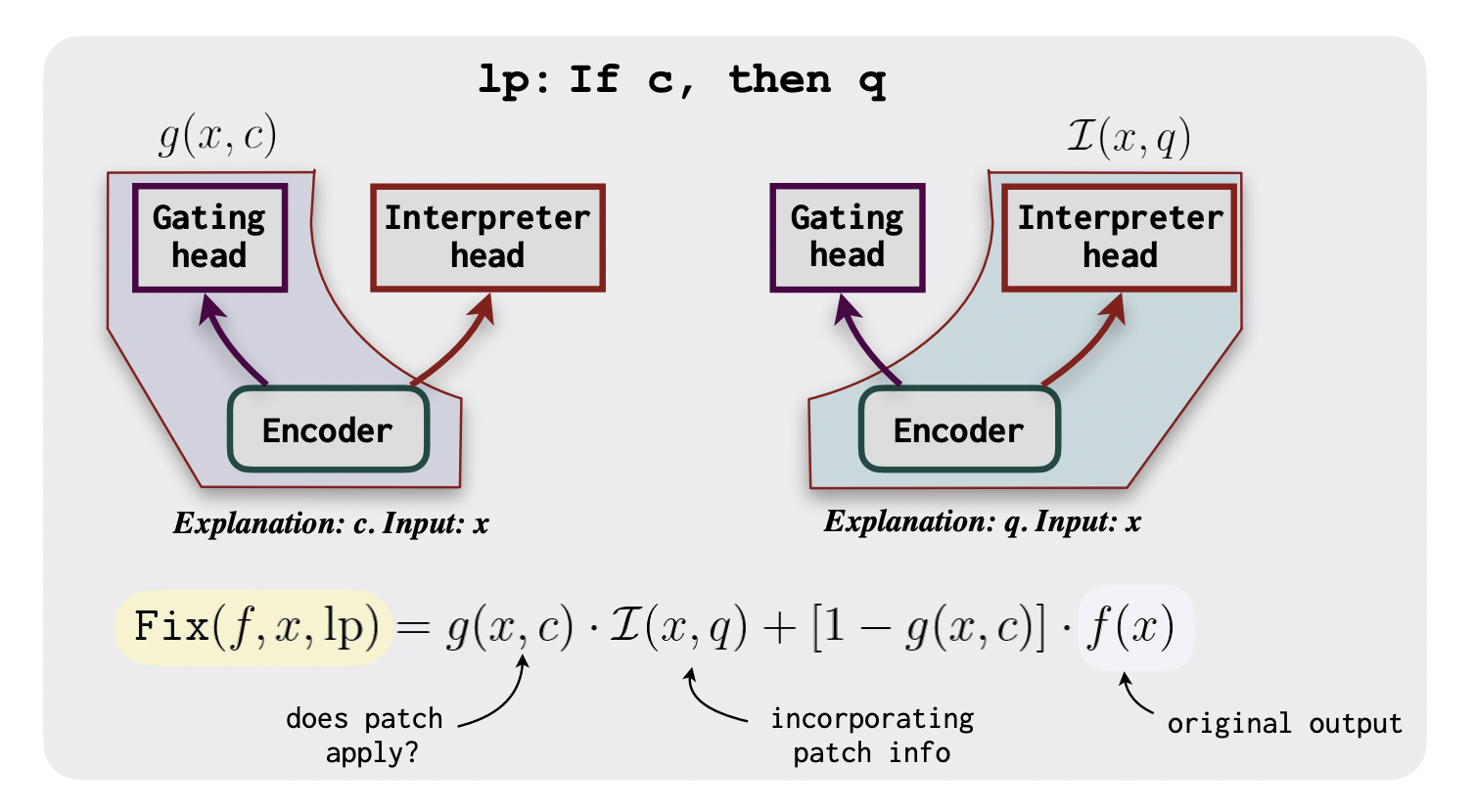
The neural language patching model has two heads: a gating head that determines if a patch should be applied and an interpreter head that forecasts results based on the information in the patch. The model is trained in two steps: first on a tagged dataset and then through task-specific fine-tuning. A set of patch templates are used to create patches and synthetic labeled samples during the second fine-tuning step.
The research group used Google’s T5-large language model to implement their method and compared results with baselines for binary sentiment analysis and relation extraction under two scenarios: the original model with only task fine-tuning (ORIG), and the model obtained after patch fine-tuning (ORIG+PF).

The researchers suggested a method for patching that separates the process of assessing whether a patch is applicable (gating) from the task of integrating the information (interpreting), and they demonstrated that this method significantly improves two tasks, even with a small number of patches. They also demonstrate that patches are more resistant to potential shortcuts and efficient (1–7 patches are equivalent to or better than as many as 100 fine-tuning examples).
Their approach is a first step in enabling users to “talk” in a single step to correct models.
Some Limitations:
Scaling to huge patch libraries is a limitation. Inference time for the method scales linearly with patch library size.
Scaling to more patch types. Currently, developers must create patch templates in advance based on knowledge of the types of corrective feedback they may want to write in the future.
Analyzing several patches. Finally, the method they created can only use one patch at a time, choosing the one that is most pertinent from our patch library.
Hence, in this study, declarative statements are proposed as natural language patches, which allow programmers to manage models or add information by setting conditions at the appropriate level of abstraction. Thus, it dramatically improves accuracy without incurring high computational costs by using declarative sentences as feedback to fix mistakes in neural models.
Check out the paper, code, and reference article. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Rishabh Jain, is a consulting intern at MarktechPost. He is currently pursuing B.tech in computer sciences from IIIT, Hyderabad. He is a Machine Learning enthusiast and has keen interest in Statistical Methods in artificial intelligence and Data analytics. He is passionate about developing better algorithms for AI.
Credit: Source link
Comments are closed.