This AI Model Integrates Feature Pyramids into Vision Transformers to Enhance Their Capability
Convolutional neural networks (CNNs) have dominated the computer vision domain for the last decade. From object detection to image classification; they were the state-of-the-art solutions in multiple tasks. CNNs have been the go-to method for any computer vision application.
Things started to change with the introduction of the vision transformer (ViT). It was the first paper that showed how to move transformers, the structure that was performing state-of-the-art in natural language processing, to the computer vision domain and outperforms its CNN counterpart in classification tasks. Afterward, gradual improvements to the vision transformers were proposed.
Despite its huge success in image classification, ViT had some drawbacks, making it impractical to apply in other tasks. For example, it cannot be used for object detection and segmentation because it only outputs a single-scale and low-resolution feature map, which is unsuitable for segmentation tasks. On the other hand, although its efficiency compared to its CNN counterpart in low-resolution inputs is impressive, the computational complexity increases exponentially when we increase the input size. This complexity becomes an issue when we try to apply ViT on common benchmarks for object segmentation, where the input dimensions are much higher than image classification.
One might ask what could be done to solve these limitations. How could we fix the problems of ViT so that it can be used for tasks other than image classification? Well, one answer given is the Pyramid Vision Transformer (PVT).
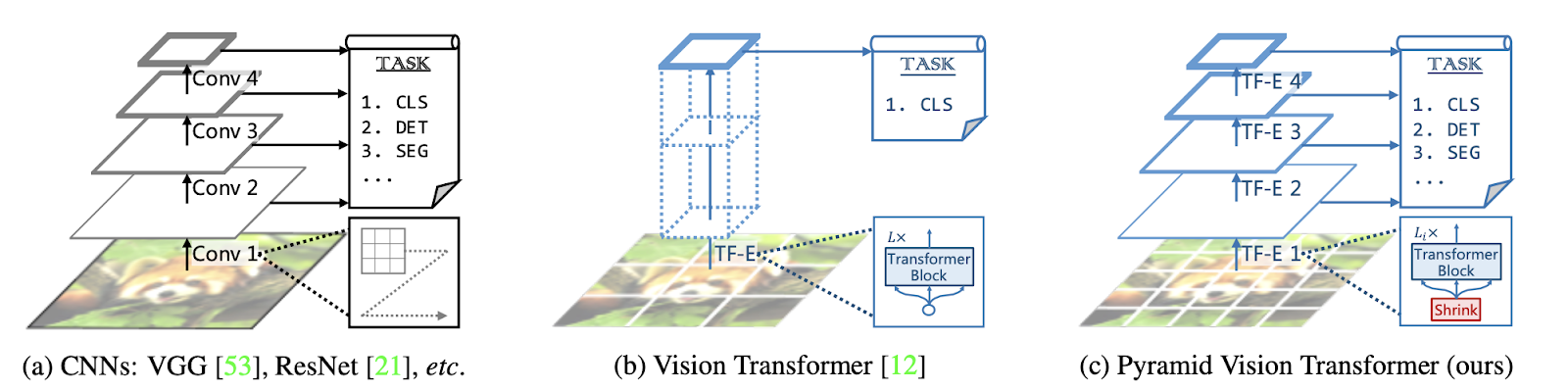
PVT authors explored a clean and convolution-free transformer backbone structure to tackle the aforementioned problems. PVT can be an alternative to CNN in many computer vision tasks, both in image-level and pixel-level prediction.
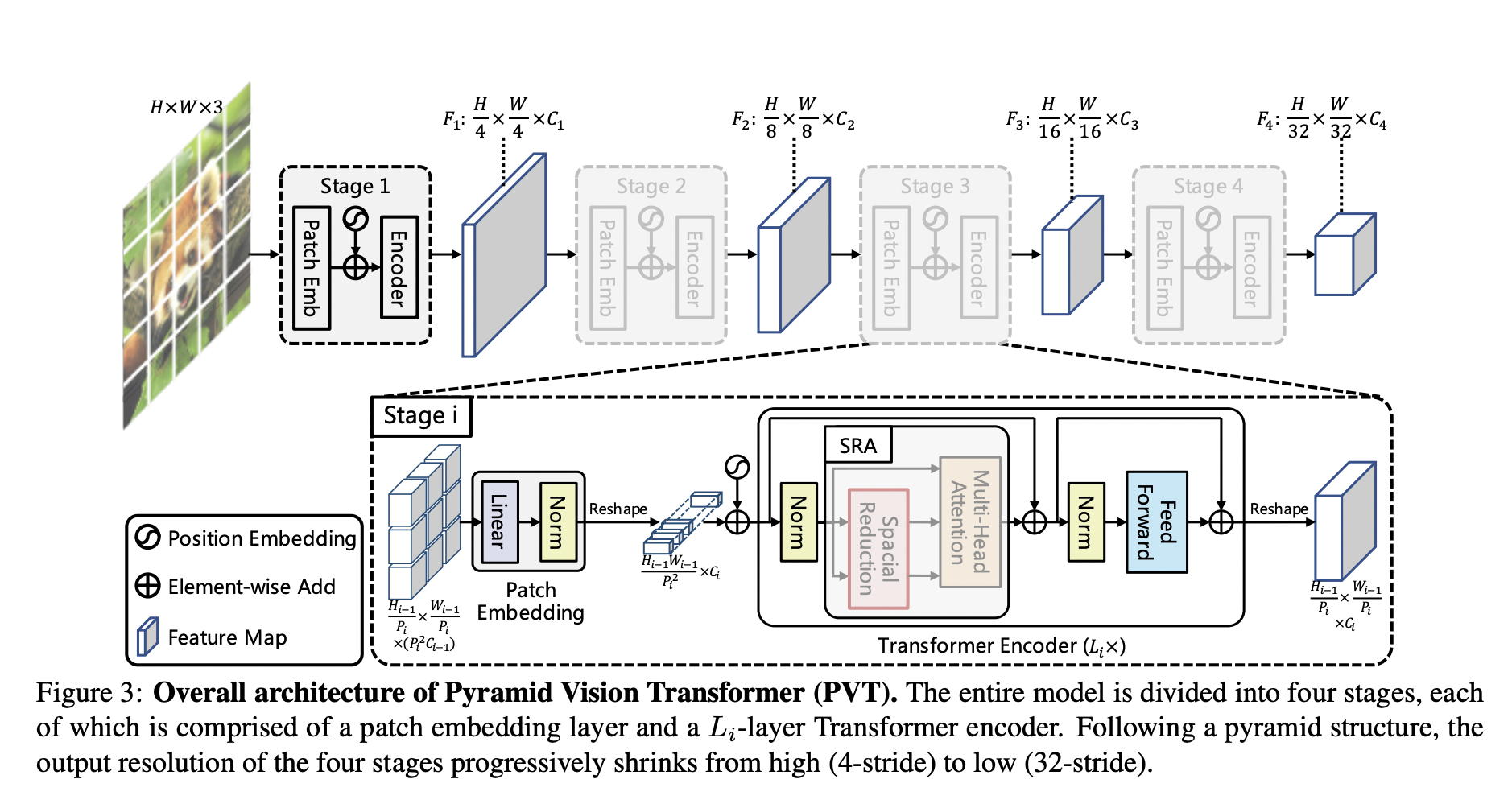
PVT has some tricks up on its sleeves to overcome the drawbacks of the ViT. It takes smaller image patches (4×4 pixels per patch) as input to learn high-resolution representation. Moreover, it introduces feature pyramids to reduce the sequence length as we go deeper into the network. Doing so reduces the computational complexity significantly. Finally, it uses a spatial-reduction attention (SRA) layer to further improve efficiency.
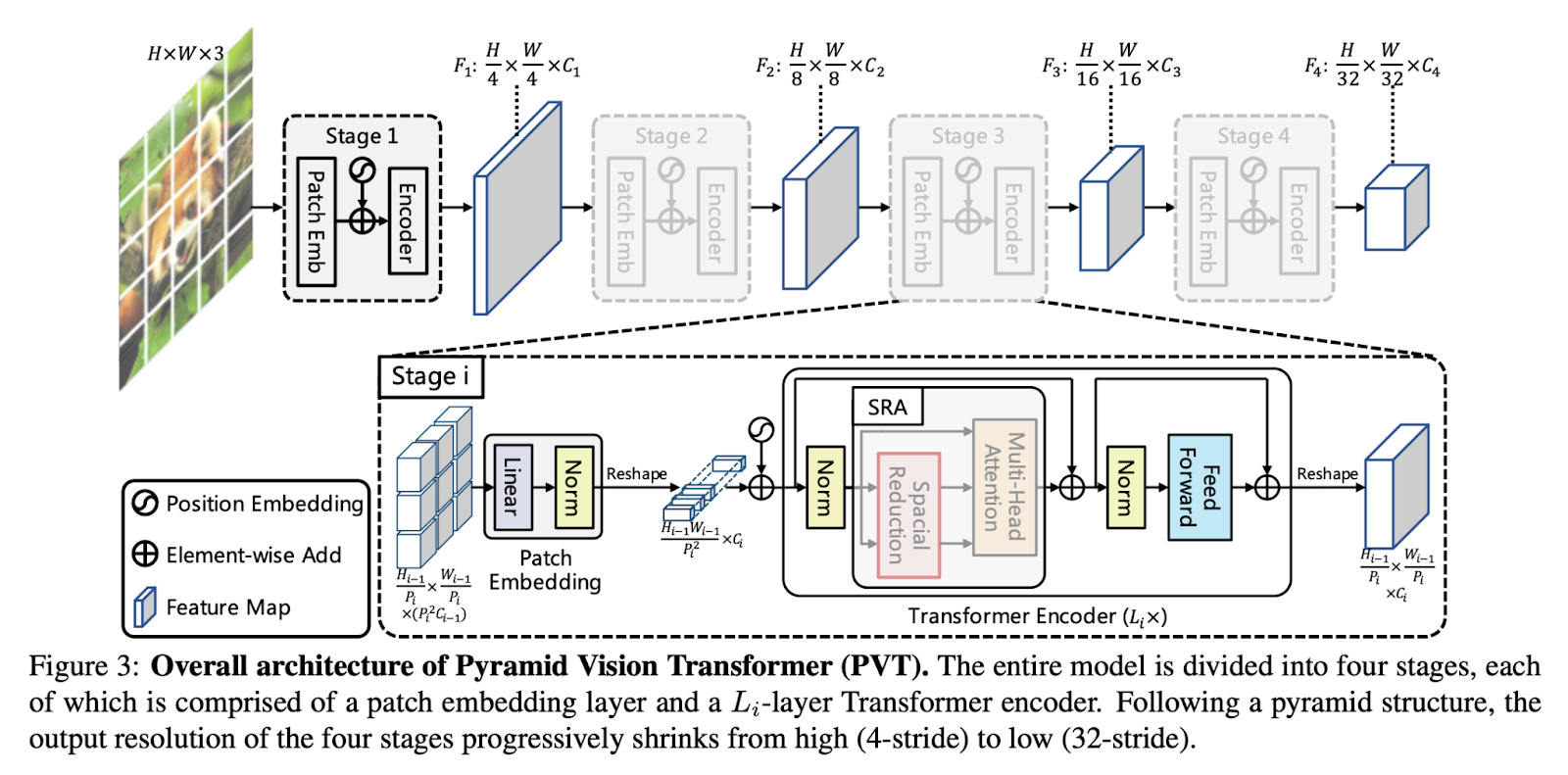
CNNs have local receptive fields, and as a result, it increases the network depth to extract features at various levels. On the other hand, PVT always produces a global receptive field that can be useful for detection and segmentation tasks. When we compare PVT with ViT, we can see the advanced pyramid structure enables straightforward integration into dense prediction pipelines. Moreover, PVT can be combined with other task-specific transformer decoders to produce convolution-free pipelines for computer vision tasks.
PVT is the first object detection pipeline that is entirely convolution-free. It can produce state-of-the-art results in various tasks, from object detection to segmentation. It is still an early-stage study of applying transformers to computer vision tasks, but it is a good step toward a transformer-dominated future.
This was a brief summary of PVT. You can find more information in the links below.
Check out the Paper and Github. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.