Salesforce AI Introduces an Automated Method for Evaluating the Quality of Artificial Intelligence-Generated Text by Repurposing Prior Human Evaluation Data
The growth of over 100 remarkable language translation models and other advances linked to book summarizing or collaborative creative writing highlight recent advancements in text generation research. The ability of natural language generation (NLG) models to make original choices and produce unique content has become an attractive area of study in recent years. However, because text generation is an open-ended process, it might not be easy to gauge how well NLG tasks are progressing. Determining which output from a model is preferred over another frequently involves human evaluation. However, human evaluation has its own drawbacks as it is frequently pricy and challenging to duplicate.
Salesforce Researchers recently worked on creating an automated evaluation method called Near-Negative Distinction (NND) to assess the caliber of AI-generated content by eliminating the need for human evaluation. NND tests are created by converting previous human annotations. A high-quality output candidate must have a better likelihood in an NND test than a near-negative candidate with a known error. The percentage of successful NND tests and the distribution of task-specific mistakes made by the model serve as indicators of model performance.
When it comes to NLG models, automatic evaluation is a better option than human evaluation because it only costs once to gather standardized outputs for a set of held-out inputs. The similarity between the outputs of present and future models to these references is used to gauge their performance. This is where the Near-Negative Distinction paradigm makes a difference. A model is evaluated based on how likely it is to generate two existing candidates of differing quality, as opposed to automatically comparing a model’s outputs to the one true reference. The model is given a higher NND score, mirroring the previous human evaluation, if it is more likely to produce the candidate with the highest human rating. In essence, NND assesses how likely new models are to produce outputs with existing annotations rather than asking them to create their own outputs.
In order to comprehend how NND works in principle, the annotated candidates (which refer to those pairs of candidates whose preferences are known) are first used to build NND tests. The likelihood that a new model will be assigned to each candidate is then calculated. This is achievable since most text generation models are language models that can give each word sequence a probability. Each NND test is administered in the last phase. If the examined model gives the high-quality candidate a greater probability, it is said to have passed the test.
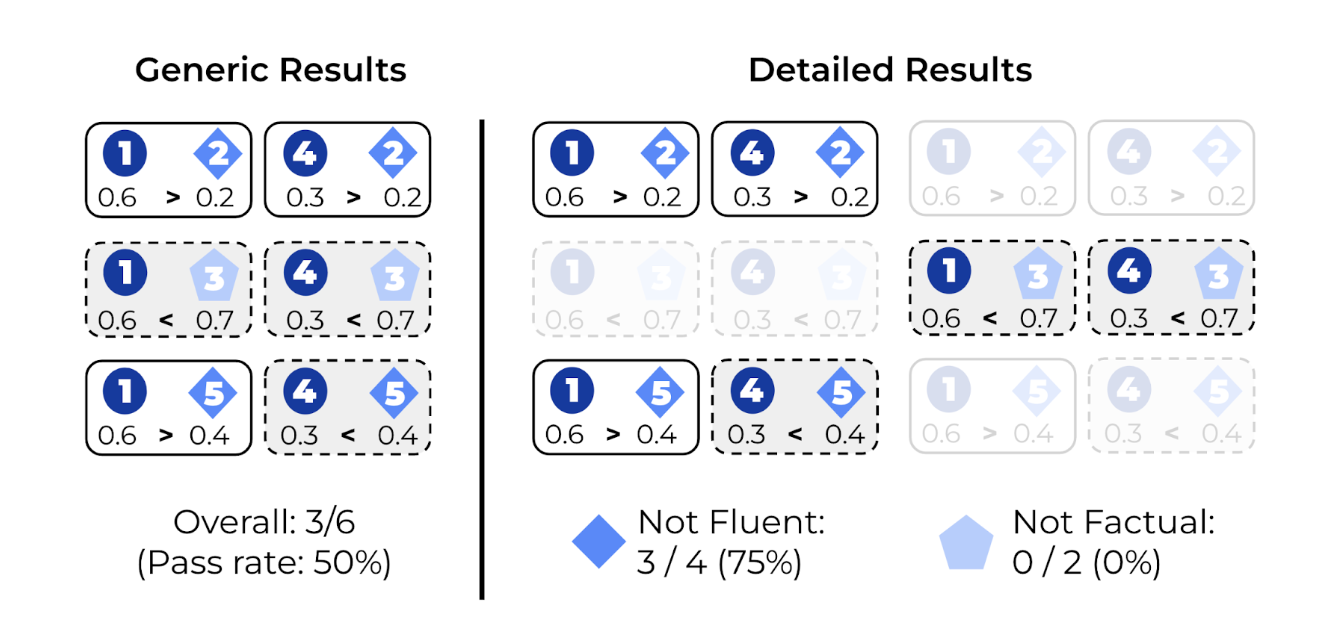
Two methods are used to compile NND results. The overall percentage of tests passed is determined as a general result in the first procedure. The principal use of this finding is model comparison. The researchers conducted further computations on the pass rates on the tests involving particular error categories to acquire more thorough results. When examining the merits and drawbacks of a paradigm, this comprehensive NND breakdown is frequently helpful.
Salesforce researchers conducted experiments on three NLG tasks, namely question generation, question answering, and summarization, to evaluate their newly developed text generation evaluation method. They concluded that NND achieves a higher correlation with human judgments than standard NLG evaluation metrics. The researchers then used four real-world scenarios to explain how NND evaluation works, some of which involved researching model training dynamics and performing fine-grain model analysis. Their research demonstrates how NND can enable low-cost NLG evaluation and give human annotations a second chance at life.
The Salesforce team believes that the NND evaluation technique can be a first step toward accelerating NLG research in the near future. NND tests perform better than other tests since they do not need to generate candidates, which would include confounding variables and be computationally expensive. Furthermore, because NND evaluation is computationally cheap, it can be used to evaluate interim model checkpoints during training in addition to final models. The team also demonstrates how the framework’s adaptability may be utilized to comprehend the advantages and disadvantages of a model. This can be accomplished by estimating how more recent models might fare in an ongoing human study or by seeing how a summarizing model can lose its capacity to maintain factual consistency with time.
Check out the Paper, Github link, and Reference Article. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.