Latest AI Research Finds a Simple Self-Supervised Pruning Metric That Enables Them to Discard 20% of ImageNet Without Sacrificing Performance, Beating Neural Scaling Laws via Data Pruning


Applying neural scaling laws to machine learning models, which means increasing the number of computations, the size of the model, and the number of training data points, can reduce errors and improve model performance. Since we have a lot of computing power available and collecting more data is easier than ever before, we should be able to reduce the test error to a very small value, right?
Here is a catch, this methodology is far from ideal. Even though we have enough computational power, the benefits of scaling are fairly weak and unsustainable due to the huge additional computational costs. For example, dropping the error from 3.4% to 2.8% might require an order of magnitude of more data, computation, or energy. So what can be a solution?
Focussing specifically on the scaling of error with dataset size, one possible solution is Dataset pruning.
What is dataset pruning?

Dataset pruning is the process of removing redundant examples from a dataset to improve the learning of a machine learning model by increasing the information gained per example.
Researchers from Stanford University, the University of Tubingen, and Meta AI proposed and demonstrated how data pruning techniques could break beyond power scaling laws of error versus dataset size. But how does it work? The key idea behind the solution is that power-law scaling of error suggests that many training examples are highly redundant. Hence, we should remove these redundant examples and train on the pruned dataset without sacrificing the model’s performance.
These are the main contributions of the paper:
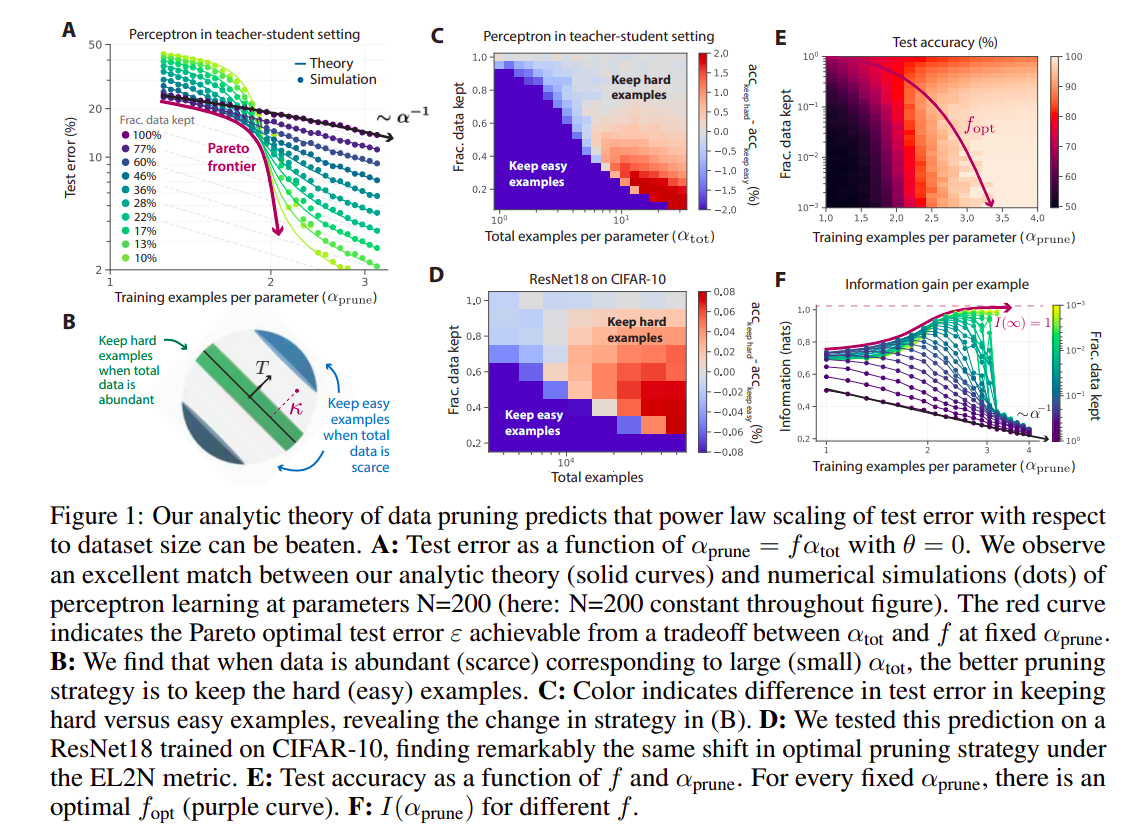
- Employing statistical mechanics, They proposed a data pruning methodology set in a student-teacher setting for perceptron learning,in which examples are pruned based on their teacher margin. Large (small) margin means easy (hard) examples. The theory quantitatively matches numerical experiments and reveals two striking predictions:
- The optimal pruning strategy changes with the initial data size; with abundant (scarce) initial data, one should retain only hard (easy) examples.
- If one selects an increasing Pareto optimum pruning proportion as a function of the initial dataset size, exponential scaling is feasible with regard to the pruned dataset size.
- They show that the two striking predictions derived from theory also hold in practice in much more general settings.
- They perform a large-scale benchmarking study of 10 different data pruning metrics at scale on ImageNet, seeing that most perform poorly, except for the most compute-intensive metrics.
- They proposed a self-supervised pruning metric. They show this self-supervised metric performs comparably to the best-supervised pruning metrics that need labels and much more computing.
Now let’s briefly discuss how they do it?
All the examples present in a dataset are of different values. Some are unique, while others are simply slight variations on others. Therefore, we need a way to quantify the differences between data points. We can think of these metrics as a way of ordering the data points by their difficulty (from easiest to hardest). When these metrics are used for data pruning, the hardest examples are retained, and the easiest ones are discarded.
EL2N scores, Forgetting scores and classification margins, Memorization and influence, Ensemble active learning, and Diverse ensembles(DDD) are the supervised metrics they have benchmarked the data pruning efficacy for on ImageNet.
After experimentation with different pruning strategies, it was concluded that the optimal pruning strategy depends on the amount of initial data. Pruning away the hardest samples rather than the easiest ones is a better strategy for a small dataset while keeping the hard examples is more beneficial for a large dataset. The intuition behind this can be understood as the easiest examples provide coarse-grained information, while the hardest data points provide fine-grained details. If we prune away easy examples in a small dataset, it would be hard to model the outliers, as the basics are not adequately captured. Hence, it is more important to get the model to a moderate error by modeling easy examples rather than focusing on modeling the hard ones. However, in a larger dataset, the easy examples are learned easily, so the fundamental challenge is learning the hard examples (the outliers).
Moreover, the team also showed that Pareto optimal data pruning, where no further improvements are attainable through changes in the data, can beat power-law scaling and further predict the information gain per sample added per dimension.
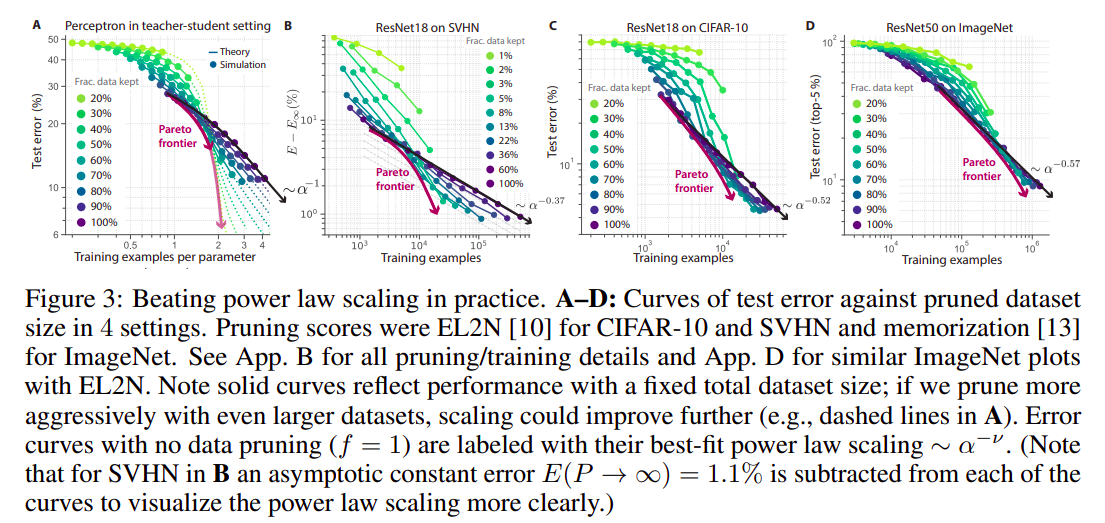
The researchers also verified the following three predictions from theory in practice by training ResNets on SVHN, CIFAR-10, and ImageNest using various initial dataset sizes:
- Relative to random data pruning, keeping the hardest examples helps when the initial dataset size is large; otherwise, it hurts the performance.
- Data pruning by retaining a fixed fraction of the hardest examples should yield power law scaling.
- The test error optimized over both the initial dataset size and the fraction of data kept can trace a Pareto optimal lower envelope that beats the power-law scaling of test errors as a function of pruned dataset size.
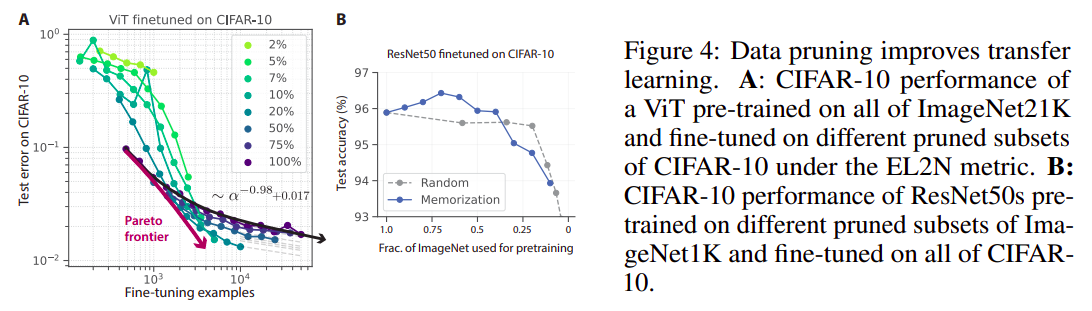
Is there anywhere else where data pruning can be useful?
Data pruning also improves transfer learning. Data pruning can reduce the amount of pretraining and fine-tune data without sacrificing performance, making transfer learning more efficient.
In addition, the researchers also proposed a self-supervised metric that does not require labels, so it can easily be scaled to prune data for large-scale foundation models trained on massive unlabeled datasets.
To compute this self-supervised metric for ImageNet, they did k-means clustering in the embedding space of an ImageNet pretrained model. They defined the difficulty of each point by the Euclidean distance to its nearest cluster centroid. This self-supervised metric matches or exceeds the best-supervised metrics’ performance despite being much simpler and cheaper to compute. If labels are available, then a supervised metric can be created by aligning the classes with the clusters. This supervised prototype also outperforms the prior supervised metrics. Moreover, the performance of self-supervised and supervised pruning is similar, demonstrating the promise of self-supervised pruning.
Check out the Paper. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.