This Artificial Intelligence (AI) Paper Presents A Study On The Model Update Regression Issue In NLP Structured Prediction Tasks
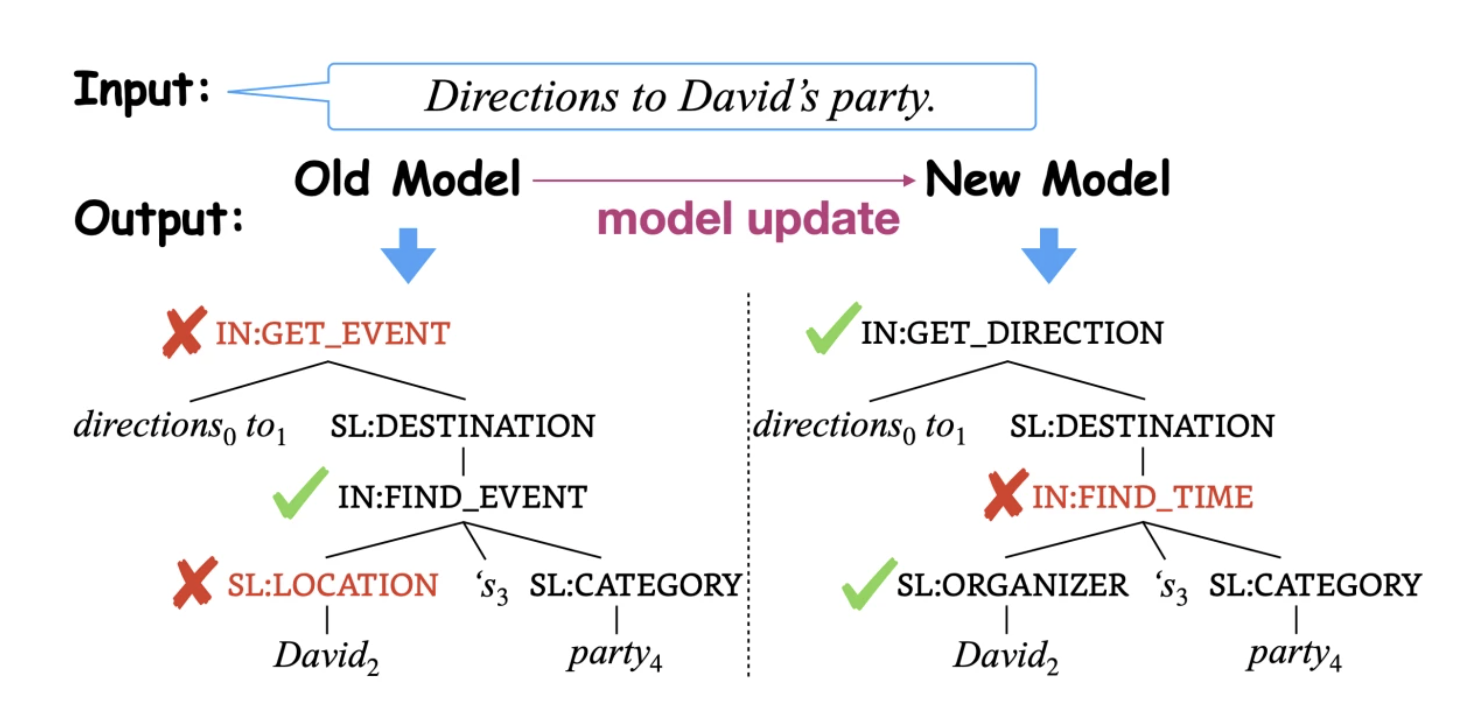
Model update regression is the term used to describe the decline in performance in some test cases following a model update, even when the new model performs better than the old model. Adopting the new model can be slowed because its occasional worse behavior can overshadow the benefits of overall performance gains.
Consider a scenario where a user’s preferred method of asking about traffic has been ignored by their recently upgraded virtual assistant. Even if the assistant has been enhanced in other ways, this might drastically diminish the user experience.
Classification issues in computer vision and natural language processing have previously been studied in model update regression (NLP) context. On the other hand, there is the scant treatment of practical NLP uses in the formalization of classification.
So far, only a few studies have focused on solving the model update regression problem using structured prediction tasks. In structured prediction (e.g., a graph or a tree), the global forecast is typically made up of several local predictions instead of a single global prediction, as with classification tasks (e.g., nodes and edges). It’s possible for certain regional forecasts to be accurate even if the global one is off. Therefore, regression from model updates can occur at granular levels. It’s important to note that the output space is input-dependent and can be massive.
New research by Amazon investigates the regression of model updates on one general-purpose job (syntactic dependency parsing) and one application-specific task (sentence segmentation) (i.e., conversational semantic parsing). To accomplish this, they have established evaluation methods and tested various model updates originating from many places, such as modifications to the model’s design, training data, and optimization procedures. Their findings show that regression due to model updates is common and noticeable in many model update contexts.
The preceding result demonstrates the universal and pressing need for methods to lessen the occurrence of regression during model updates in structured prediction. Earlier work takes a cue from knowledge distillation, in which a new model (the student) is trained to suit the output distribution of the original model (teacher). Due to the difficulty in determining the precise distribution of global prediction, vanilla knowledge distillation cannot be easily applied to structured prediction models. And there are other methods to break down structured prediction’s end-goal forecasting.
According to researchers, a heterogeneous model update is whenever two or more models (each with a unique factorization). It is not possible to use factorization-specific approximation or even knowledge distillation at the local predictions’ level to update a heterogeneous model. This work uses sequence-level knowledge distillation to generate general solutions without assuming any particular factorizations. The model ensemble has provided a strong baseline for minimizing model update regression in prior work, albeit not as practical due to the high computing cost.
This work also introduces a generalized Backward-Congruent Re-ranking technique (BCR). BCR explores the wide range of results obtained by structured prediction. This means that a novel model can generate various predictions with comparable accuracy. The one with the most backward compatibility can be chosen.
In short, BCR takes a set of candidate structures predicted by a new model and utilizes the old model as a re-ranker to choose the best one. For better candidate diversity and quality, the team suggests dropout-p sampling, a straightforward and generalized sampling strategy. Contrary to expectations, BCR is both a flexible and surprisingly effective solution for preventing model update regression, significantly outperforming knowledge distillation and ensemble methods in all model update situations evaluated. Even more surprisingly, the results show that BCR can boost the new model’s precision.
The researchers believe these results are generalizable and can be applied in many different contexts, not just at Amazon. They suggest that other structured prediction tasks, such as text creation in NLP, image segmentation in computer vision, and scenarios of several rounds of model updates, can be investigated, and model update regression should be studied in these areas in the future.
Check out the Paper and Amazon Blog. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.