ByteDance AI Researchers Introduce ‘MagicVideo,’ an Efficient Text-to-Video Generation Framework based on Latent Diffusion Models

Generative AI models have come an extremely long way in the last few years. Their capability increased significantly with the advancement of diffusion models. Especially text-to-image generation with diffusion models produced really impressive results.
It did not stop there, though. We have seen AI models that could successfully achieve text-to-X generation. From style transfer to 3D object generation, these diffusion-based models surpassed previous approaches when it came to generating semantically correct and visually pleasant results.
The most attractive generation achieved was probably the text-to-video models. The idea of seeing how “an astronaut riding a horse with a koala by his side on the Moon” would look without spending hours in CGI was obviously very interesting to people. However, despite the very few successful attempts, text-to-video generation is still an underexplored task.
Text-to-video generation task is extremely challenging by its nature. It is especially difficult to achieve using diffusion models for several reasons. First of all, constructing a large-scale dataset of video-text description pairs is much more difficult than collecting image-text pairs. It is not easy to describe the video content using a single sentence. Also, there could be multiple scenes in the video where most frames would not give useful information.
Moreover, the video itself is a tricky source of information. It includes complex visual dynamics, which are way more difficult to learn than images. When you add the temporal information among different frames on top of that, it becomes really challenging to model the video content.
Finally, a typical video contains around 30 frames per second, so there will be hundreds, if not thousands, of frames within a single video clip. Therefore, processing long videos require a huge amount of computational resources.
These limitations forced recent diffusion-based models to produce low-resolution videos and then apply super-resolution to improve the visual quality. However, even this trick is not enough to reduce the huge computational complexity.
So, what is the solution? How can we transfer the success of image-generation models to video-generation task? Can we develop a diffusion model that can generate high-quality and temporally consistent videos? The answer is yes, and it has a name: MagicVideo.
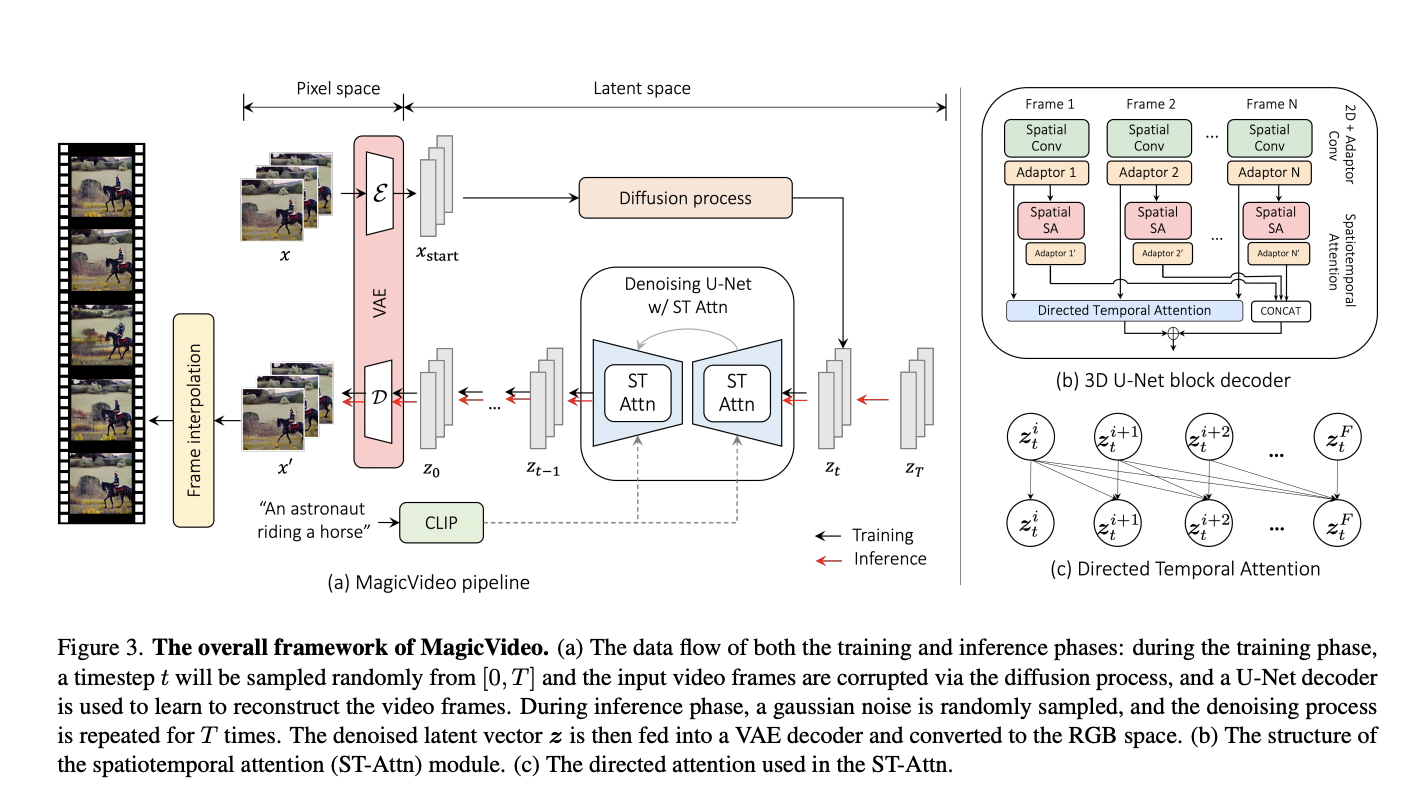
MagicVideo generates videos in the latent space using a pre-trained variational autoencoder. This trick enables an extremely reduced computational requirement for MagicVideo. Moreover, it has some more sleeves up on its trick to tackle the problems mentioned above.
MagicVideo uses 2D convolution instead of 3D convolutions to overcome having a video-text paired dataset. Temporal computation operators are used together with 2D convolution operations to process both spatial and temporal information in the video. Moreover, using 2D convolutions enable MagicVideo to use pre-trained weights of text-to-image models.
Even though switching from 3D convolution to 2D convolution significantly reduces the computational complexity, the memory cost is still too high. Thus, MagicVideo shares the same weights for each 2D convolution operation. However, doing so will reduce the generation quality as this approach assumes all the frames are almost identical, though, in reality, the temporal difference is there. To overcome this issue, MagicVideo uses a custom lightweight adaptor module to adjust the frame distribution of each frame.
MagicVideo learns the inter-frame relation using a directed self-attention module. Frames are calculated based on the previous ones, similar to the approach used in video encoding. Finally, produced video clips are enhanced using a post-processing module.
MagicVideo is another step forward toward reliable video generation. It achieves to transfer of the success of image generation models to the video domain. MagicVideo generates videos in the latent space to tackle the computational complexity.
This was a brief summary of MagicVideo. You can find information at the links below if you are interested in learning more about it.
Check out the Paper and Project. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.