This Artificial Intelligence (AI) Paper Presents a New Metric TETA and a New Model TETer for Tracking Every Thing in the Wild
Estimating the trajectory of items in a video clip is the goal of multiple object tracking (MOT). While specific MOT standards only consider tracking objects from a small number of pre-defined categories, such as pedestrians and cars, the actual number of types of interest is enormous. Although the recent expansion of MOT to a wide range of categories may appear insignificant, it presents important issues regarding formulating and describing the community’s problem. In the same video sequence in Fig. 1, they display the tracking results from two trackers. Tracker A follows the object flawlessly but classifies it slightly incorrectly at the fine-grained level. Tracker B accurately categorizes the thing but does not follow it.

The mMOTA metric assigns tracker A a score of 0 and tracker B a score of 33. The illustration above poses the following intriguing query: Is tracking still useful if the class prediction is off? The trajectories of misclassified or even unidentified objects are frequently nonetheless valuable. When following a van as a bus, for example, an autonomous vehicle may occasionally do so, but the projected trajectory can also be used for course planning and collision avoidance. The majority of current MOT models and metrics are created for tracking single-category numerous objects. They use the same single-category metrics and models by treating each class independently when applying MOT to large-scale multi-category scenarios.
The models first identify and categorize each object and only associate things in the same class. Similar to how tracking outcomes are grouped using metric class labels, each type is assessed independently. Since conducting associations and assessing tracking performance depend on classification, it is implicitly assumed that it is adequate. The abovementioned nearly flawless classification accuracy generally applies to benchmarks that only include a small number of widely used categories, like people and cars.
Due to the naturally occurring class hierarchy, it is challenging to discern between identical fine-grained classes, such as the bus and van, in Figure 1. This is different, though, when MOT encompasses numerous categories with many uncommon or semantically related classes. On unbalanced large-scale datasets like LVIS, the classification problem itself becomes very difficult.
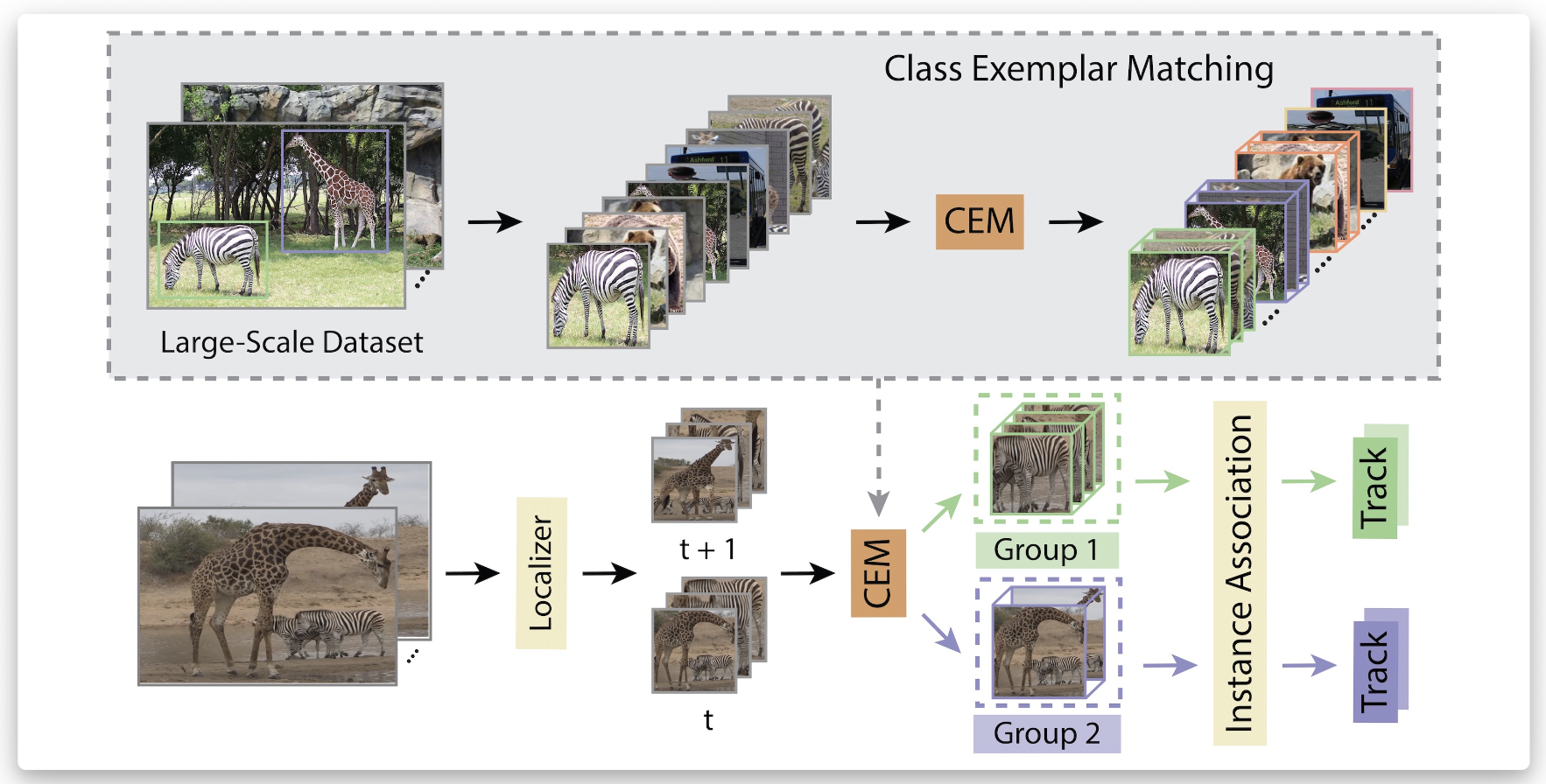
In addition, many items in real-world contexts do not fit into any predetermined category. As a result, they are treating each class independently without considering the error in classification results in poor benchmarking and undesirable tracking behavior. To extend tracking to a broader scenario, they suggest separating classification and tracking during model design and evaluation for multi-category MOT. To do this, they created a new model called the Track Every Thing tracker and a new metric called Track Every Thing Accuracy (TETA).
The suggested TETA metric separates categorization and tracking performance. To assess the localization and association performance, they use each ground truth bounding box of the target class as the anchor of each cluster and group prediction results inside each cluster. They employ location with local cluster evaluation rather than the expected class labels to group the outcomes of per-class tracking.
Thanks to their local clusters, they can evaluate tracks even when the class prediction is off. Additionally, because of the local cluster evaluation, TETA can handle partial annotations, typical in datasets with many classes, like TAO. Their TETer uses an Associate-Every-Thing (AET) approach. They associate each object in adjacent frames rather than only those belonging to the same class. The difficult classification/detection problem in large-scale, long-tailed environments is liberated from the association by the AET technique. Nevertheless, while completely ignoring the class information during association, they suggest a new method of utilizing it that is resistant to classification mistakes.
They present Class Exemplar Matching (CEM), in which the learned exemplars softly contain important class information. They can effectively utilize semantic supervision on huge detection datasets by avoiding the frequently inaccurate classification output. Performance can be constantly enhanced by CEM and can be included in current MOT techniques. Additionally, their tracking technique enables us to use extensive temporal information to correct the per-frame class predictions. On the recently released massive multi-category tracking datasets, TAO and BDD100K, they conduct their analysis of their methodologies. Their thorough research demonstrates that, despite incomplete annotations, their metric achieves better cross-dataset consistency and a more comprehensive evaluation of trackers. In addition, their tracker performs at the cutting edge on TAO and BDD100K, both when using the conventional metrics and the suggested TETA. Some fun results can be found on the project website.
Check out the Paper and Project. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.