Stanford AIMI Researchers Found a Way to Generate Synthetic Chest X-rays by Fine-Tuning the Open-Source Stable Diffusion Foundation Model

There are many multi-modal foundation models existing, which are typically trained on millions of natural images and their text captions. Medical images are just a small portion of the whole distributed dataset. These datasets are not effective for domain-specific tasks since medical field professionals use different terminologies and semantics. There are dedicated datasets available, but they are very heavily priced in terms of computing power. This created barriers to proceeding with many research topics.
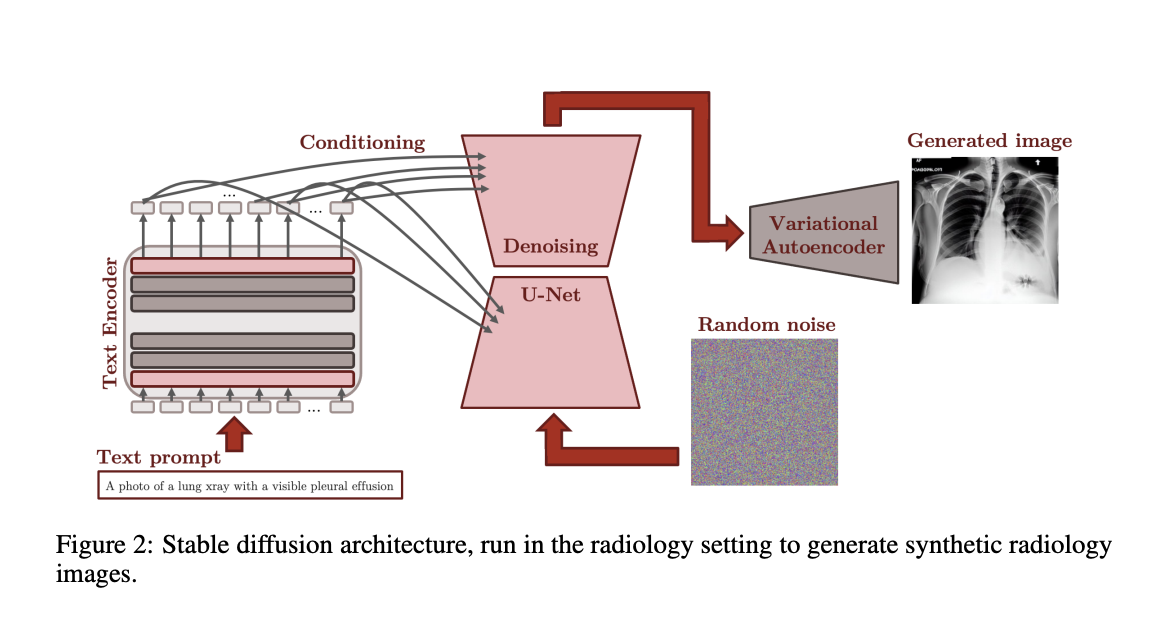
Stanford AIMI scholars came up with building generative models using these open-source datasets for medical images that will help reduce the gap in training data in healthcare datasets. Therefore, they came up with the notion of improving the Stable Diffusion model to generate domain-specific images in medical imaging. The scientists managed to find a method to generate X-rays images by fine-tuning the Stable Diffusion model.

The primary advantage was that the radiologists always make a detailed report of the characteristics of the X-ray or any other medical image. If they add the report to the training data of the Stable Diffusion model, it can learn to produce synthetic medical images when those keywords described by radiologists are used. For the training and testing datasets, two popularly known medical datasets, CheXpert, which contains 224,316 chest radiographs, and MIMIC-CXR, which contains 377,110 images, were used.
The research team tweaked the five components of the Stable Diffusion model:
- A variational autoencoder, VAE, compresses the source images and reconstructs the generated compressed images. It also removes high-frequency details which are unnecessary.
- A text encoder which converts the report or the written prompts into vectors that the autoencoder can understand.
- Textual Projection, in which the CLIP text encoder is replaced with a domain-specific encoder pretrained on radiology data.
- Textual Embedding Fine-Tuning, in which new tokens are added to describe patient-level features such as gender, age, etc.
- The U-Net fine tuning which serves as the brain for the diffusion process, which creates images in the latent space. In this, all the components except the U-Net were kept frozen, which helps create better-looking domain-specific images.


After the experiment, the scientists successfully came up with the best-performing model, which had 95% accuracy on a deep learning model. The model was announced on the 23rd of November 2022, which can create chest X-ray images with higher fidelity and diversity and increased resolution favoring more fine-grained control over the image through natural language prompts. Clinical accuracy was a challenging stepstone for this experiment because it needed qualitative assessment by a trained radiologist. There was also some compromise made on the diversity of fine-tuned images. The simplified terms utilized in the text prompt to further train the U-Net for its radiology use case were constructed specifically for the study and were not taken precisely from actual reports from radiologists. Full or constrained portions of radiology reports should constrain future models should be constrained by full or constrained portions of radiology reports.
This experiment surely improved the quality of healthcare data. This conquered one of the primary challenges in the medical field. There are surely more improvements to do further in this line of the study. Methods for the training of medical images with more efficiency and domain-specific changes are yet to be explored. There is a lot of scope in this research field that can improve healthcare facilities worldwide.
Check out the Paper and Stanford Article. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
I am an undergraduate student at IIIT HYDERABAD pursuing Btech in computer science and MS in Computational Humanities. I am interested in Machine and Data learning. I am also actively involved in research on AI solutions for road safety.
Credit: Source link
Comments are closed.