This Artificial Intelligence (AI) Method Uses Fragment Sampling to Efficiently Determine Video Quality
Video has become the preferred way of communication on the Internet nowadays. From getting daily news videos on Twitter to watching never-ending short videos on Instagram, it is almost impossible to pass a day without seeing video content.
Every day we see more and more variety in the video content uploaded to our favorite social media channels. Thanks to the powerful camera systems in our smartphones, it has become really easy to capture and share videos. Also, the increasing capturing capabilities of the daily devices made it possible to record high-resolution and high-framerate videos, which was only possible with professional-grade devices just a couple of years ago.
The increase in video content produced by people brought challenges along when it came to video quality assessment. Video quality assessment evaluates a video’s visual and auditory experience by measuring various aspects of its content and presentation. This process typically involves analyzing the video’s resolution, frame rate, color depth, and other technical aspects, as well as the overall aesthetic quality of the video, such as its sharpness, contrast, and noise level. Video quality assessment is an important part of the video production process, as it helps ensure that the final product meets the desired standards and is enjoyable to watch.
For professional-grade videos, assessing quality is relatively simple because the source video, which does not contain encoding artifacts, is available. Therefore, you only need to compare the resulting video with its original version and determine the amount of degradation to assess quality. However, regarding the user-generated content, we don’t have the source video available. We only have the uploaded version, which is already encoded. This makes quality assessment more tricky.
Classical video quality assessment (VQA) methods use hand-crafted features to measure the quality. However, these features are not easy to extract for user-generated content. On the other hand, deep learning-based visual quality assessment methods have proven to perform superior to their traditional counterparts in recent years. The problem with deep learning methods is their complexity which is especially problematic for higher-resolution videos.
So, there is a need for a reliable and efficient method to assess the visual quality of videos. This is where FAST-VQA comes into play.
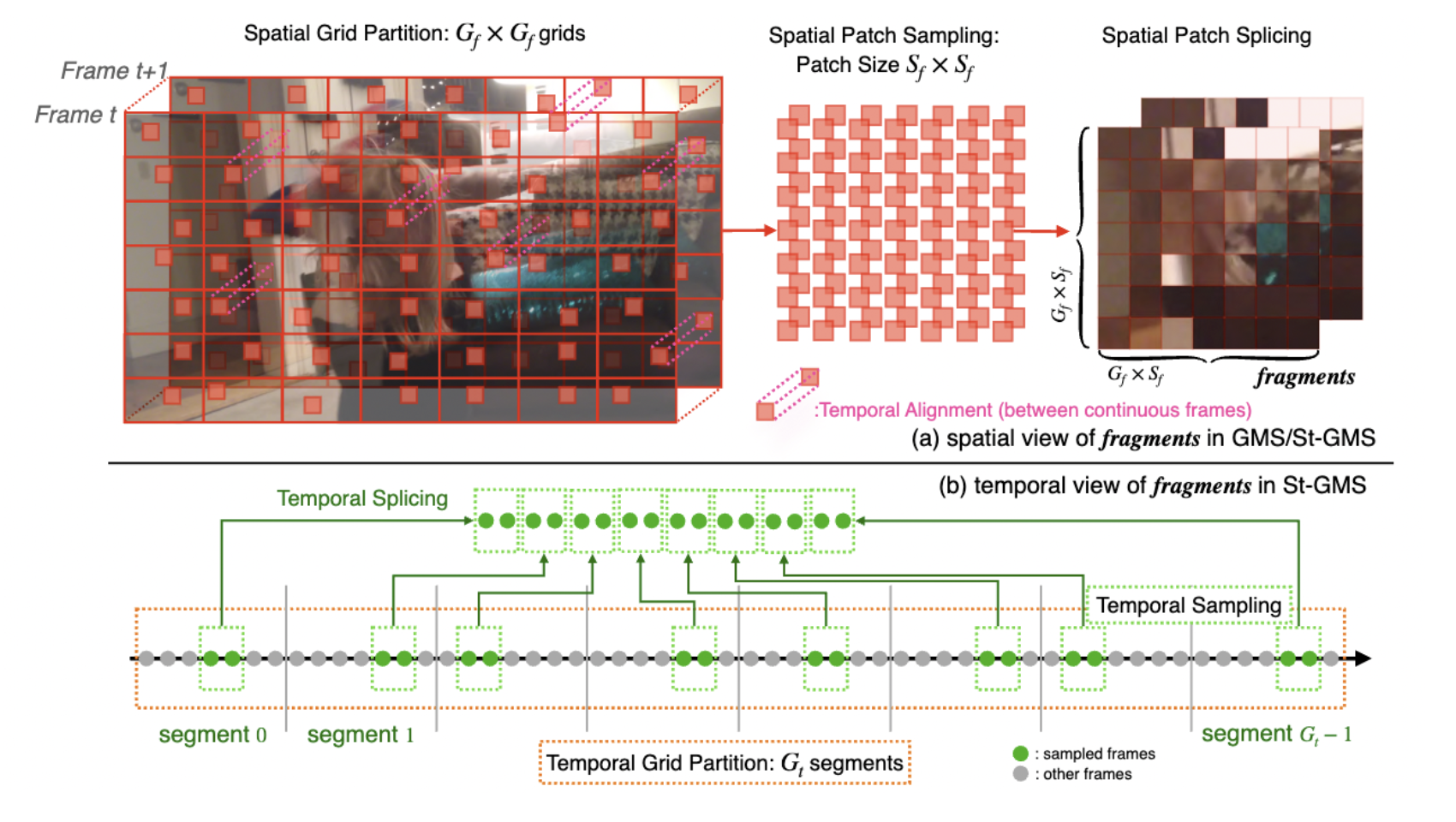
To tackle the complexity of deep learning methods, FAST-VQA uses a new sampling scheme, namely grid mini-patch sampling. GMS divides videos into grids that are spatially homogeneous and don’t overlap, randomly selects a mini-patch from each grid, and then combines mini-patches. Moreover, to ensure the patches are sensible to temporal differences, they are aligned together. These spatially and temporally aligned patches are called fragments, which make the core of FAST-VQA.
FAST-VQA uses a neural network to process the extracted fragments from the video to predict the visual quality. The network should be designed carefully to process these fragments, which are spatially and temporally aligned. The network should extract local information in the fragments as well as recognize the artificial discontinuity that occurred due to the alignment. Therefore, FAST-VQA uses a fragment attention network combined with a swin transformer to process this information.
Overall, FAST-VQA can learn video-quality related features efficiently through end-to-end training and can outperform state-of-the-art solutions in accuracy.
Check out the Paper and Github link. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.