Allen Institute for Artificial Intelligence Introduces ACCoRD: A Multi-Document Approach to Generating Diverse Descriptions of Scientific Concepts

We have all encountered new words we were unfamiliar with while reading scientific research papers. It can be difficult for a total novice to comprehend new scientific notions. In the worst-case scenario, it may also result in eventual procrastination due to demotivation. Although even the most well-known of these concepts can be clarified using online resources like Wikipedia, most scientific terminology used in literature needs to be adequately explained online.
Previous work in natural language processing (NLP) has attempted to address this issue by developing systems that can automatically extract or produce descriptions for scientific concepts using the text in the research publication. The primary problem is that papers rarely define the terminologies they employ. Additionally, these systems are only intended to offer one “best” description that is appropriate for all users in a general sense.
However, a single topic can be explained in a variety of ways, and the explanation that is most beneficial to one person may not be the most effective for another. This frequently occurs because, as humans, we have the propensity to enrich an already-existing methodology with our specific previous knowledge while seeking to determine a novel concept. This is especially true when reading materials as complicated as scientific papers; knowing how new concepts fit into our existing conceptual framework might make it easier to understand what we read.
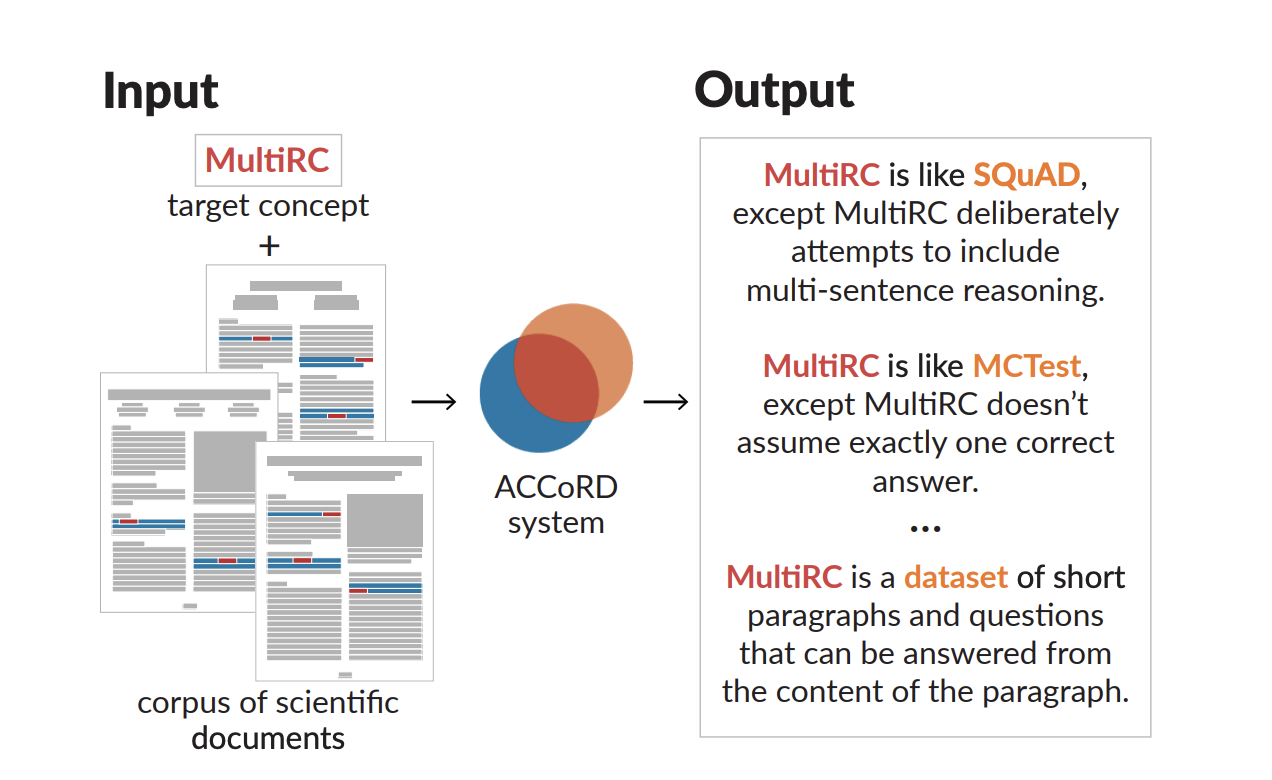
To introduce a solution to the challenges mentioned earlier, Allen Institute for Artificial Intelligence (AI2), in its most recent effort, developed ACCoRD, an end-to-end system that takes on the unusual task of creating sets of descriptions of scientific concepts. Instead of concentrating on a single “best” description-generating paradigm, their approach makes use of the numerous ways a concept is referenced across the scientific literature to develop unique and varied descriptions. This new task is termed Description Set Generation (DSG). The team also made available the ACCoRD corpus, an expert-annotated resource, to aid in research on this and related topics. This corpus includes over 1,275 labeled contexts and 1,787 hand-authored concept descriptions. Their work also gained recognition in the System Demonstration track of the esteemed EMNLP 2022 conference.

The ACCoRD approach creates diverse descriptions of target concepts in terms of distinct relation types and reference concepts by utilizing the fact that a concept is expressed in various ways throughout scientific literature. This is accomplished through a three-stage process. The first phase involves utilizing SciBERT, a pre-trained language model for scientific writing, to extract context phrases from texts that define a particular scientific concept. The ACCoRD corpus is then used to refine this model further. This extraction process concentrates on circumstances that explain a target concept in terms of a reference concept.
The following stage utilizes GPT-3 in the few-shot mode to generate a condensed form of self-contained descriptions of the target’s relationship to each reference concept from the extracted contexts. A final description set is chosen from the generations in the concluding phase by prioritizing a varied assortment of descriptions covering various relation types and reference concepts.
According to further experimental evaluations, various concept descriptions developed as a result of the team’s methodology were favored over other standard approaches. One can access the output of the ACCoRD system for 150 widely used NLP concepts at accord.allenai.org. They have also made the ACCoRD corpus available to aid in the creation of future DSG systems, with the objective that these systems will contribute to greater accessibility of scientific material for readers with varied scientific backgrounds.
Check out the Paper, Github, and AI2 Article. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.