Data-Centric Computer Vision with Superb AI’s DataOps Platform
Data-Centric Computer Vision is a term inspired by Data-Centric AI – the process of building and testing AI systems by focusing on data-centric operations rather than model-centric operations. However, many existing challenges exist with iterating on datasets to improve model performance.
- When you have data stored across multiple systems that are poorly integrated, it will be much harder to find, access, and evaluate datasets. Some companies resolve this problem by tasking data/ML engineers with making data available to data scientists (or whoever is building the model). But then these engineers spend all their time just moving data to and from S3 buckets.
- There is a lot of duplicate work being done across ML teams and the entire organization – where the data preparation and feature engineering work cannot be easily repurposed.
- Finally, there is the challenge of working with unstructured data. There should be tools that let you link your structured data with your unstructured data, so you can quickly develop a profile of what might be contained within your unstructured datasets.
As a result, there is an increasing need for DataOps for unstructured data that can systematically orchestrate data-centric operations like data ingestion, data labeling, data quality assurance, data curation, and data augmentation.
This article will propose an ideal DataOps workflow for the modern computer vision stack, discuss the significant challenges of handling visual data, and introduce Superb AI’s DataOps platform for data-centric automation that helps teams build better computer vision applications.
DataOps For The Computer Vision Stack
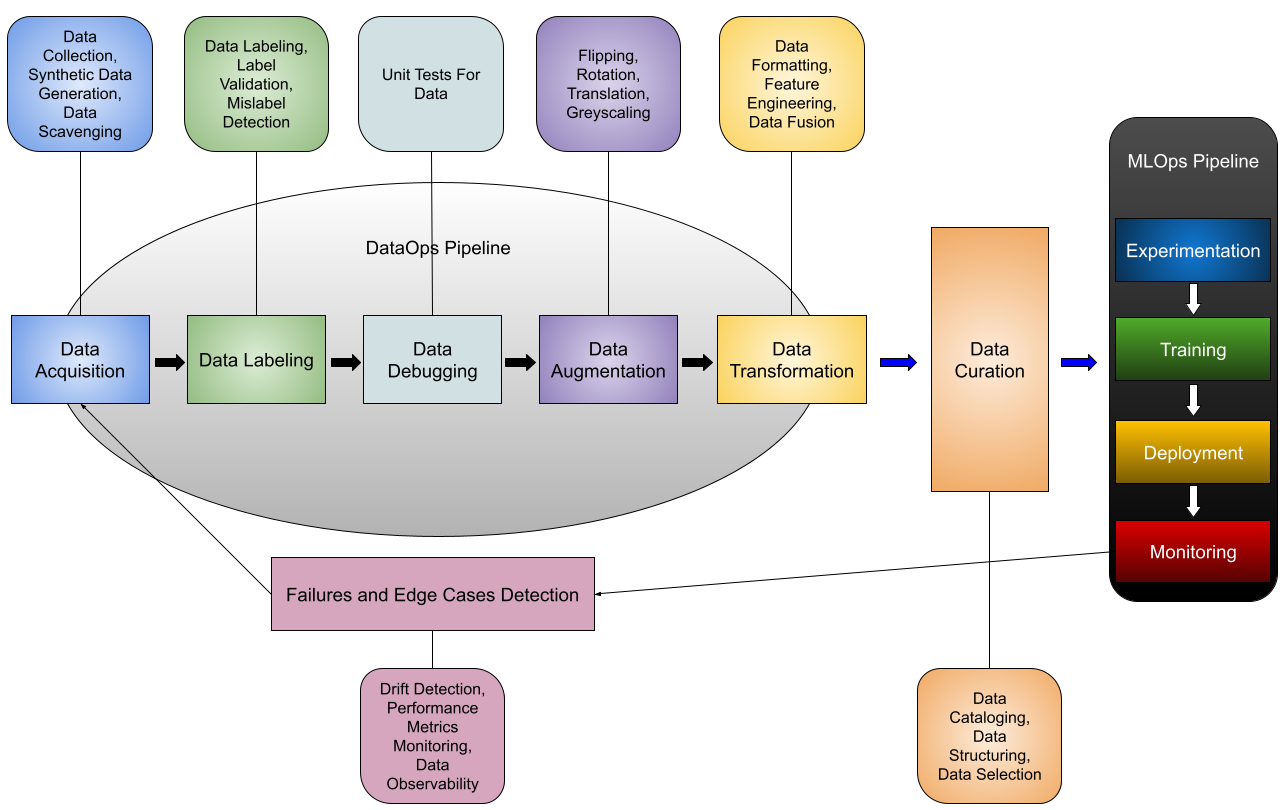
1 -Data Acquisition
The first phase of our computer vision workflow is data acquisition:
- When we talk about data acquisition, we tend to think about data collection. There are both physical and operational considerations with this — ranging from where to collect the data to how much to collect initially. To get data collection right, we need a feedback loop aligned with the business context.
- Synthetic data generation is a second approach with many use cases ranging from facial recognition and life sciences to eCommerce and autonomous driving. However, getting this synthetic data requires many training data and compute. Furthermore, synthetic data is not realistic for unique use cases, and there is a lack of fundamental research on their impact on model training.
- A third approach is data ‘scavenging’ — where we scrape the web or use open-source datasets (Google Dataset Search, Kaggle, academic benchmarks)
2 – Data Labeling
The second phase is data labeling. This is an industry of its own because we have to answer many questions: Who should label it? How should it be labeled? What should be labeled?
Indeed, getting the data labeling step right is highly complicated because it is error-prone, slow, expensive, and often impractical. Efficient labeling operations would require a vetted process, qualified personnel, high-performance tools, its own lifecycle, a versioning system, and a validation process.
3 – Data Debugging
The third phase is data debugging, which entails writing expectation tests to address the data preprocessing and storage system. Essentially, they are unit tests for your data. They are designed to catch data quality issues before they make their way into the DataOps pipeline.
4 – Data Augmentation
The fourth phase is data augmentation, a scientific process where we can manipulate the data via flipping, rotation, translation, color changes, etc. However, scaling data augmentation to bigger datasets, negating memorization, and handling biases/corner cases are fundamental issues.
5 – Data Transformation
The fifth phase, data transformation, includes three steps:
- Data formatting: This is a small slice of the whole data engineering task that interfaces with data warehouses, data lakes, and data pipelines.
- Feature engineering: This includes concepts such as feature stores, management of correlations, management of missing records, and going from feature selection to embeddings.
- Data fusion: This last step means fusing data from different modalities, sensors, and timelines.
6 – Data Curation
The sixth phase is data curation. Because the dataset is so large, we must be picky about the types of data we will use. Thus, we need to catalog, structure and select the data methodologically.
7 – Failures and Edge Cases Detection
To close the feedback loop of the MLOps lifecycle, your system should be able to detect failure cases (in which your model makes failed predictions) and use them to generate a new training dataset (that can be fed into the next version of your system). This final phase includes practices such as drift detection, performance metrics monitoring, and data observability.
Workflow without DataOps
There are many tasks that CV engineers can’t do well due to the lack of tooling, time, and data.
- Data Visualization and Feature Extraction
- Training and Test Set Split and Data Curation
- Data-Centric AI
Let’s go through each of them and illustrate how DataOps can solve these issues.
1 – Data Visualization and Feature Extraction

The frame above shows your typical dataset. You see all types of data with different colors, shapes, and backgrounds. Your task is to turn them into the frame below, which entails clean and clustered samples of images. As an engineer, you go through these images, cluster them based on similarity, and develop models to do this task automatically. Essentially, you need to look at a lot of images and come up with feature ideas.

Right now, this process is done manually. CV engineers have to manually visualize each image one by one, go through them with human eyes, and go through this cycle multiple times to come up with feature ideas. The CV engineers’ time can be spent on something else.
2 – Training/Test Set Split and Data Curation

It is important to choose and split your training and test sets. To illustrate with an example above, if you only train your model on the top row and test it with the top row, your model will only do well on those types of cups but won’t do so well on the types of cups in the second or third row. That’s why you need to train and test your model in a well-balanced dataset.
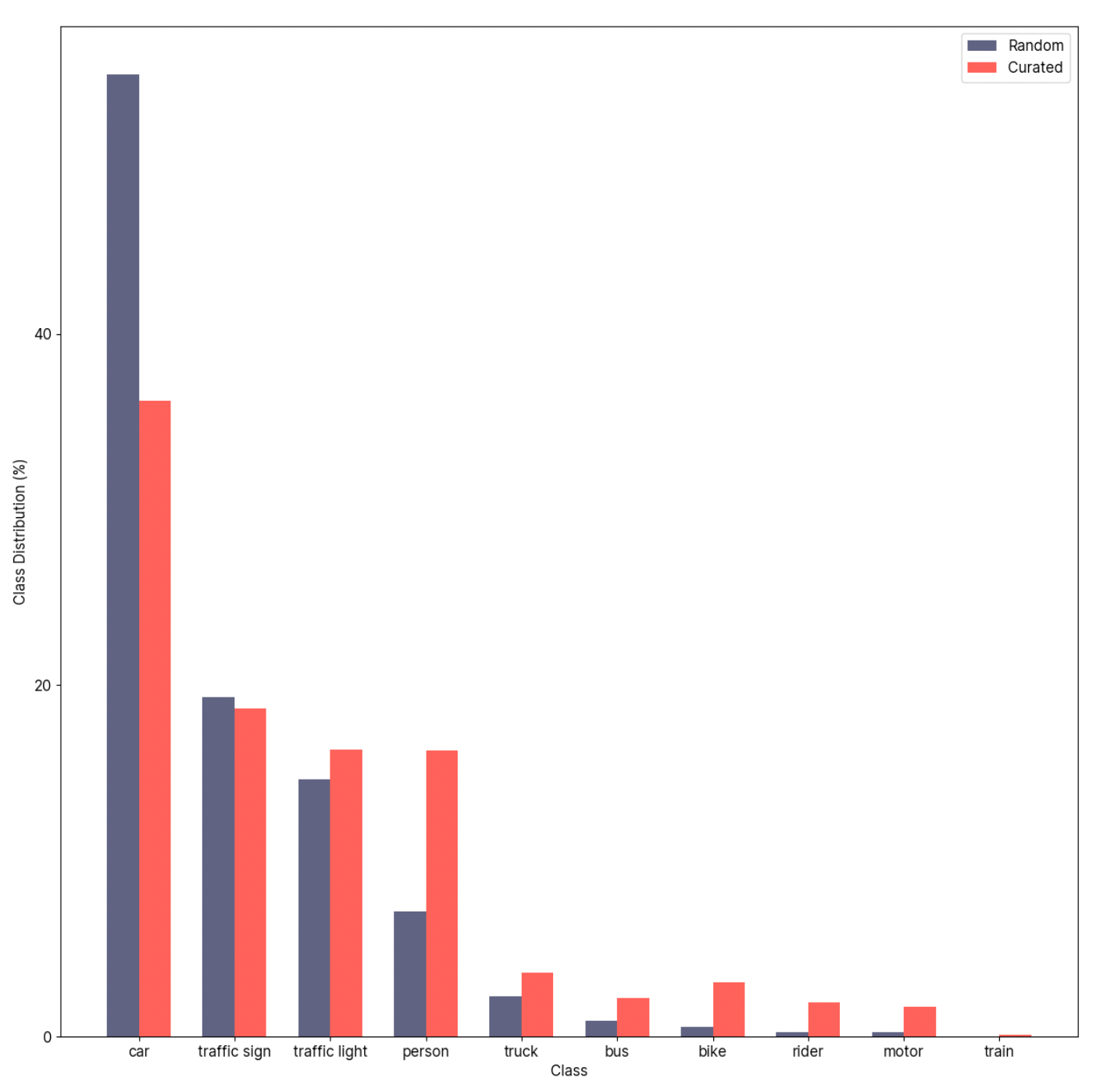
This diagram above is another example to illustrate data bias and why data curation is important. It comes from a curation report that our team at Superb AI has created, which is based on “BDD100K” (a self-driving car dataset for autonomous vehicle use cases). There’s a huge long-tail problem, as you can see on the grey bars, which come from the original random distribution of objects. There are many more “car”, “traffic sign”, “traffic light”, “person” objects than the rest. If you train your model on this randomly-sampled dataset, your model will perform really well on the over-sampled objects and perform poorly on the under-sampled objects.
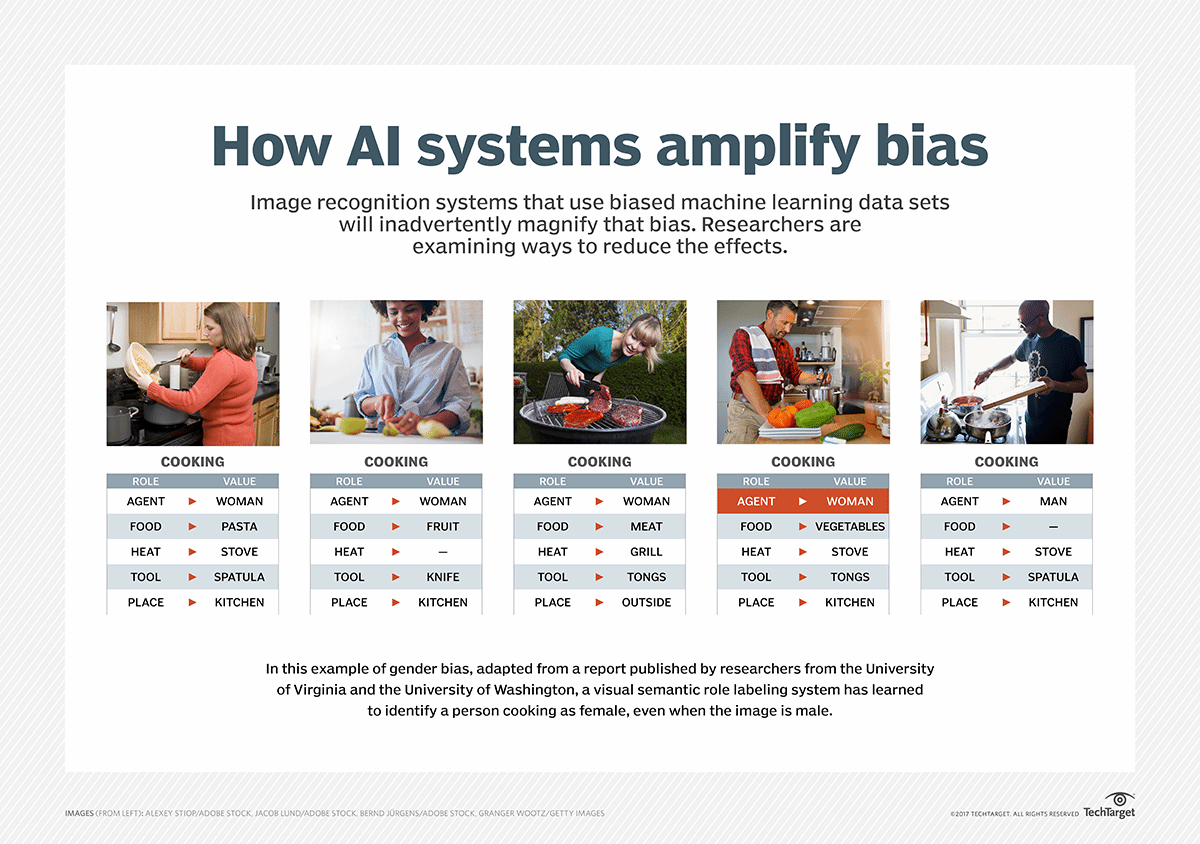
The example above is another example of gender bias. The “cooking” activity is associated with the “woman” agent role, so the model has learned to identify a person cooking as female, even when the image is male.
3 – Data-Centric AI
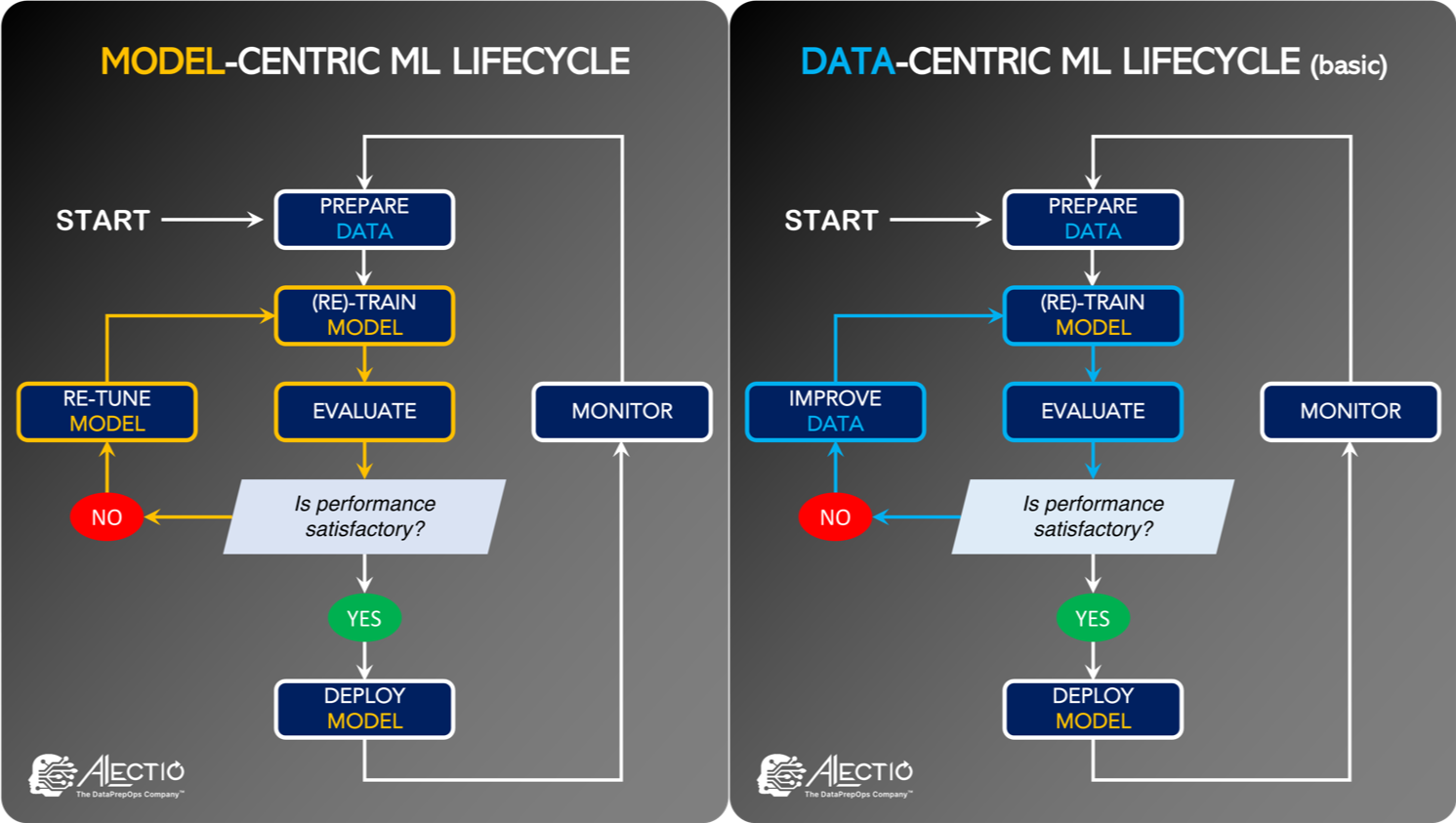
A quick recap: Data-Centric AI is the process of building and testing AI systems by focusing on techniques meant to improve and optimize the data (rather than the model). Broadly speaking, there are three ways to improve the data:
- By modifying labels: Labeling large-scale data is insanely expensive, time-consuming, and error-prone. Under certain conditions, it is possible to rely on a pre-trained Machine Learning model or a weakly supervised approach to generate labels faster. Additionally, you can use Human-In-The-Loop – where a human agent identifies and fixes labeling errors and imperfections.
- By modifying an existing dataset: You can use active learning to decide what data samples to remove and augment.
- By collecting or generating new data: While this might seem obvious, another way to improve a dataset is to add more data, preferably in a strategic manner. Guiding the collection or the generation of new data in a way that positively impacts the learning process of the model and makes it more efficient is a topic that sadly doesn’t get enough attention from researchers.
Right now, due to the lack of tooling, time, and data, most CV engineers tweak models when their models underperform.
Introducing Superb AI’s DataOps Platform
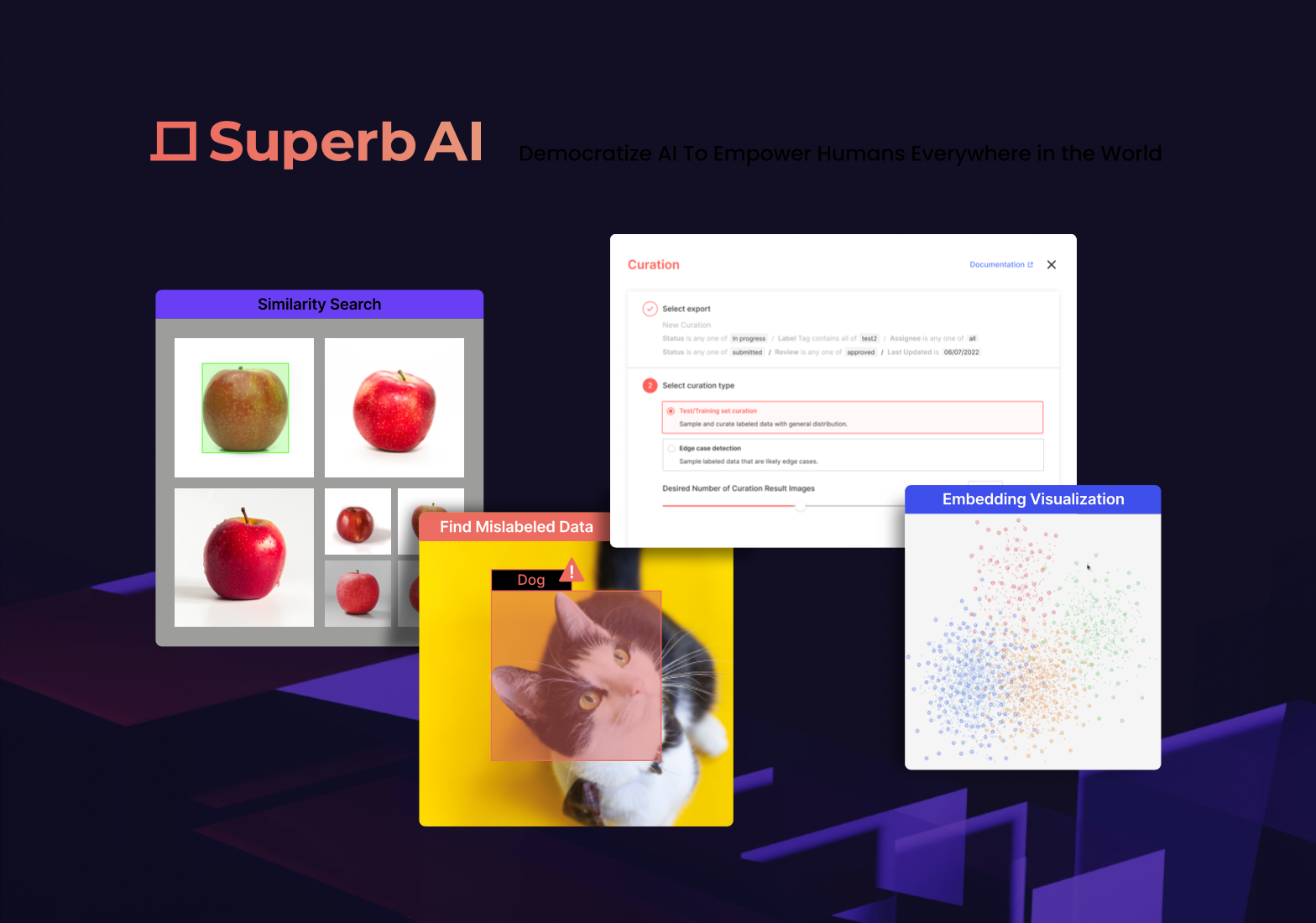
Superb AI’s DataOps is an automated data quality assurance and curation platform that empowers CV/ML engineers and data project managers to explore, evaluate, and improve their vision-based datasets more easily while reducing labeling, QA, and engineering spending.
The initial release of DataOps (in beta – Join the Waitlist) consists of the following AI-enabled features:
- Mislabel Detection to detect misclassified bounding boxes and segmentation annotations in images.
- Edge Case Detection, which finds and mines edge cases in datasets to prioritize for labeling and constructing test/training sets.
- Auto Curation to automatically curate test and training sets with matching data distribution.
- Image Similarity Search, which uses embeddings to find clusters of visually similar images and objects within a dataset.
- Natural Language Query to quickly explore and find needed data.
- Embedding Store, which visualizes datasets in a 2D space to better understand dataset composition and distribution.
Workflow with DataOps
Let’s revisit the three workflow issues without DataOps:
- Data Visualization and Feature Extraction: DataOps solves this with Embedding Store and Data Visualization.
- Training and Test Set Split and Data Curation: DataOps solves this with Auto Curation.
- Data-Centric AI: DataOps solves this with Edge Case Detection and Mislabel Detection.
1 – Embedding Store and Data Visualization
With DataOps, you can leverage our Embedding Store and Data Visualization on top of that Embedding Store.
An embedding is a way to represent information from an N-dimensional space into a much lower dimensional space (considered a vector of numerical data), thus preserving relevant information about the sample while drastically reducing the cost of storing and processing the information. Essentially, given a set of images, an embedding store can curate them into a format that the machine can easily understand and compare.

Given a big cluster of images on the left, an embedding store can cluster them into smaller clusters of occluded images, images that are behind bars, and images with various vehicles. In brief, you can create embeddings for your dataset, look at different sections of those embeddings, cluster different images you are looking for, come up with ideas, and find patterns for your model development process.

The diagram above shows a sample workflow with the Embedding Store:
- Given a labeled dataset for an autonomous vehicle (AV) use case, let’s say you want to find specific images with red cars at night.
- Within the Embedding Store UI, you can apply the language query “red car” and the image query “night” in order to search for those instances.
- After checking the results via the embedding visualization, you can apply the new tag “red cars at night” to these images.
Here are the main benefits of this workflow:
- You can search, analyze, and understand the dataset better.
- You can change classes of visually similar data subsets. Let’s say there are several images already labeled as “car.” You can select an image of a police car and find similar images to that one. Finally, you can relabel the new subset as “police cars.”
- You can add additional labels. Let’s say your AV dataset only has the ‘objects’ labeled, but not the ‘weather conditions.’ You can search for the term “rainy,” select all of the returning results, and add “rainy” as a new class property of those images.
2 – Auto Curation

To help with the training/test split and data curation challenges, we have been developing an Automatic Curation feature.
You can split your dataset into training, validation, and test sets at the beginning of your model development. Similar to the test set, the validation set is split from the training set to check your model performance progress. Our curation feature deliberately splits these three sets in a balanced way, even before you start developing your model.
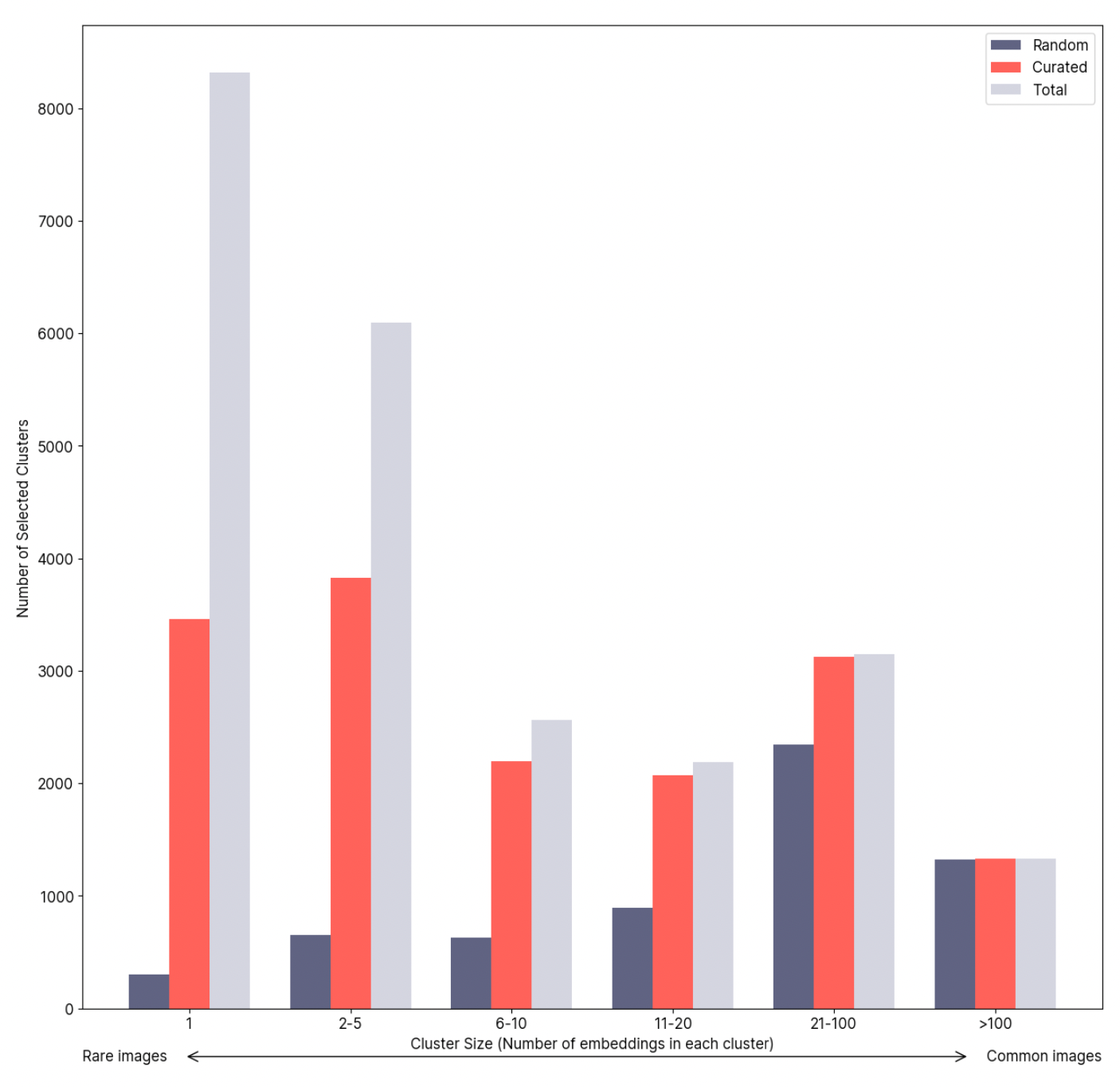
The graph is another sample from our Curation report. The Y-axis shows the number of embedded clusters, while the X-axis shows the cluster size. The left side contains rare images (edge cases), while the right side contains commonly found images. When you look at the dark blue bar and the red bar, the dark blue bar picks up a lot more common images. If you train your model on the randomly sampled dataset, it will do poorly on the edge cases. Our curation algorithm tries to pick up as many rare images as possible, so the model can react and perform well on those edge cases.
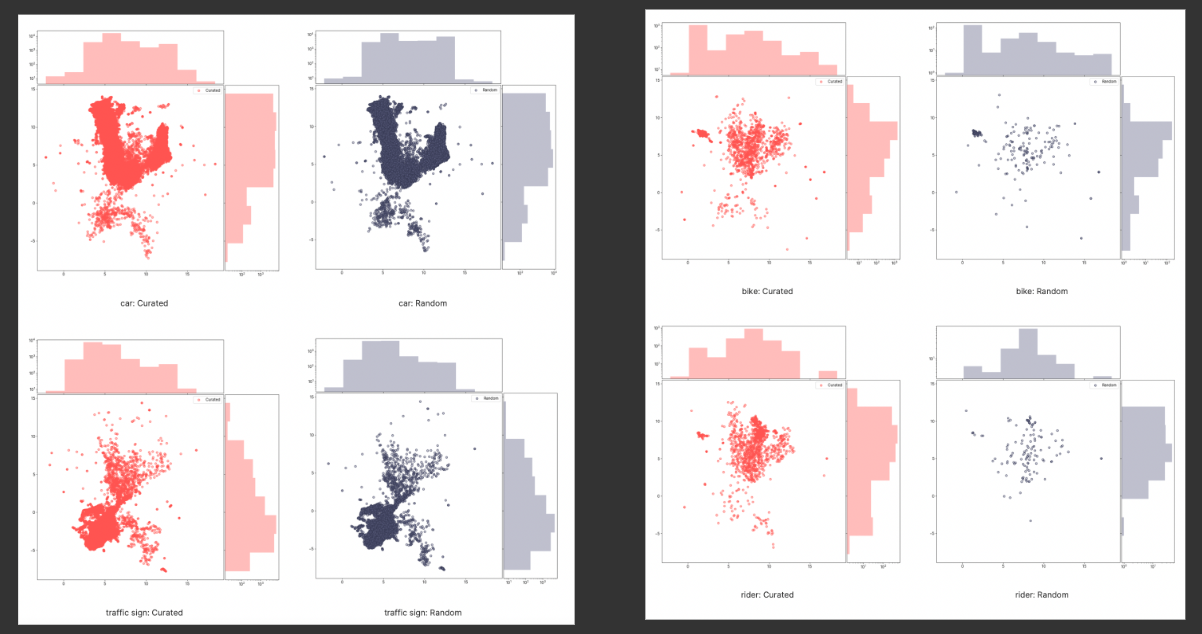
Let’s look at another example of our curation report from the BDD-100K dataset:
- For object classes that are quite common, like “car” and “traffic sign”, there are not so many differences between the distributions of the curated dataset and the random dataset.
- But as you can see on the right, “bike” and “rider” are very rare objects. Our curated dataset picks out many more of these objects than the random dataset. This is how we choose a balanced dataset for your model training and testing.
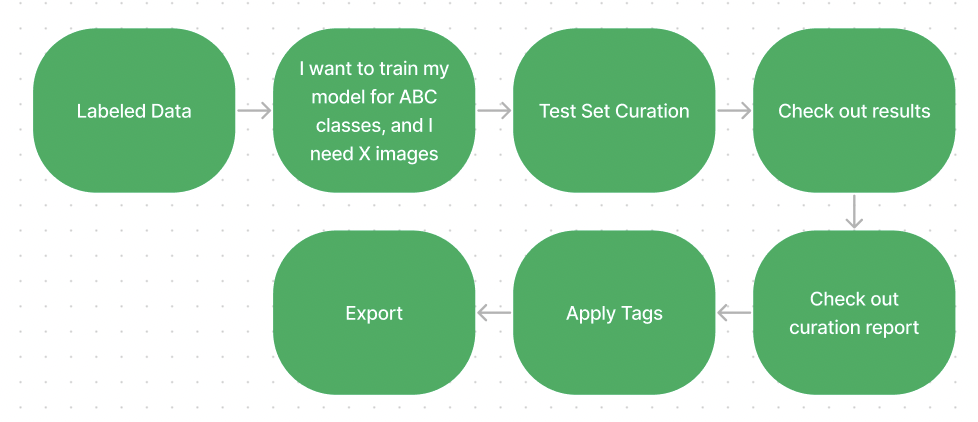
The diagram above shows a sample workflow with Automatic Curation:
- Given a labeled AV dataset, let’s say you want to train your model for a specific number of classes. You would need a specific number of images for your training and test sets.
- With Automatic Curation, you can automatically curate your training and test sets. You can check out the results and configure the curation settings as desired.
- After checking the curation report, you can apply new tags, export these images, and use these exports for model training.
Here are the main benefits of this workflow:
- You have a better-distributed training and test set for model training, which consequently results in better model performance.
- You utilize automatic curation based on embeddings instead of relying on heuristics and manual labor.
- You can even cold-start Superb AI’s automated labeling capabilities by curating a good training and validation set to use.
3 – Edge Case Detection and Mislabel Detection
Edge case detection is an extension of our Embeddings Store feature. After visualizing and finding different clusters with similar image characteristics, you can combine them with another feature currently in beta called Model Inference Uploading to see which clusters are performing well (versus not well).

In this example, occluded images and images behind bars are edge cases that perform poorly based on our model results. On the other hand, our model seems to perform well on images with various vehicles. With these insights, you can make intelligent decisions on what types of images to collect more.
Additionally, we are also developing a Semantic Search capability. To find more edge cases, you can feed them into our Semantic Search feature, which will discover images with similar semantics to the edge cases. If you keep feeding more edge cases into subsequent iterations of your model, your model will eventually perform well on these edge cases.
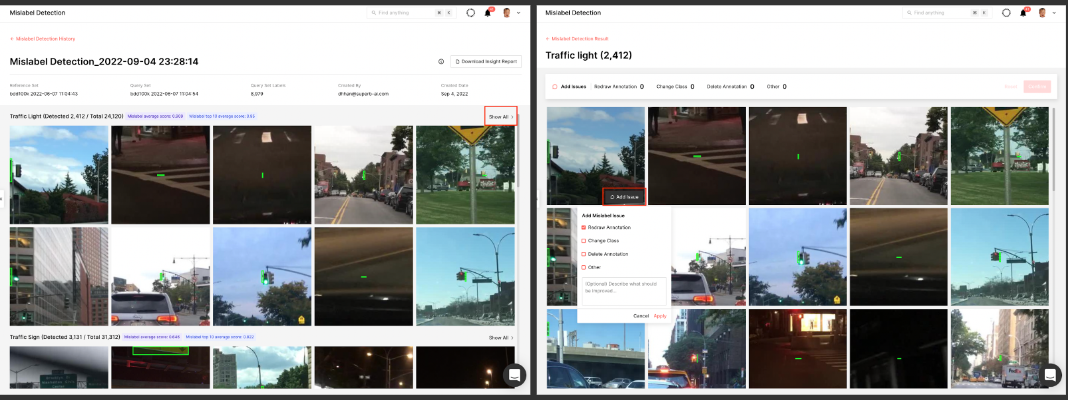
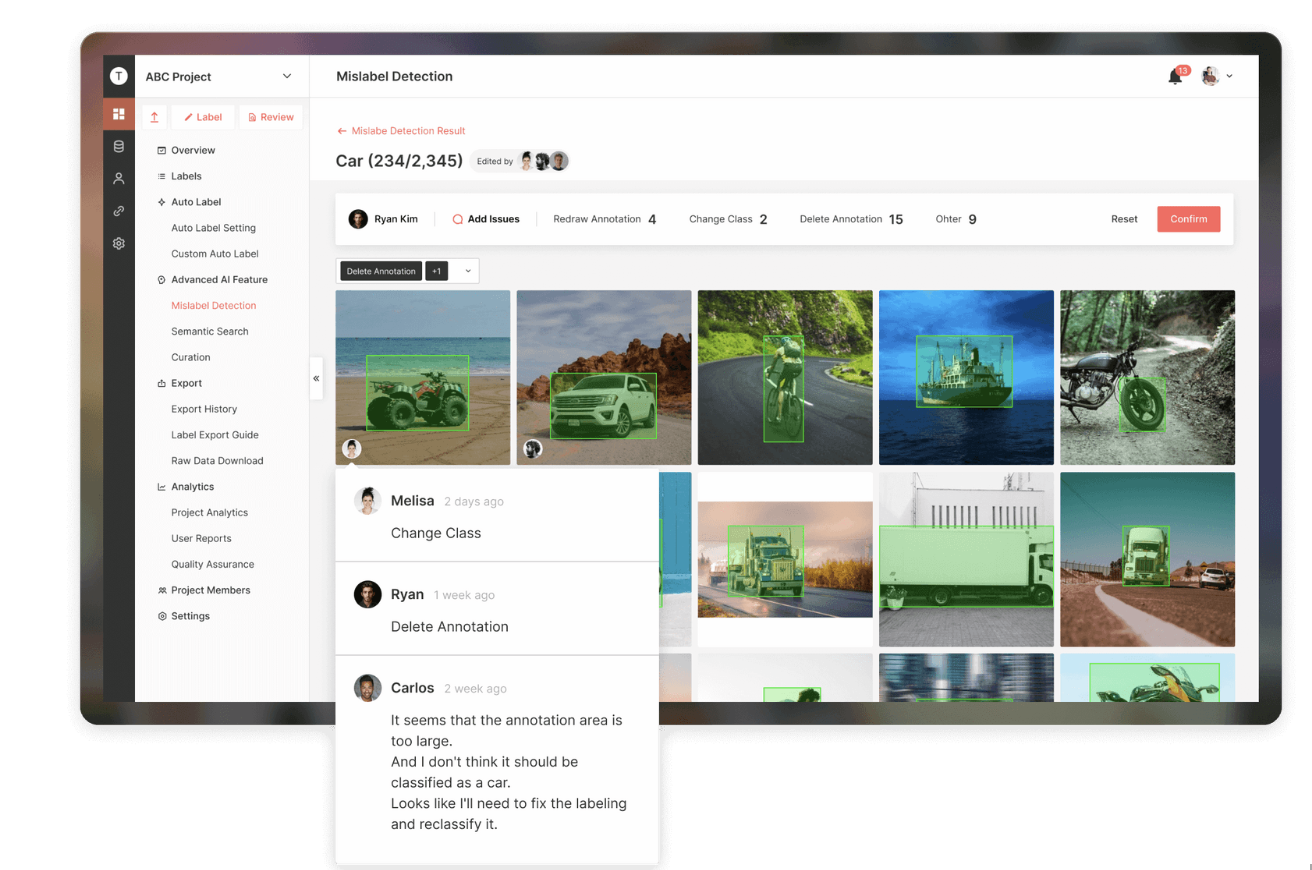
Mislabel detection is a feature for the Data QA purpose. It is an auto QA feature that automates the curation process to make it more efficient.
Right now, it sorts the labeled data by order of mislabel scores. It shows you images that are likely to be misclassified. We are looking to improve this feature and iterate on it to provide you with more capabilities – such as fixing labels on the spot and putting those mislabeled images in a queue for labelers to review.
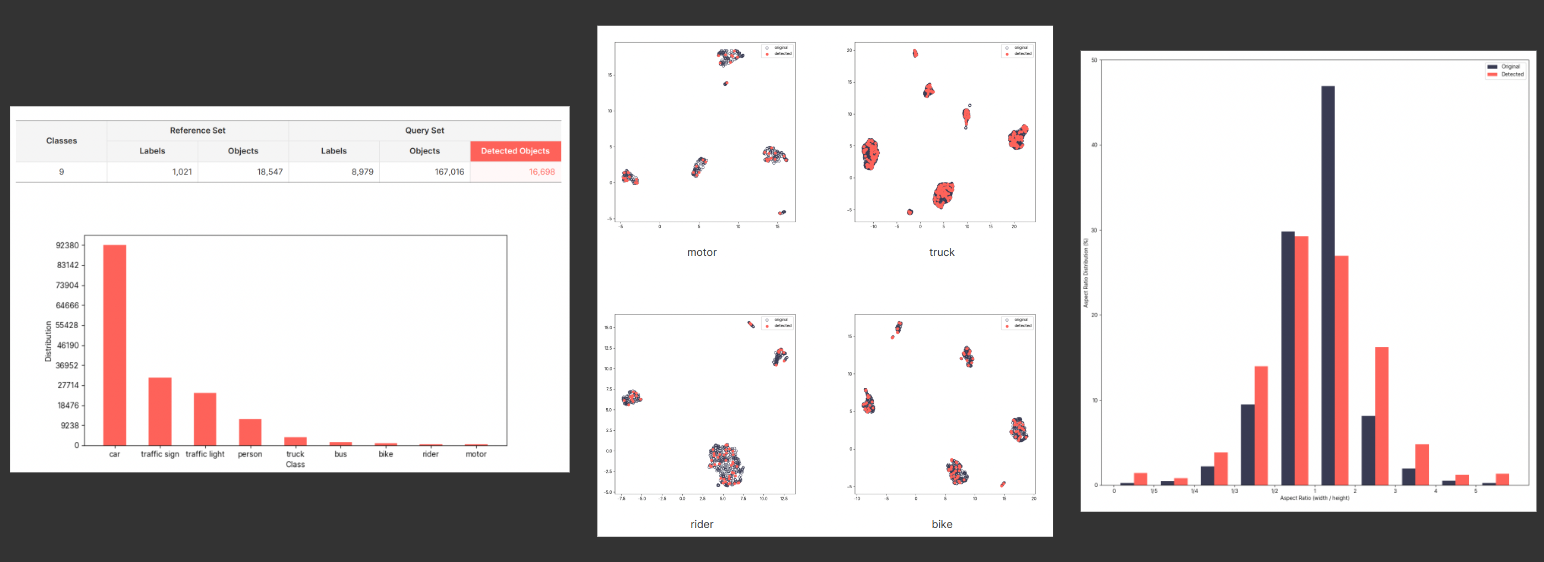
Another part of this feature is a Mislabel Detection report. This report shows you patterns in your data: (1) Classes that are likely to be mislabeled, (2) Visualization of different object classes so that you can QA them efficiently, and (3) Based on the size and width of your data, how many mislabels there are for each aspect ratio. You can use this information to fine-tune your labeling guidelines and understand your dataset better.

The diagram above shows a sample workflow with Mislabel Detection:
- Given a labeled AV dataset, you first divide it into a query set and a reference set.
- Then you export both sets and run mislabel detection on them. You can check out the results, get a detailed view of some images, and configure the mislabel detection settings as desired.
- After checking the mislabel detection report, you can choose classes with a high likelihood of being mislabeled, apply new tags, and assign them for re-labeling.
Here are the main benefits of this workflow:
- You can reduce manual review and QA time, thereby saving a lot of money.
- You get a higher-quality dataset with fewer mislabels, thereby reducing the chance of bad model performance caused by mislabeled data.
Conclusion
Data is the most important component of any ML workflow that impacts the performance, fairness, robustness, and scalability of the eventual ML system. Unfortunately, working on data has traditionally been underlooked in both academia and industry, even though this work can require multiple personas (data collectors, data labelers, data engineers, etc.) and involve multiple teams (business, operations, legal, engineering, etc.).
At Superb AI, we specialize in reinventing how teams of all sizes label, manage, curate, and deliver training data for computer vision projects. As we continue to expand our capabilities, you’ll find a well-integrated combination of features that humanizes the data labeling process, automates data preparation at scale, and makes building and iterating on datasets quick, systematic, and repeatable. Schedule a call with our sales team today to get started. You can also subscribe to our company newsletter to stay updated on the latest computer vision news and product releases.
Note: Thanks to Superb AI for the thought leadership/ Educational article above. Superb AI has supported and sponsored this Content.
![]()
James Le runs Data Relations and Partnerships at Superb AI, an ML data management platform for computer vision use cases. Outside work, he writes data-centric blog posts, hosts a data-focused podcast, and organizes in-person events for the data & ML community.
Credit: Source link
Comments are closed.