Meet DifFace: A Novel Deep-Learning Diffused Model For Blind Face Restoration

Looking at really old photos, we can notice a clear difference from the ones produced by recent cameras. Blurry or pixelled photos were once pretty common. With the ideal of photo quality being related to details, definition, and sharpness, it is easy to understand why old photos can not deliver these quality standards. Indeed, we notice the huge difference between images produced by old and recent cameras. However, such problems often recur in recent pictures as well, depending on the camera shutter or environment settings.
What if you had or had taken blurred portraits whose details are pretty hard to distinguish? Have you ever wondered if it is possible and, if yes, how to transform these blurry pictures into sharp, high-definition, and high-detailed ones?
Blind face restoration (BFR) is what we need. It refers to the task of reconstructing a clear and faithful image of a person’s face from a degraded (for instance, noise or blurred) or low-quality input image. This challenging problem has attracted significant attention in image processing and computer vision due to its wide range of practical applications, such as surveillance, biometrics, and social media.
In recent years, deep learning methods have emerged as a promising approach for blind face restoration. These methods, based on artificial neural networks, have demonstrated impressive results on various benchmarks and can learn complex mappings from data without needing hand-crafted features or explicit modeling of the degradation process.
These techniques focus on many complex metrics, formulations, and parameters to improve the restoration quality. The L1 training loss is commonly used to ensure fidelity. Recent BFR methods introduce adversarial loss and perceptual loss to achieve more realistic results. Some other existing approaches also exploit face-specific priors, e.g., face landmarks, facial components, and generative priors. Considering so many constraints together makes the training unnecessarily complicated, often requiring laborious hyper-parameter tuning to make a trade-off among these constraints. Worse, the notorious instability of adversarial loss makes the training more challenging.
A novel method named DifFace has been developed to overcome these issues. It can cope with unseen and complex degradations more gracefully than state-of-the-art techniques without complicated loss designs. The main key is the posterior distribution from the input low-quality (LQ) image to its high-quality (HQ) counterpart. Specifically, a transition distribution is exploited from the LQ image to the intermediate state of a pre-trained diffusion model and then gradually transmitted from this intermediate state to the HQ target by recursively applying a pre-trained diffusion model.
The picture below illustrates the proposed framework.
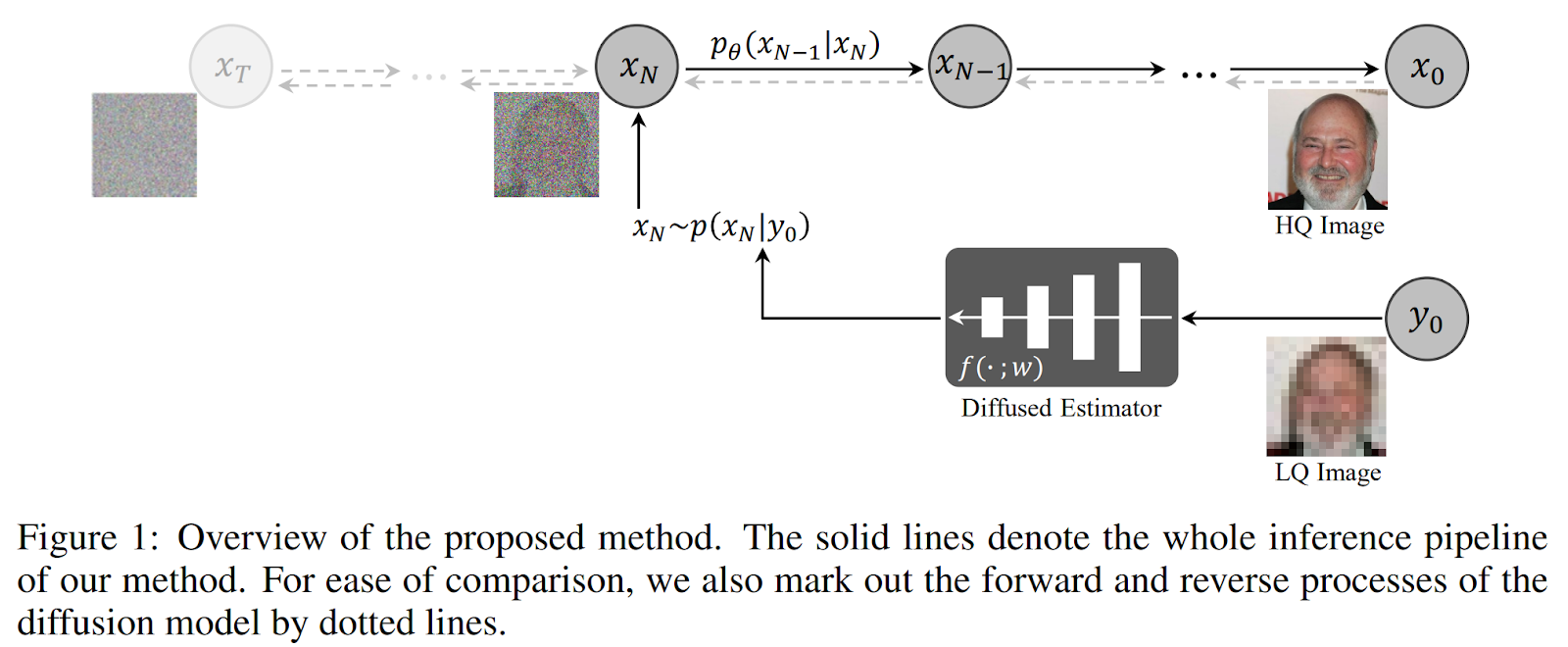
The inference involves an intermediate diffused variable xN (with N<T) from the LQ image y0. This intermediate state is obtained through a so-called diffused estimator. It represents a neural network architecture developed to estimate the diffusion step xN from the input image y0. From this intermediate state, the desirable x0 is then inferred. Doing so brings several advantages. Firstly, this approach is more efficient than the full reverse diffusion process from xT to x0, since a pre-trained diffusion model can be exploited (from xN to x0). Secondly, there is no need to retrain the diffusion model from scratch. In addition, this method does not require multiple constraints in training and yet is capable of dealing with unknown and complex degradations.

The outcomes and comparison for DifFace and other state-of-the-art approaches are presented in the figure below.
Looking at the details of the generated images, it is evident that DifFace produces high-quality, high-detailed, and sharp pictures from low-quality, blurred, degraded input images outperforming state-of-the-art techniques.
This was the summary of DifFace, a novel framework to address the Blind Face Restoration problem. If you are interested, you can find more information in the links below.
Check out the Paper and Github. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.