Google AI Introduces Confident Adaptive Language Modeling (CALM) For 3x Faster Text Generation With Language Models (LMs)
Latest innovations in the field of Artificial Intelligence have allowed us to define intelligent systems with a greater and more articulate understanding of language than ever before. There has been an exponentially increasing performance by Large Language Models (LLMs) like GPT-3, T5, PaLM, etc. These models have started imitating humans by learning to read, summarize and generate textual data. It has been put forward by some in-depth studies that an LLM performs well if its size is big. What an LLM model is capable of can be determined by surging its scale. However, when an LLM is trained on huge training data, it sometimes becomes expensive and less adequate for usage.
What is Confident Adaptive Language Modelling?
To fasten up the process of text generation and make it less costly, Google AI Researchers Introduce ‘Confident Adaptive Language Modelling’ (CALM). CALM was discussed in the Hybrid conference, NeurIPS 2022, and has claimed to speed up the text generation process by three times. Textual data consists of different types of sentences. In some sentences, the prediction of the next word, i.e., text generation, may be very insignificant, while it might be tough in some cases. CALM introduces the concept of granting comparatively additional computational resources in case the text prediction that needs to be made is extensive and difficult. Thus, unlike a standard LLM model in which the computational power for all kinds of predictions is the same, the newly flourishing CALM method accelerates the process of generating text and, thereby, retains the quality of the output. It basically functions by allotting individual computing volumes for each input and generation timestamp.
The team, in their recently published paper Confident Adaptive Language Modelling, have stated their contributions which are as follows –
- Confident Adaptive Language Modelling is a framework responsible for a notably remarkable acceleration in text generation.
- The effectiveness of CALM has been illustrated on three varied text generation datasets.
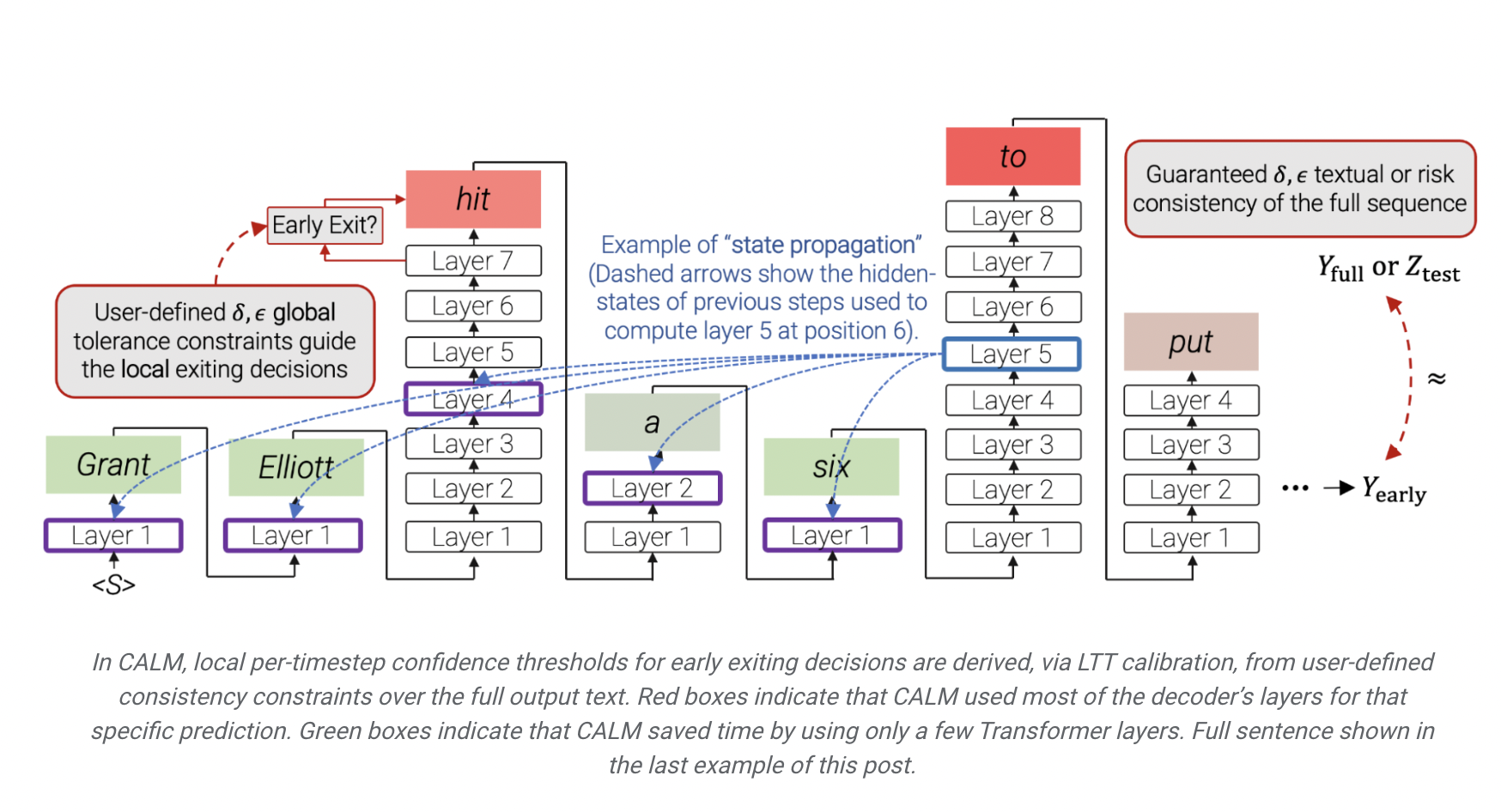
- The team has used the concept of early exiting, which drives an effective class of confidence measures and threshold functions used by CALM.
Datasets used
The team has performed a thorough analysis of three datasets, namely –
- Text summarization dataset – CNN/DM (https://github.com/abisee/cnn-dailymail)
- Machine translation dataset – WMT (https://www.statmt.org/wmt15/translation-task.html)
- The Stanford Question Answering dataset – SQuAD 2.0 (https://rajpurkar.github.io/SQuAD-explorer/)
Working
To research and experiment on the datasets mentioned above, the group used an eight-layered encoder-decoder T5 architecture. Firstly, the encoder takes in the text input and changes it into a dense representation. This is followed by the decoder, which gives an output prediction one after the other. The transformer layers used for the development include attention and feedforward modules along with matrix multiplication. CALM predicts the next word before all decoder layers are finished, thus skipping computations for a few predictions.
The model was measured upon the calculated values of the three confidence measures – the SoftMax score, state propagation, and the early-exit classifier.
It has been stated that a standard technique uses the same number of layers for making predictions that may vary from 3 to 5. Local Oracle Confidence Measure, used for making predictions in CALM, portrays a satisfactory performance by only utilizing 1.5 decoder layers.
Conclusion
Consequently, Confident Adaptive Language Modelling is a breakthrough in terms of Language Modeling. It is capable of maintaining high performance, producing a high-quality output along with an increase in the speed of text generation. It even diminishes the heavy task of model computation and is, beyond any doubt, a very effective solution.
Check out the Paper, Code, and Reference Article. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.