Microsoft AI Research Introduces E5 Model Trained in a Contrastive Manner with Weak Supervision Signals
In the latest research, Microsoft researchers developed an E5 model designed for general-purpose text embeddings. Text embeddings, which are arbitrary-length text representations in the form of low-dimensional vectors, are crucial to many NLP applications, including large-scale retrieval. With text embeddings, it is possible to overcome the challenge of lexical mismatches in NLP tasks. It also provides efficient matching and retrieval between texts.
There are many pre-trained models like BERT etc., but they are not ideal for text matching and retrievals since these tasks need single vector embedding for better efficiency and versatility so its interface can be used across downstream applications. There are many existing fine-tuned pre-trained models, such as GTR and Sentence-T5, designed for the same purpose. Even though they have the unlimited quantity, a compromise is made with quality resulting in poor performance and, thus, failing the benchmark.
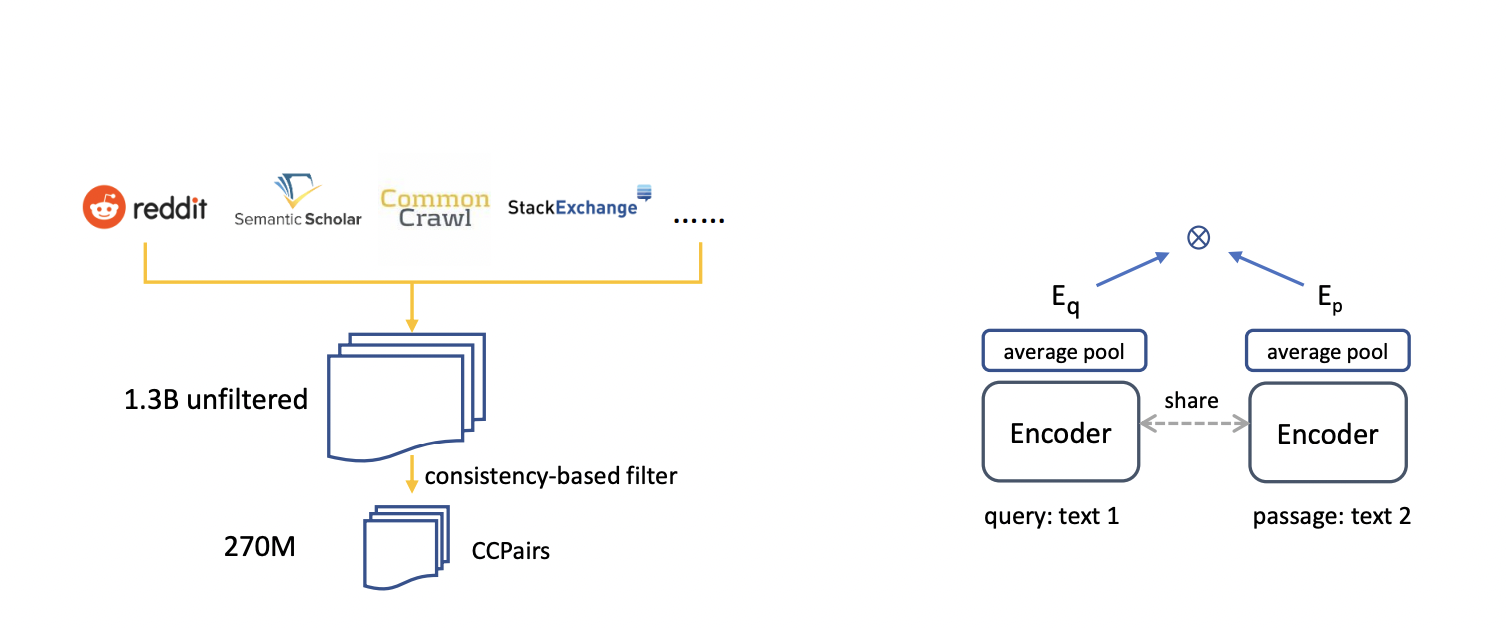
E5 stands for EmbEddings from bidirEctional Encoder rEpresentations. . So in E5, they train E5 embeddings from CCPairs in a contrastive manner, a curated web-scale text pair dataset featuring heterogeneous training signals, as opposed to relying on sparsely labeled data or low-quality synthetic text pairings. CCPairs stands for Colossal Clean Text Pairs, and a data set is formed with diverse and high quality and quantity of CCPairs for training text embeddings. To further enhance data quality, they used a novel consistency-based filtering strategy, and they eventually wound up with about 270M text pairings for contrastive pretraining. Further, training it with labeled data will lead to increase in performance and the addition of human knowledge to the dataset. Supervised fine-tuning helped in consistent performance gains.
Recently, the MTEB Benchmark was put forth for use in evaluating huge text embedding assignments. Even though bitext mining datasets have been incorporated into MTEB. In this study, they assess the 56 datasets from 6 categories of the English subsets.
The approach’s appropriateness for both zero-shot and fine-tuned settings is validated by the great transferability of the produced high-quality text embeddings across a broad variety of jobs without the need for parameter adjusting. E5 is the first model ever to outperform the robust BM25 baseline in a zero-shot configuration on the BEIR retrieval benchmark. In a setup optimized for the MTEB test, E5 beat the state-of-the-art embedding model with 40 times more parameters.

Overall, the study demonstrates that E5 text embeddings can be trained contrastively using only unlabeled text pairs, that the approach offers strong, off-the-shelf performance on tasks requiring single-vector text representations, and that it produces superior fine-tuned performance on downstream tasks.
E5 has established better efficiency and versatility which was an unexplored territory in the field of text embedding models. Even though it is a slight modification from the previous methods, its performance has improved significantly from the rest of the models.
Check out the Paper and Code. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
I am an undergraduate student at IIIT HYDERABAD pursuing Btech in computer science and MS in Computational Humanities. I am interested in Machine and Data learning. I am also actively involved in research on AI solutions for road safety.
Credit: Source link
Comments are closed.