Meet NeROIC: An Efficient Artificial Intelligence (AI) Framework For Object Acquisition Of Images In The Wild
Machine learning is becoming increasingly important in the world of technology. As computers become more advanced and powerful, they can process data faster and more accurately than ever. Recent developments in machine learning have increased interest in using coordinate-based neural networks that parametrize the physical properties of scenes or objects across space and time to solve visual computing problems. These methods, known as neural fields, have been used successfully for synthesizing 3D shapes, human body animation, 3D reconstruction, and pose estimation.
The Neural Radiance Fields (NeRF) model, which learns to represent the local opacity and view-dependent radiance of a static scene from sparse calibrated images, is one of the most recent works using neural fields. This model enables high-quality novel view synthesis (NVS). While NeRF’s quality and capabilities have greatly improved (e.g., concerning moving or non-rigid content), there are still a few non-trivial requirements that must be met. For example, in order to synthesize novel views of an object, the background and lighting conditions must be observed and fixed, and the multi-view images or video sequences must be recorded in a single session.
For instance, countless images featuring the same items, such as furniture, toys, or vehicles, can be found online. The high-fidelity structure and appearance of these objects must be captured while isolating them from their surroundings. Segmenting such objects is a prerequisite for applications like digitizing an object from the images and blending it into a new background. However, the backgrounds, illumination settings, and camera settings used to capture individual photos of the objects in these collections are frequently highly variable. Thus, object digitization techniques created for data from controlled environments are inappropriate for this type of in-the-wild setup.
A novel approach to the Neural Rendering of objects from Online Image Collections (NeROIC) has been proposed to address the abovementioned issues. The method is based on NeRFs and has several essential components that allow high-fidelity capture from sparse images taken in wildly different circumstances, as is frequently seen in online images. Many photos, even featuring the same objects, can be generally taken in various lighting, camera, environment, and pose conditions, which in most cases cause NeRF-based approaches to struggle.
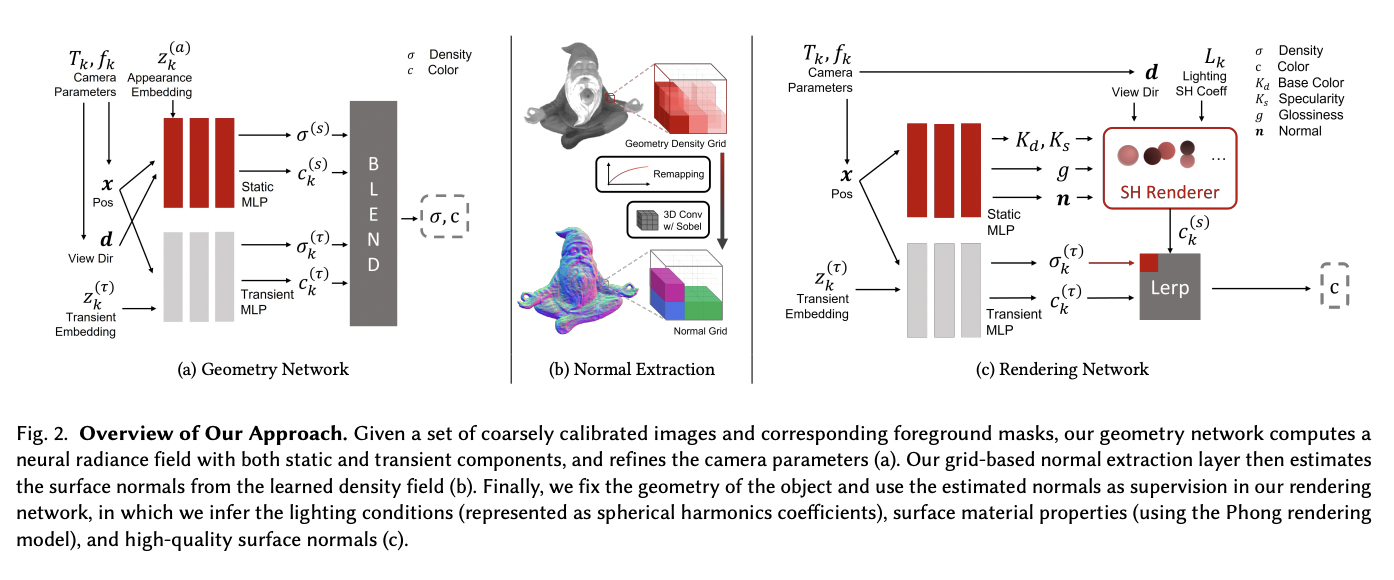
An overview of the proposed technique is depicted below.

A sparse collection of photos showing an item (or variations of the same object) in various settings and a set of foreground masks defining the object’s area constitute the inputs. The model calculates the object’s geometry in the first step by learning a density field that shows where there is physical content. Two MLP functions are used in this step to separately account for static and transient radiance data and to provide image-based supervision. Camera parameters and posture predictions are further calculated to refine the coarse input.
The acquired geometry is finalized in the second step. Here the surface normals of the object are extracted, and lighting parameters are adjusted to re-render the object under various lighting scenarios. The surface normals are then utilized as supervision in the final step.
The rendering network shares the same structure as the first stage on most components, except for the static color prediction branch. In this case, a 4-layer MLP structure is designed to generate the final surface normals, base color, specularity, and glossiness.
Some results of the proposed approach are available below in the figure.

This was the summary of NeROIC, an efficient framework for object acquisition of images in the wild. If you are interested, you can find more information in the links below.
Check out the Paper, Code, and Project. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.