Meet ReCo: An AI Extension for Diffusion Models to Enable Region Control
Large-scale text-to-image models, looking at you Stable Diffusion, have dominated the machine learning space in recent months. They have shown extraordinary generation performance in different settings and provided us with visuals that we never thought were possible before.
Text-to-image generation models try to generate realistic images with an input text prompt describing what they should look like. For example, if you ask it to generate “Homer Simpson Walking on the Moon,” you would probably get a pleasant-looking image with mostly correct details. This huge success of generation models in recent years is mainly thanks to the large-scale datasets and models used.
As good as they sound, the diffusion models can still be considered early-stage models as they lack some properties that should be addressed in the upcoming years.
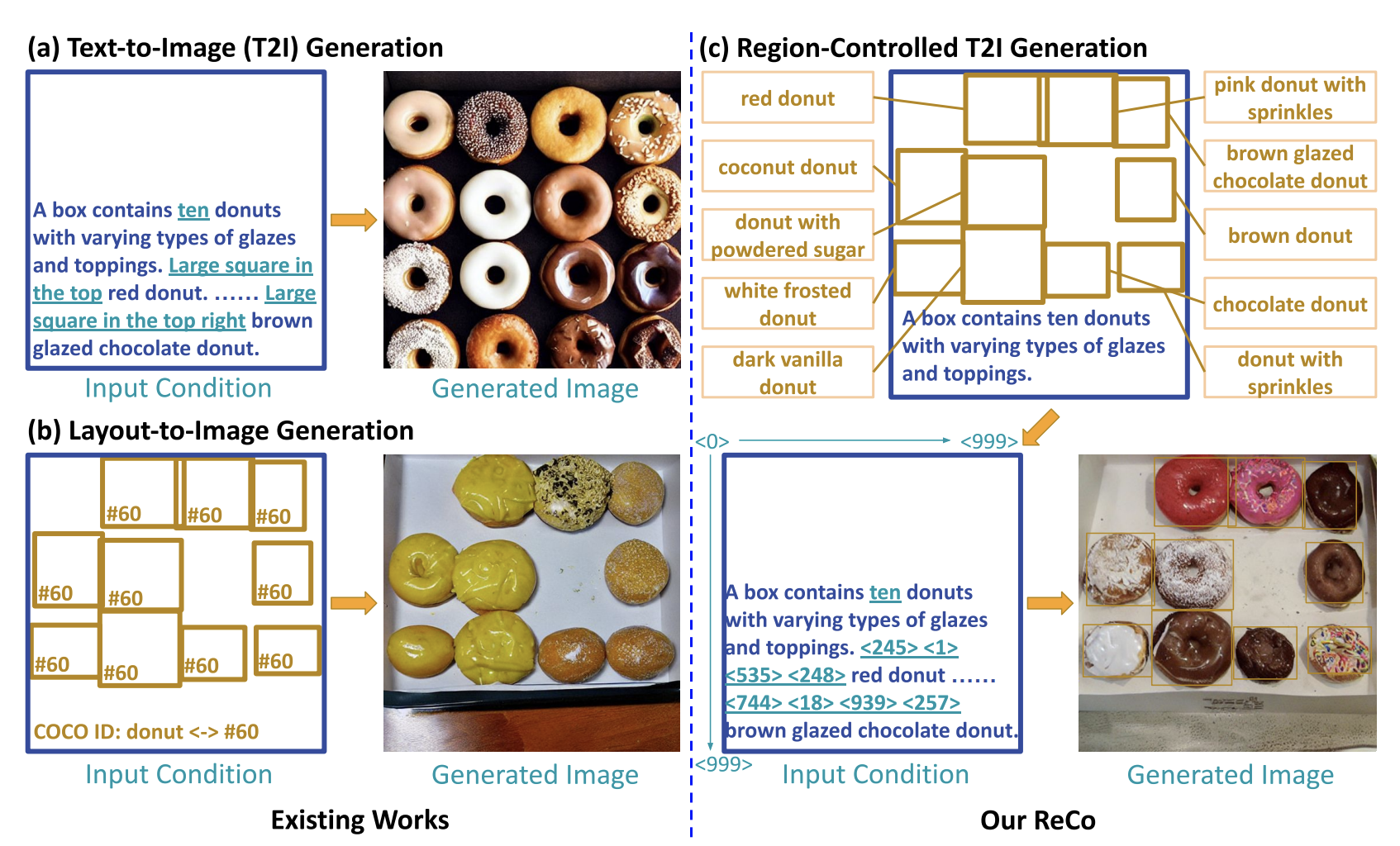
First, the text-query input limits the control of the output image. Specifically, it is difficult to precisely define what you want in which location on the output image. If you want to draw certain objects in certain locations, like a donut in the top-left corner, existing models can struggle to do so.
Second, when the input text query is long and somehow complicated, existing models overlook certain details and just go with the prior information they learned during the training phase. When we combine these two issues, it becomes problematic to region-control the images generated by existing models.
Nowadays, when you want to get the desired image, you need to try a large number of paraphrased queries and pick the output closest to your desired image. You probably heard about “prompt engineering,” and this is the name of the process. It is time-consuming, and there is no guarantee that it will produce the desired image for you.
So, now we know we have a problem with the existing text–to-image models. But we are not here to talk about the problems, are we? Let me introduce you to ReCO, the text-to-image model customization that enables you to generate precisely controlled output images.
Region-controlled text-to-image models are closely related to the layout-to-image problem. These models take object-bounding boxes with labels as inputs and generate the desired image. However, despite their promising result in region control, their limited label dictionary makes it challenging for them to understand freeform text inputs.
Instead of following the layout-to-image approach, which models text and objects separately, ReCO combines these two input conditions and models them together. They call this approach a “Region-controlled text-to-image” problem. This way, two input conditions, text, and region, are combined seamlessly.
ReCO is an extension of existing text-to-image models. It enables pre-trained models to understand spatial coordinate inputs. The core idea is to introduce an extra set of input position tokens to indicate the spatial positions. These position tokens are embedded into the image by dividing it into equally sized regions. Then, each token can be embedded into the nearest region.
ReCO’s position tokens provide for the accurate specification of open-ended regional descriptions on any area of an image, creating a useful new text input interface with region control.
Check out the Paper. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.