Meet PointAvatar: An Artificial Intelligence (AI) Method That Creates Deformable Point-Based Head Avatars From Videos

Avatars uniquely created in 3D are essential elements of the metaverse and beyond. Avatar creation software should make it simple to collect data, compute it quickly, and render a 3D image of the photorealistic user, animates, and can be lit differently. Unfortunately, current methods need to be revised to fulfill these demands. Recent techniques for generating 3D avatars from films use implicit neural representations or 3D morphable models (3DMMs). The latter may readily simulate people with intricate haircuts or spectacles since template meshes have a-priori-defined topologies and are only capable of surface-like geometries. The former, however, are efficient rasterizers and intrinsically generalize to unseen deformations. Recently, 3D head modeling has also been done using implicit neural representations.
However, as drawing a single pixel necessitates querying several places along the camera ray, they are far less effective in training and rendering than 3DMM-based approaches to catching hair strands and spectacles. Additionally, it is difficult to alter implicit representations in a generalizable way, forcing existing methods to switch to an ineffective root-finding loop, severely affecting training and testing times. To solve these problems, they provide PointAvatar, a unique avatar representation that learns a continuous deformation field for animation and employs point clouds to describe canonical geometry. To be more precise, they enhance an orientated point cloud to describe a subject’s geometry in canonical space.
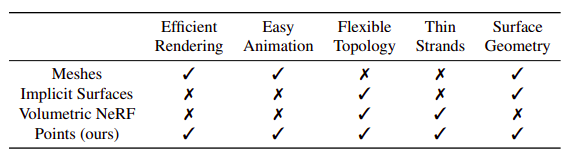
Table 1: Since PointAvatar renders and deforms effectively, it allows for the simple rendering of whole pictures during training. It can also work with thin, flexible materials and recreate accurate surface normals in regions that resemble surfaces, such as the skin.
In Table 1, they list the benefits of their point-based representation. Given the expression and pose parameters of a pretrained 3DMM, the learned deformation field translates the canonical points to the deformed space with learned blendshapes and skinning weights for animation. Their point-based format renders more effectively than implicit representations when using a common differentiable rasterizer. Additionally, they are easily distorted by utilizing tried-and-true methods like skinning. Points are a great deal more adaptable and flexible than meshes. They can depict complex volume-like objects like fluffy hair in addition to being able to adapt the topology to mimic accessories like spectacles. Their approach’s ability to detangle lighting effects is one of its advantages.
They separate the transparent color into the intrinsic albedo and the normal-dependent shading based on a monocular video shot under general illumination (see Fig. 1). Owing to the discrete structure of points, it is difficult and expensive to compute normals properly from point clouds, and the quality can quickly decrease due to noise and inadequate or irregular sampling. Therefore, they provide two methods for (a) reliably and precisely obtaining normals from canonical learned points and (b) transforming the point normals with the non-rigid surface deformation while maintaining geometrical features. In the first case, they take advantage of the MLPs’ low-frequency bias and estimate the normals by fitting a smooth signed distance function (SDF) to the points; in the second case, they take advantage of the deformation mapping’s continuity and transform the normals analytically using the deformation’s Jacobian. The two methods provide high-quality normal estimation, propagating the numerous geometric signals in coloring to enhance the point geometry. PointAvatar may be relit and rendered in new scenes with disentangled albedo and specific normal directions.
The suggested representation combines the benefits of well-known mesh and implicit models. It outperforms both in many difficult cases, as shown using numerous films shot with DSLR, smartphone, laptop, or other cameras or downloaded from the internet. In conclusion, their contributions consist of the following:
1. They suggest a novel representation for 3D animatable avatars based on an explicit canonical point cloud and continuous deformation, which demonstrates state-of-the-art photo-realism while being significantly more effective than existing implicit 3D avatar methods
2. They disentangle the RGB colour into a pose-agnostic albedo and a pose-dependent shading component, enabling relighting in novel scenes
3. They demonstrate the benefit of their methods on a variety of subjects captured using various capture
The source code will be made accessible on GitHub for analysis soon.
Check out the Paper and Project. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.