Meet Rodin: A Novel Artificial Intelligence (AI) Framework To Generate 3D Digital Avatars From Various Input Sources

Generative models are becoming the de-facto solution for many challenging tasks in computer science. They represent one of the most promising ways to analyze and synthesize visual data. Stable Diffusion is the best-known generative model for producing beautiful and realistic images from a complex input prompt. The architecture is based on Diffusion Models (DMs), which have shown phenomenal generative power for images and videos. The rapid advancements in diffusion and generative modeling are fueling a revolution in 2D content creation. The mantra is quite simple: “If you can describe it, you can visualize it.” or better, “if you can describe it, the model can paint it for you.” It is indeed incredible what generative models are capable of.
While 2D content was shown to be a stress test for DMs, 3D content poses several challenges due to but not limited to the additional dimension. Generating 3D content, such as avatars, with the same quality as 2D content is a hard task given the memory and processing costs, which can be prohibitive for producing the rich details required for high-quality avatars.
With technology pushing the use of digital avatars in movies, games, metaverse, and the 3D industry, allowing anyone to create a digital avatar can be beneficial. That is the motivation driving the development of this work.
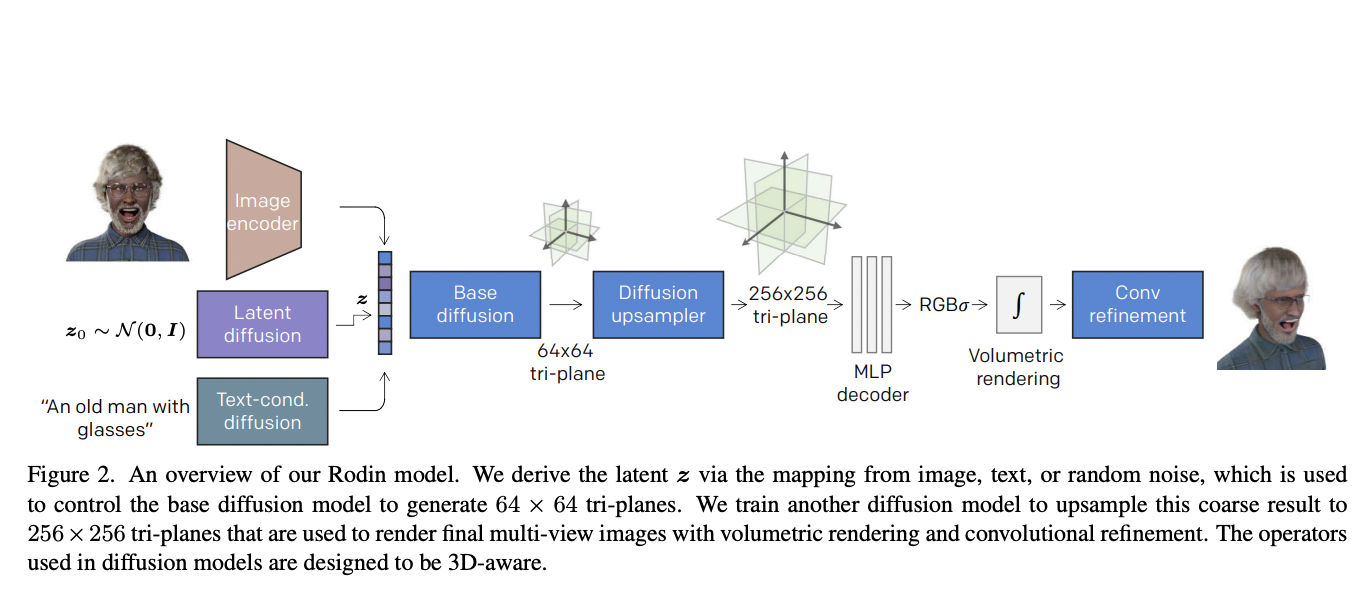
The authors propose the Roll-out diffusion network (Rodin) to address the issue of creating a digital avatar. An overview of the model is given in the figure below.
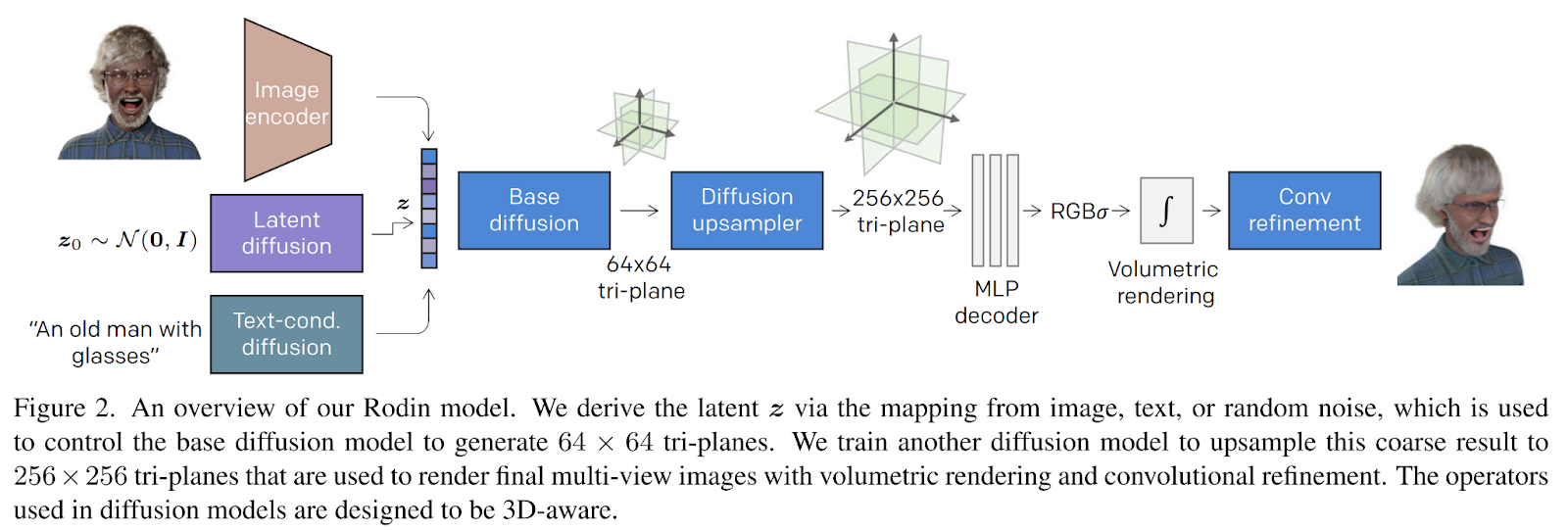

The input to the model can be an image, random noise, or a text description of the desired avatar. The latent vector z is subsequently derived from the given input and employed in the diffusion. The diffusion process consists of several noise-denoise steps. Firstly random noise is added to the starting state or image and denoised to obtain a much sharper image.
The difference here lies in the 3D nature of the desired content. The diffusion process runs as usual, but instead of targeting a 2D image, the diffusion model generates the coarse geometry of the avatar, followed by a diffusion upsampler for detail synthesis.
Computational and memory efficiency is one of the targets of this work. To achieve this, the authors exploited the tri-plane (three axes) representation of a neural radiance field, which, compared to voxel grids, offers a considerably smaller memory footprint without sacrificing the expressivity.
Another diffusion model is then trained to upsample the produced tri-plane representation to match the desired resolution. Finally, a lightweight MLP decoder consisting of 4 fully connected layers is exploited to generate an RGB volumetric image.
Some results are reported below.

Compared with the mentioned state-of-the-art approaches, Rodin provides the sharpest digital avatars. For the model, no artifacts are visible in the shared samples, contrary to the other techniques.
This was the summary of Rodin, a novel framework to easily generate 3D digital avatars from various input sources. If you are interested, you can find more information in the links below.
Check out the Paper. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.