This Lightweight Artificial Intelligence (AI) Model is a Robust Visual Object Tracker that Can Run on Mobile Devices
You probably remember a scene from a movie where we see lots of large screens in a dark room that are tracking cars, people, and objects. Then the antagonist walks in, watches the footage carefully and notices something, and shouts, “wait, I see something.” This method of drawing a box and tracking the movements of the same object/person/car is called visual tracking, and it is a highly active research field in computer vision.
Visual tracking is a crucial component of many applications, such as autonomous driving, surveillance, and robotics. The goal is to track the object that appeared in a certain frame, usually the first one, of the video in the upcoming frames. Occlusions, lightning changes, and other issues make finding the exact same object in different frames challenging. On the other hand, visual tracking is usually done at the edge devices. Those devices have limited computational power, as we are talking about consumer-grade computers or mobile devices. Visual tracking is a challenging task; however, having a robust visual tracking system is a prerequisite for multiple applications.
One approach to the visual tracking problem is to use deep learning techniques to train a model to recognize the object of interest in the video frames. The model can then predict the object’s location in subsequent frames, and the tracking algorithm can use this prediction to update the object’s position in the frame. Many different deep learning architectures approaches can be used for visual object tracking, but the recent advancement in Siamese networks has enabled significant progress.
Siamese network-based trackers can be trained offline in an end-to-end approach so that a single network can detect and track the object. This is a huge advantage over other approaches, especially in terms of complexity.
State-of-the-art visual tracking networks can achieve impressive performance when it comes to tracking the object, but they ignore the computational complexity that is required to run these methods. Therefore, taking them and applying them in edge devices where the computational power is limited is a challenging problem. The Siamese tracker architecture does not significantly increase inference time when a mobile-friendly backbone is used because the decoder or bounding box prediction modules do the majority of memory- and time-intensive activities. Therefore, designing a mobile-friendly visual tracking method remains an open challenge.
Moreover, in order to make a tracking algorithm robust to variations in an object’s appearance, such as changes in pose or lighting, it is important to include temporal information. This can be done by adding specialized branches to the model or implementing online learning modules. However, both of these approaches result in additional floating point operations, which can negatively impact the run-time performance of the tracker.
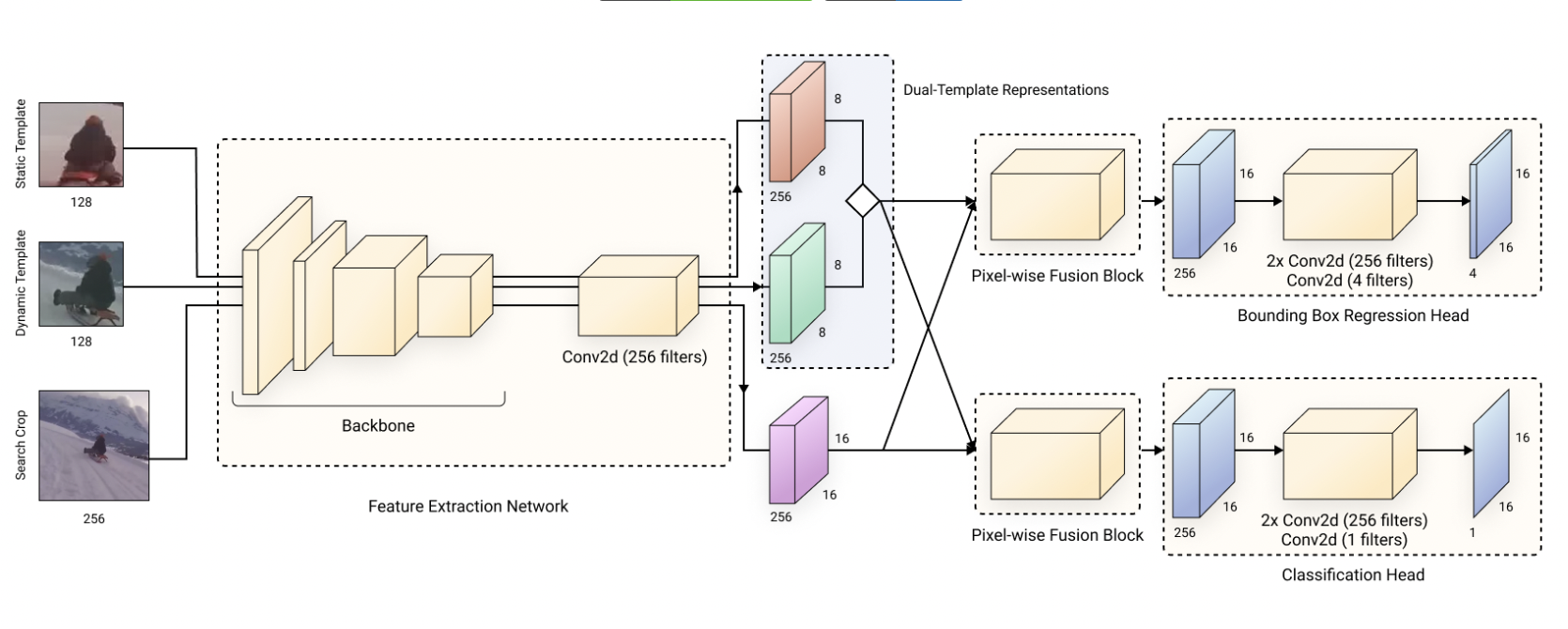
FEAR tracker is introduced to solve both of these problems. FEAR uses a single-parameter dual-template module which enables the tracking algorithm to learn about changes in the appearance of the object in real-time without increasing the complexity of the model. This helps to mitigate the memory constraints that have been a problem for some online learning modules. The module predicts how close the target object is to the center of the image, which enables candidates for the template image update.
In addition, an interpolation to blend the feature map of the online selected dynamic template image with the feature map of the original static template image in a way that can be learned by the model is used. This allows the model to adapt to changes in the appearance of the object during inference. FEAR uses an optimized neural network architecture that can be more than ten times faster than many current Siamese trackers. The resulting lightweight FEAR model can run at 205 FPS on an iPhone 11, which is a magnitude faster than existing models.
Check out the Paper and Github. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.