This AI Research Presents DisCoScene: A 3D-Aware Generative Model For High-Quality And Controllable Scene Synthesis
Synthesis of 3D images from a single view In generative modeling, 2D data has gained popularity. Recent methods like GRAF and Pi-GAN incorporate 3D inductive bias and enable geometry modeling and direct camera control by using neural radiance fields as the underlying representation. Although they excel at synthesizing single items (such as faces, animals, and vehicles), they need help with scene pictures that incorporate several objects with complicated backgrounds and non-trivial layouts. The complex spatial arrangement, wide variety, and mutual occlusion of the items provide huge obstacles beyond the scope of the object-level generative models. The creation of 3D-aware scene synthesis has recently received some attention. Despite the positive development, there are still important things that could be improved.
For instance, by describing the scene as a grid of local radiance fields and training on 2D observations from continuous camera trajectories, Generative Scene Networks (GSN) achieve large-scale scene synthesis. However, object-level editing is not practical due to spatial entanglement and the absence of explicit object definition. To facilitate object-level control, GIRAFFE, on the other hand, explicitly combines object-centric radiance fields. However, it performs badly on difficult datasets with numerous objects and diverse backdrops because of the need for appropriate spatial priors. The scene representation is an essential design consideration for achieving high-quality and regulated scene synthesis. Scaling up the generating capabilities and overcoming the aforementioned difficulties are both possible with a well-structured scene representation.
What steps would someone take to set up an apartment if given a furniture catalog and a space? Would people rather map out a general arrangement and then pay attention to each spot for the specific selection, or would they rather go about and dump items here and there? A blueprint outlining how each piece of furniture is arranged in the room makes it much easier to compose scenes. This viewpoint gives rise to their main motivation: a layout prior, an abstract object-oriented scene representation, might aid in learning from complex 2D data as a minimal supervision signal during training and enable user input during inference.
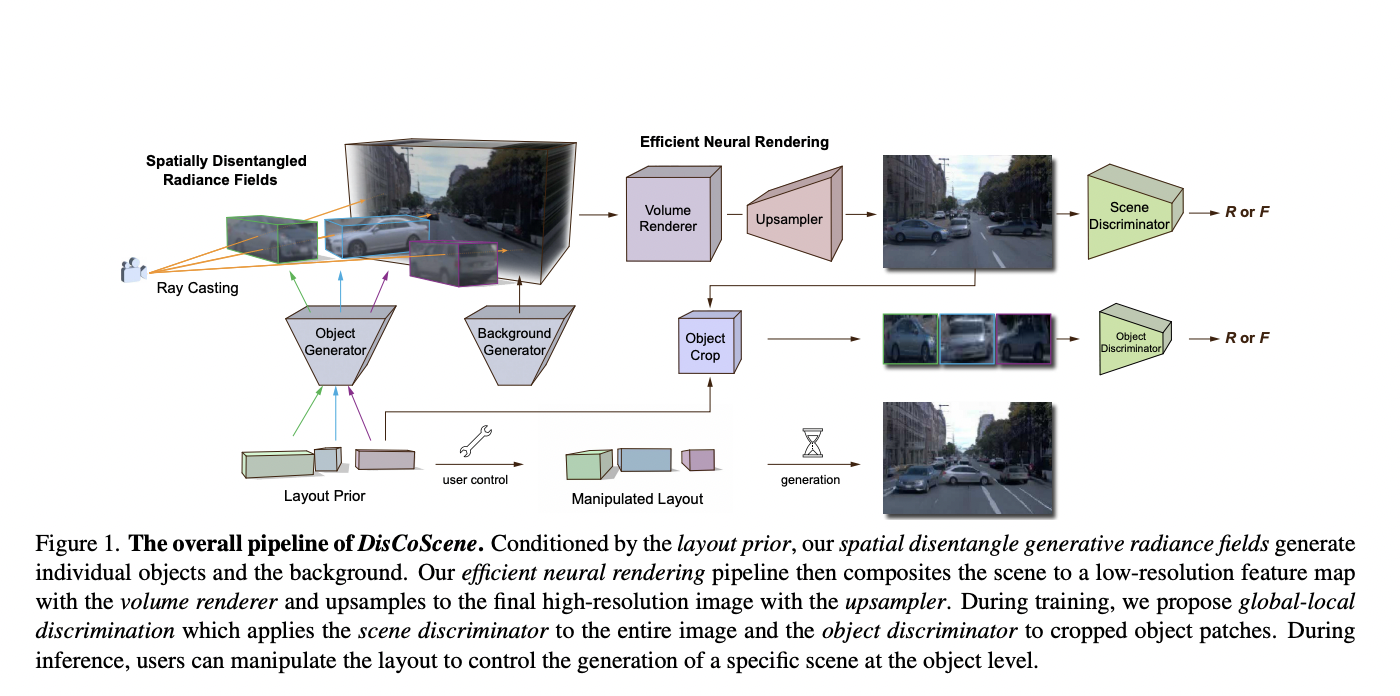
They define such a prior as a set of item bounding boxes without semantic annotation, which represents the spatial composition of objects in the scene and facilitates intuitive object-level editing to make such a prior simple to acquire and generalizable across many scenarios. In this study, they introduce DisCoScene, a unique 3D-aware generating model for complicated scenes. Their approach enables flexible user control of the camera and scene elements and high-quality scene synthesis on difficult datasets. Their model geographically separates the scene into compostable radiance fields that are shared in the same object-centric generative model, driven by the aforementioned layout prior.
They suggest global local discrimination, which pays attention to both the entire scene and individual items to impose spatial disentanglement between objects and against the backdrop, to make the greatest use of the prior as light supervision during training. Users may create and alter scenes once the model has been trained by directly managing the camera and arranging the bounding boxes for objects. Additionally, they provide a powerful rendering pipeline specifically designed for spatially-disentangled radiance fields, which considerably speeds up scene composition and object rendering during training and inference stages. On a variety of datasets, including both indoor and outdoor settings, their approach is assessed.
DisCoScene is compared to relevant works in the table below. It’s important to note that, to their knowledge, DisCoScene is the first technique to successfully generate high-quality 3Daware content on complex datasets like WAYMO while permitting interactive object manipulation. Qualitative and quantitative findings show that their approach delivers state-of-the-art performance in terms of generating quality and editing capabilities compared to established baselines. Code will be soon released on GitHub, and their website has the work illustrated in a nice way.
Check out the Paper, Code, and Project. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.